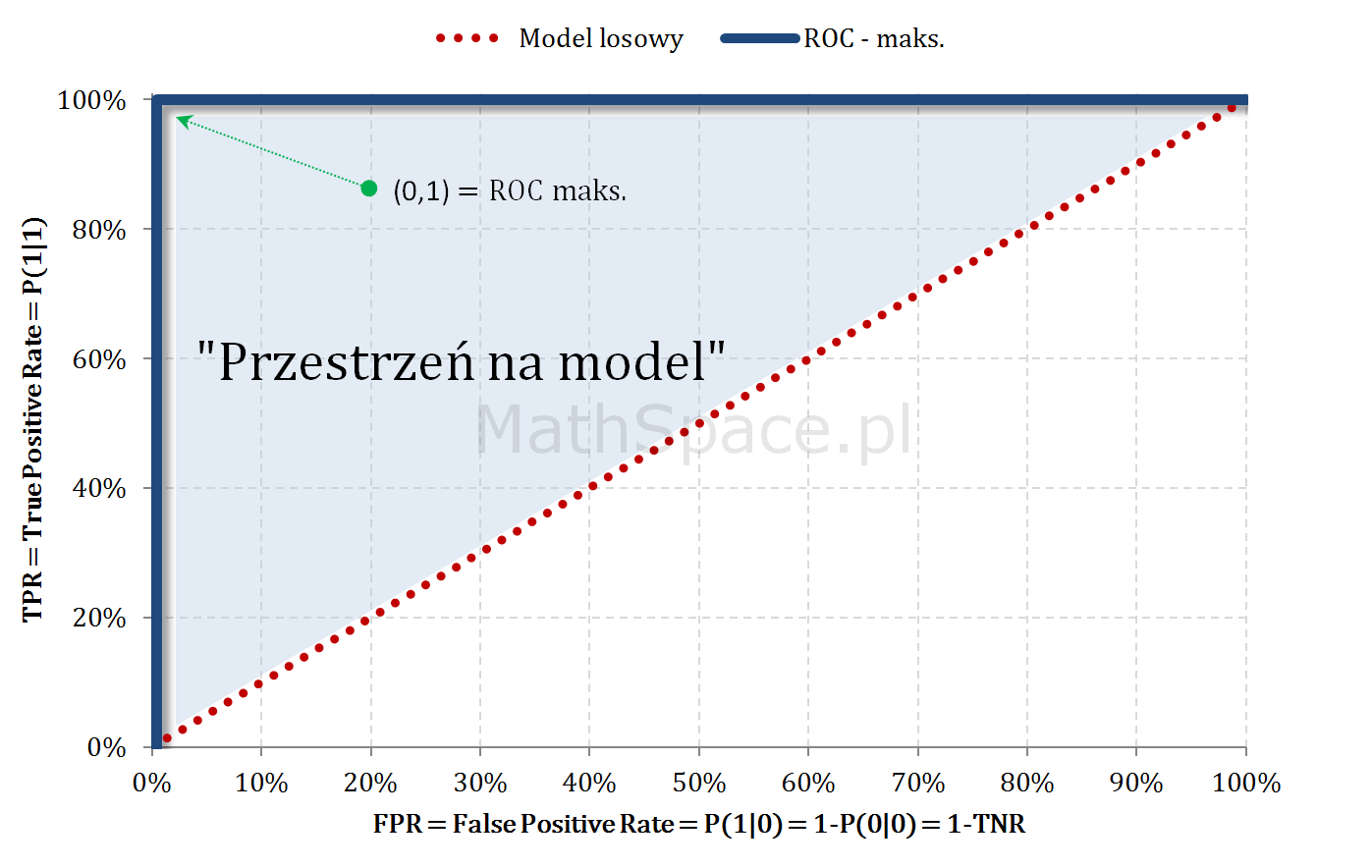
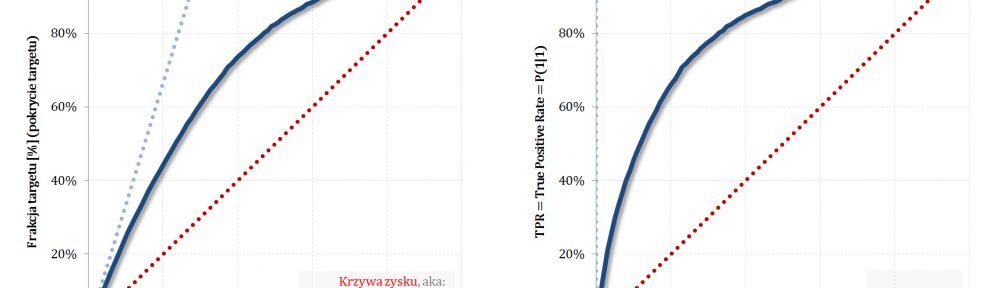
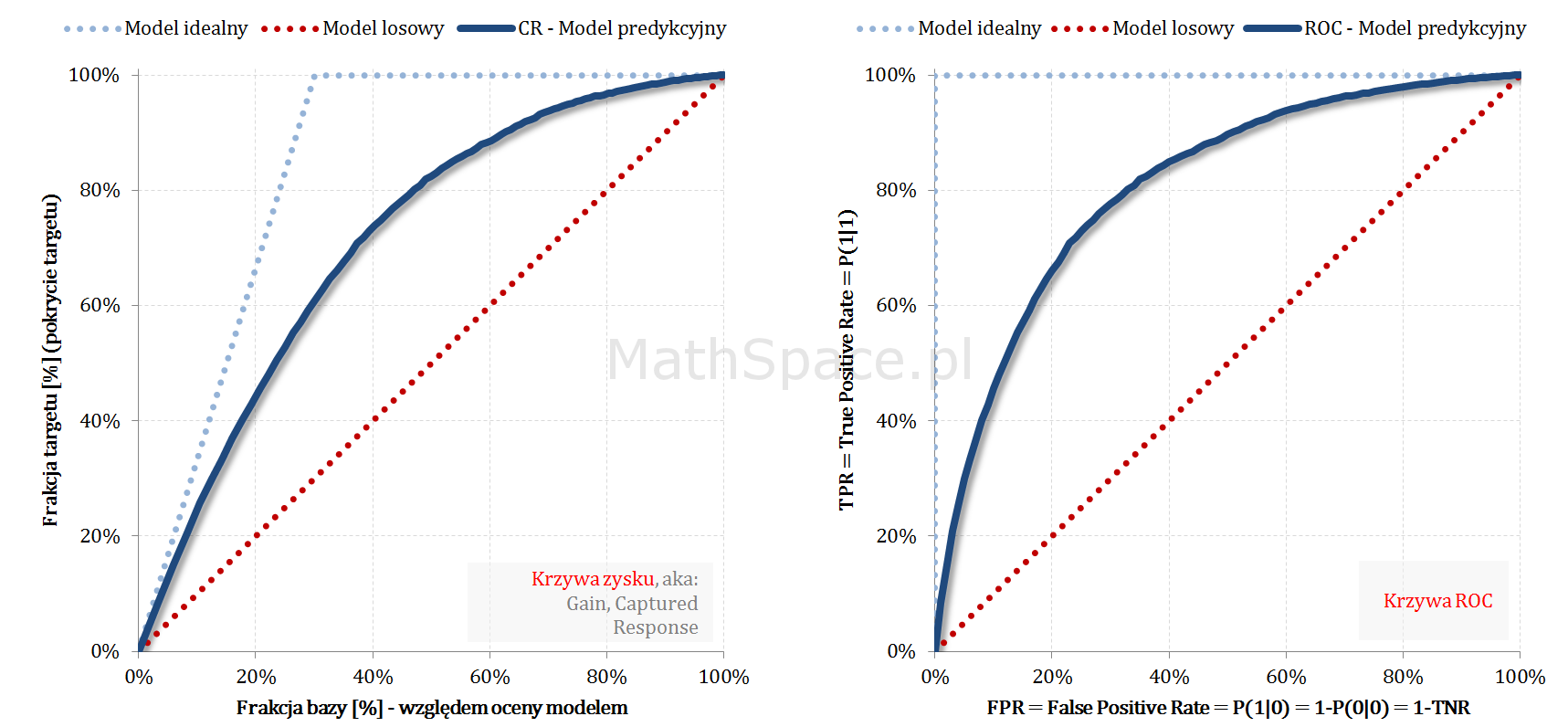
W części #8 cyklu „Ocena jakości klasyfikacji” pokazałem, że ROC i Captured Response to te same krzywe, które łączy proste przekształcenie liniowe. W bieżącym odcinku #11, należącym również do serii „Tips & Tricks na krzywych”, przedstawię zależność pomiędzy Captured Response i Lift w wariantach: nieskumulowanym i skumulowanym.
!!! Uwaga: dla uproszczenia – wszędzie tam, gdzie piszę kwantyl, mam na myśli jego rząd !!!
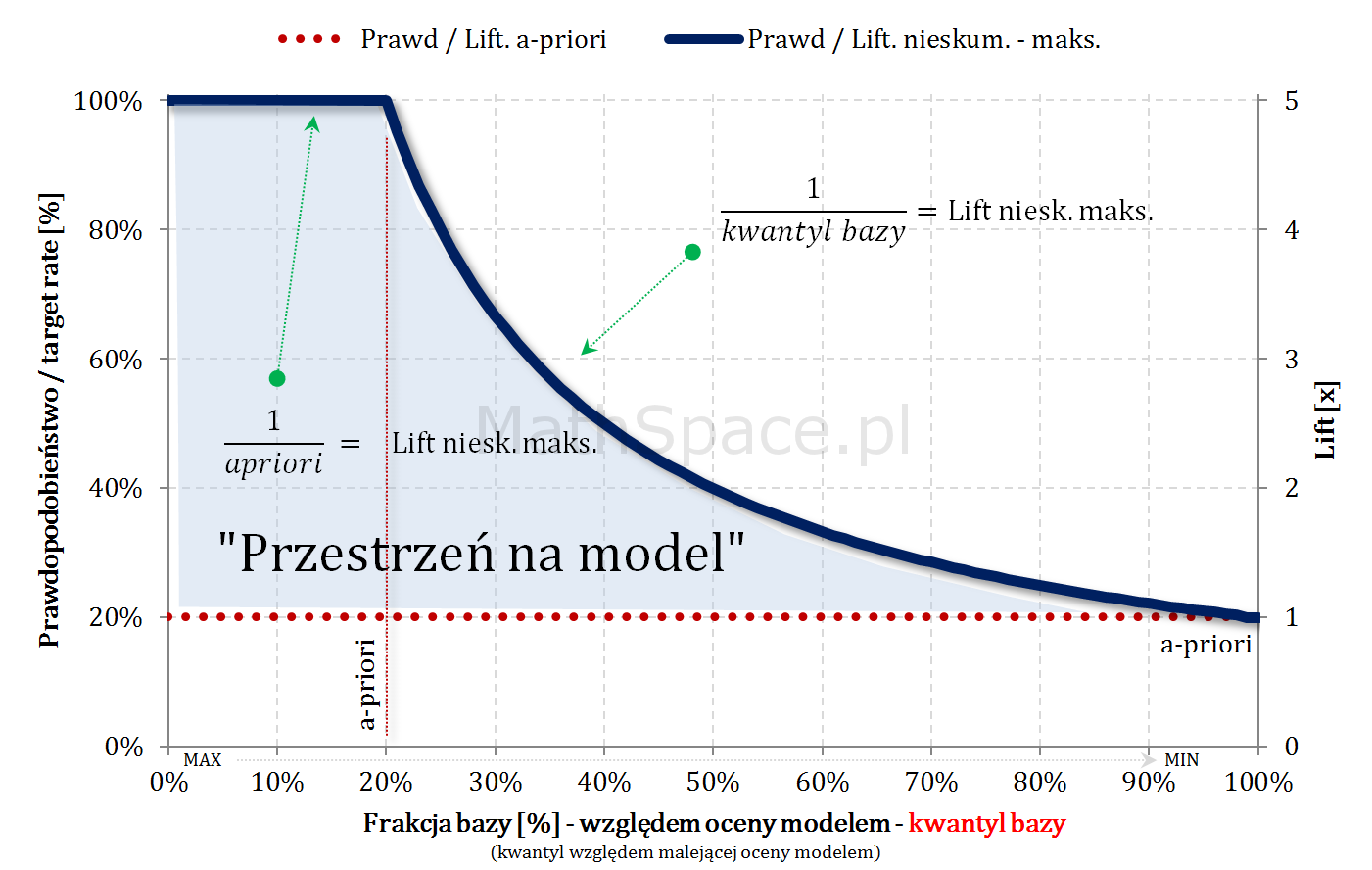
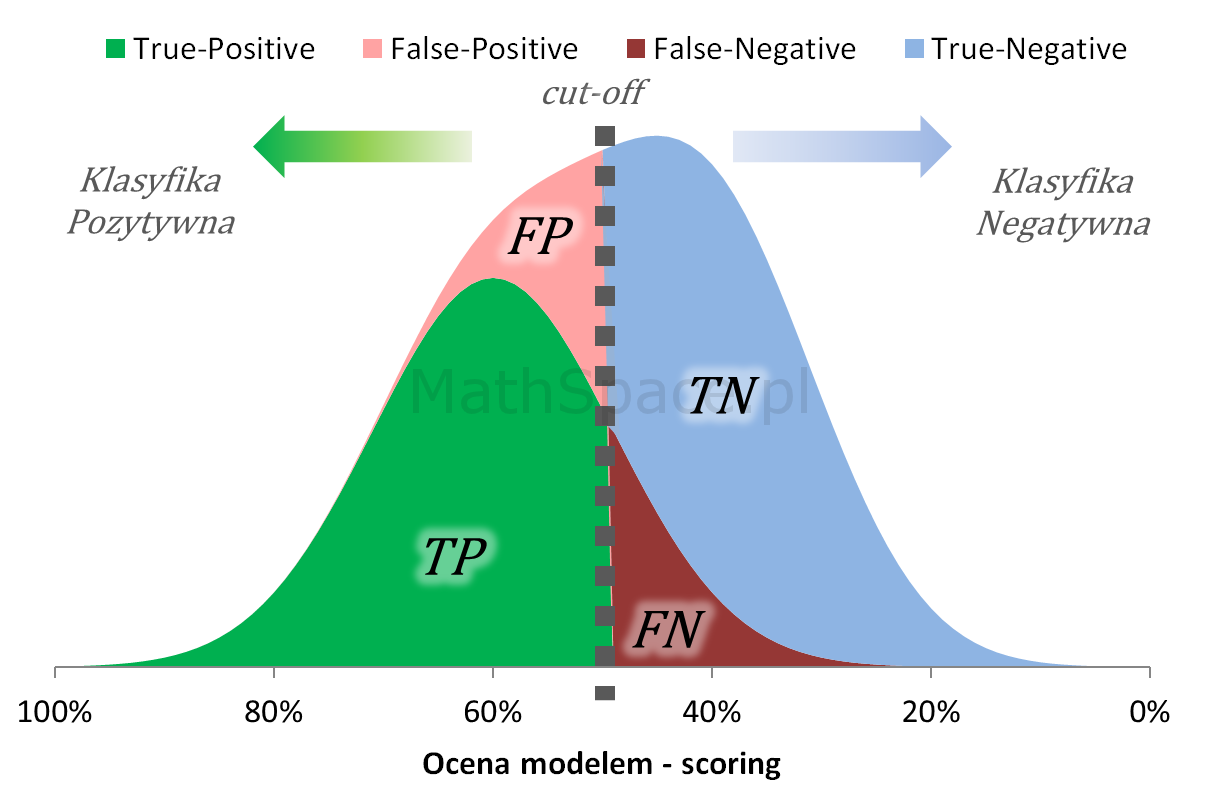
Pochodna z Captured Response to Lift nieskumulowany
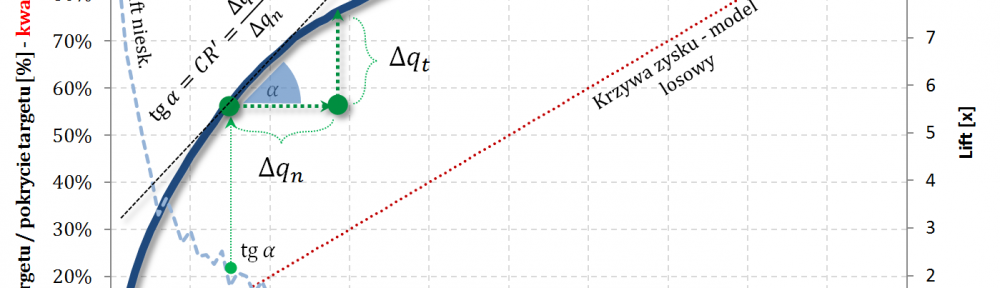
Oznaczamy:
- $N=N_1+N_0$ – liczba obiektów (np. klientów): total, z klasy „1”, z klasy”0″;
- $\Delta q_n$ – zmiana argumentu (przyrasta kwantyl bazy), czyli przyrost % populacji;
- $n=n_1+n_0$ – liczba obiektów składających się na przyrost $\Delta q_n$: total, z klasy „1”, z klasy”0″;
- $\Delta q_t$ – zmiana wartości funkcji (przyrasta kwantyl targetu), czyli przyrost frakcji targetu jako % całości targetu;
- $n_1$ – liczba klientów z klasy „1” składających się na przyrost $\Delta q_t$.
- $\Delta q_n=\frac{n}{N}$
- $\Delta q_t=\frac{n_1}{N_1}$
$$CR’=\frac{\Delta q_t}{\Delta q_n}$$
I wyprowadzamy 🙂
$$CR’=\frac{\Delta q_t}{\Delta q_n}=\frac{n_1}{N_1}\bigg/\frac{n}{N}=\frac{n_1}{N_1}\cdot\frac{N}{n}=\frac{n_1}{n}\cdot\frac{N}{N_1}=\frac{n_1}{n}\bigg/\frac{N_1}{N}$$
$$CR’=\frac{n_1}{n}\bigg/\frac{N_1}{N}=\frac{p(1|\Delta q_n)}{p(1)}=Lift.Niesk$$
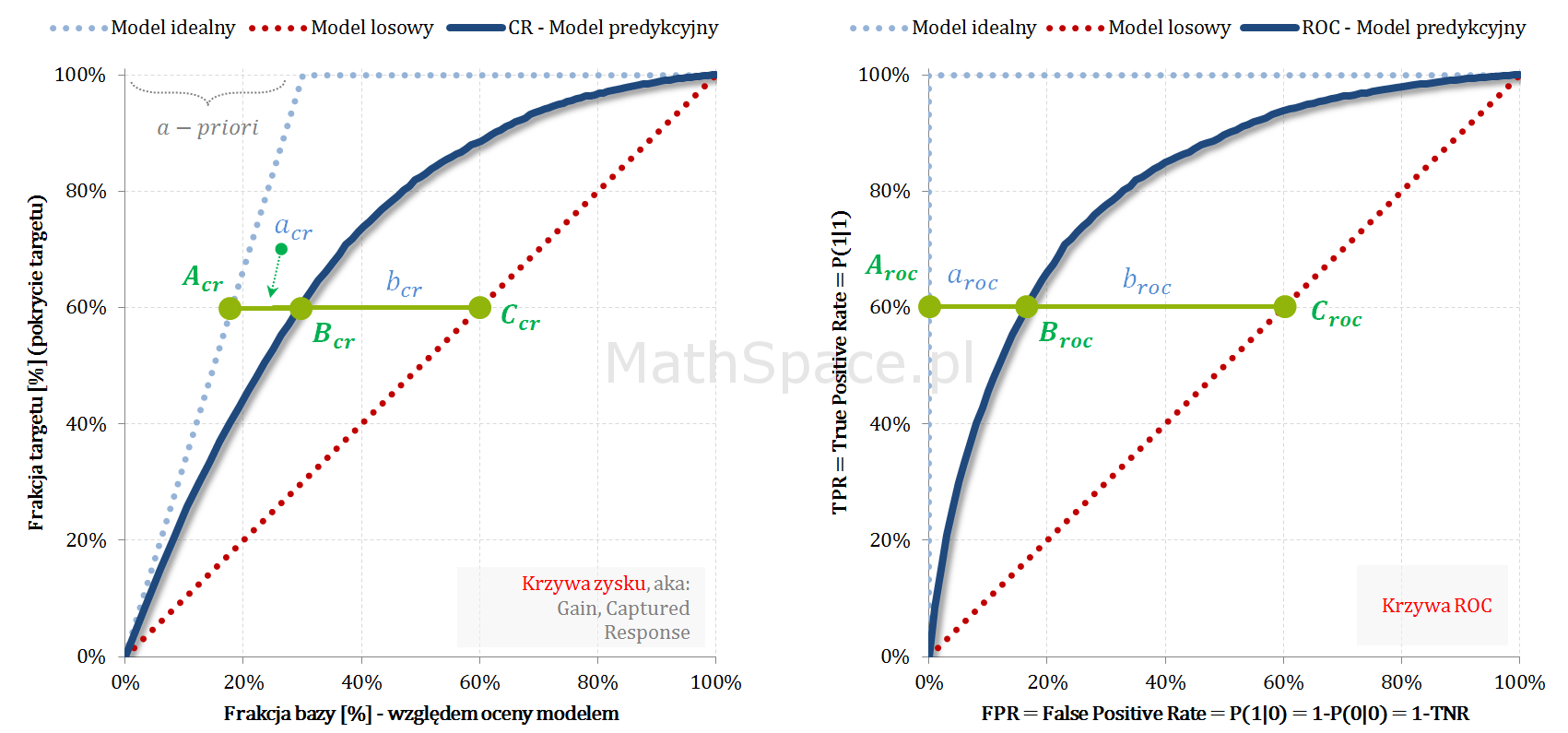
Fajne 🙂 prawda? Lift nieskumulowany można jednoznacznie wyprowadzić z krzywej Captured Response poprzez analizę „lokalnych” przyrostów frakcji bazy $\Delta q_n$ i frakcji targetu $\Delta q_t$.
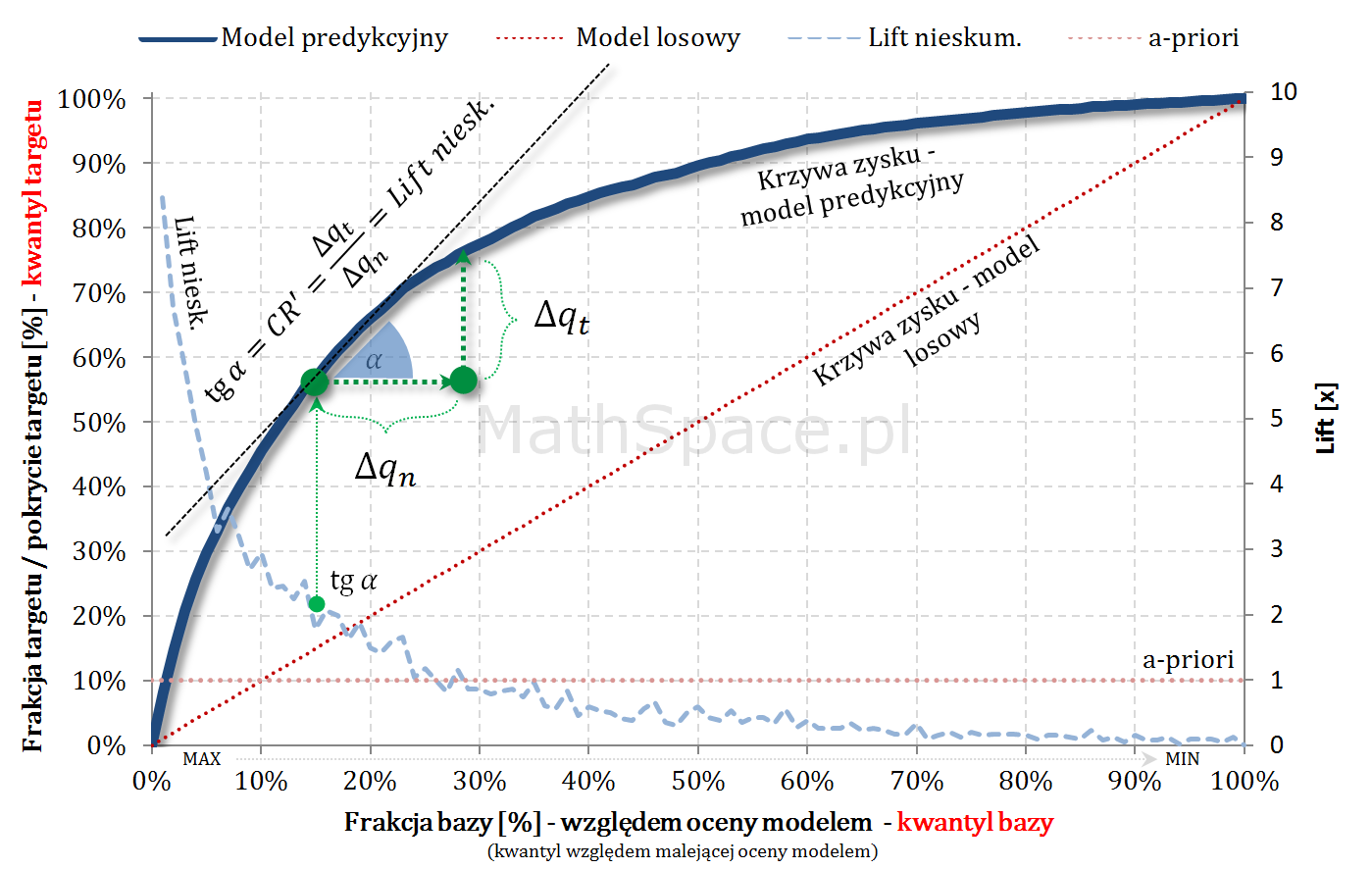
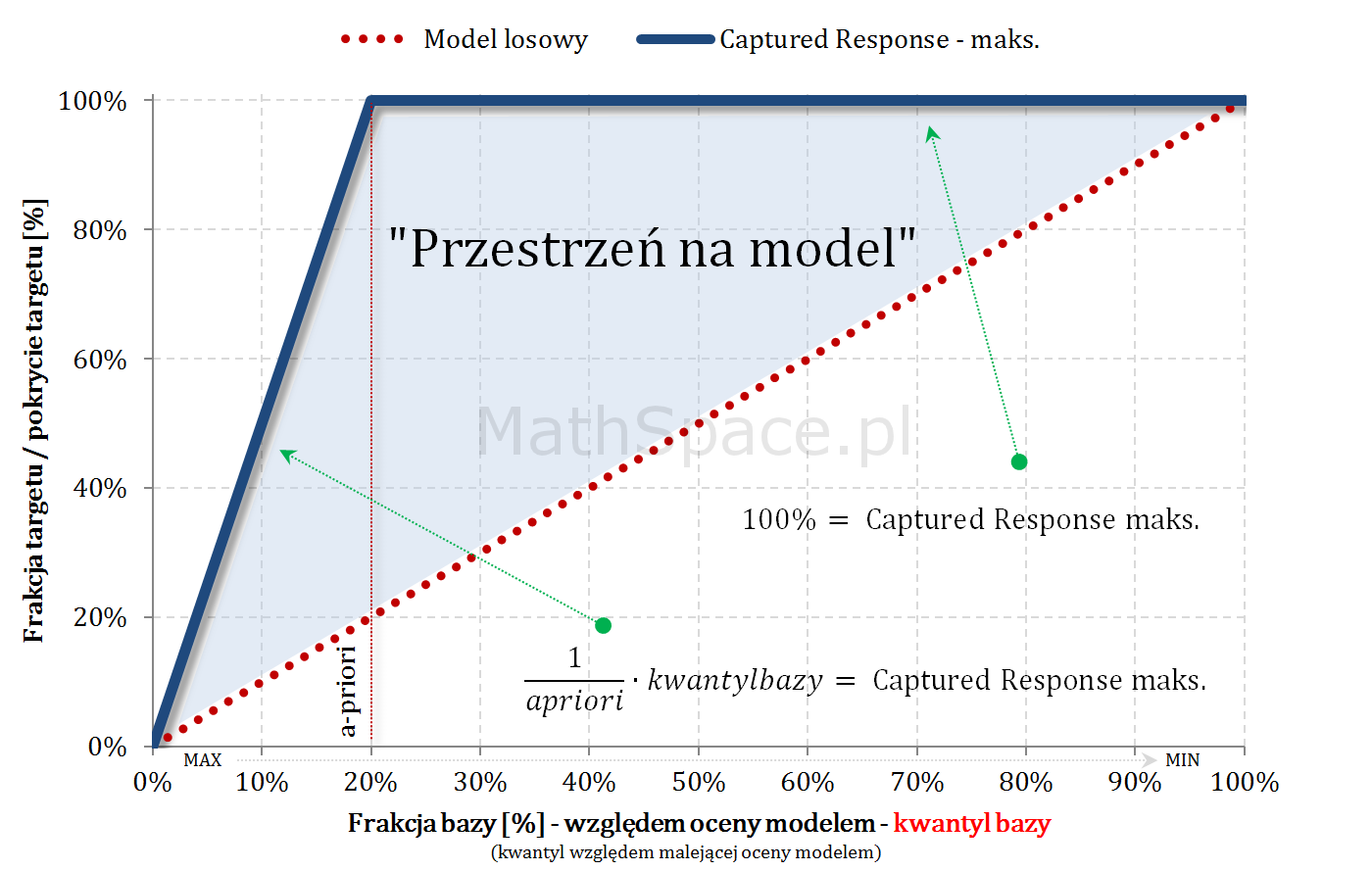
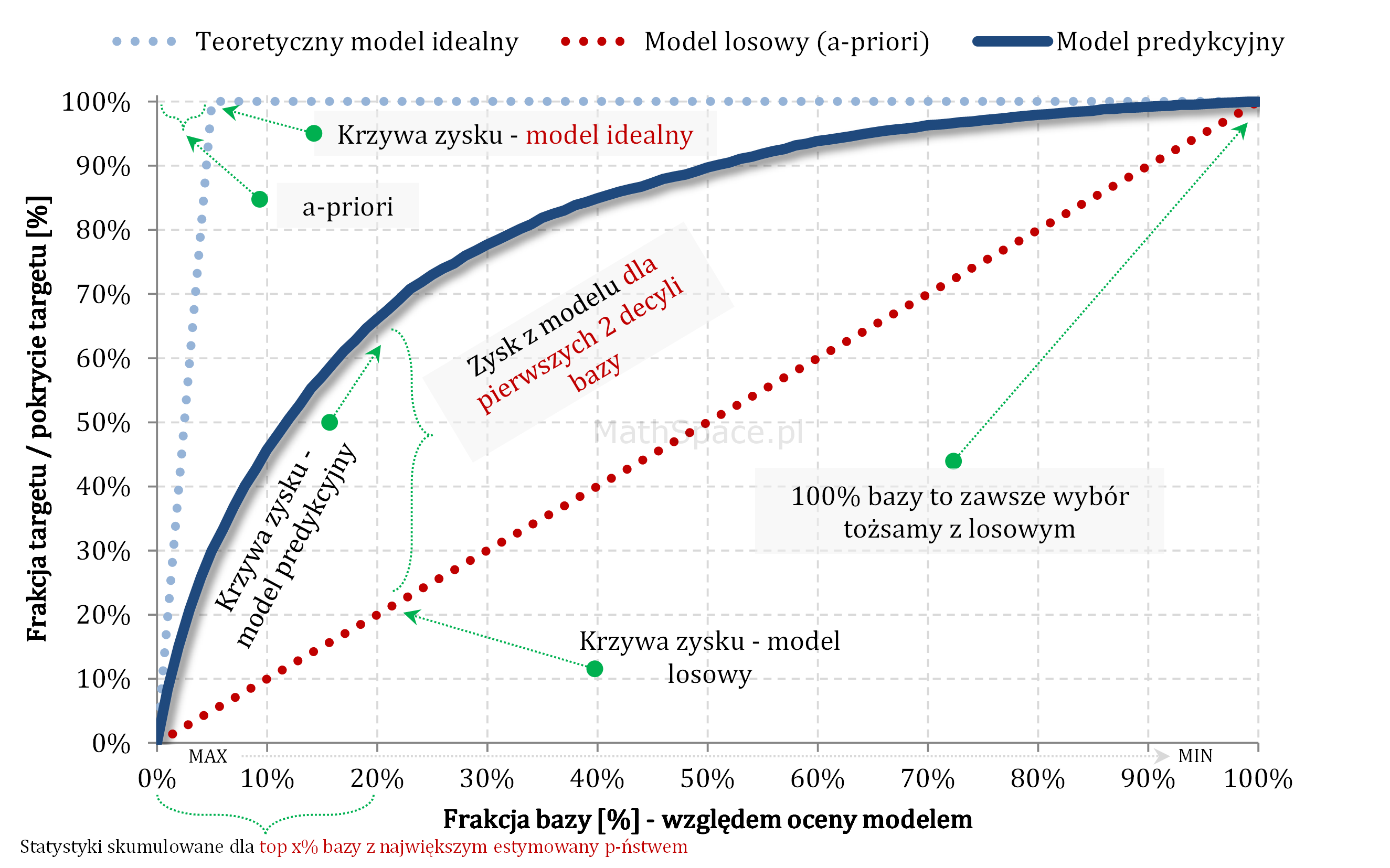
Captured Response – stosunek wartości dla badanego modelu oraz wartości dla modelu losowego to Lift skumulowany
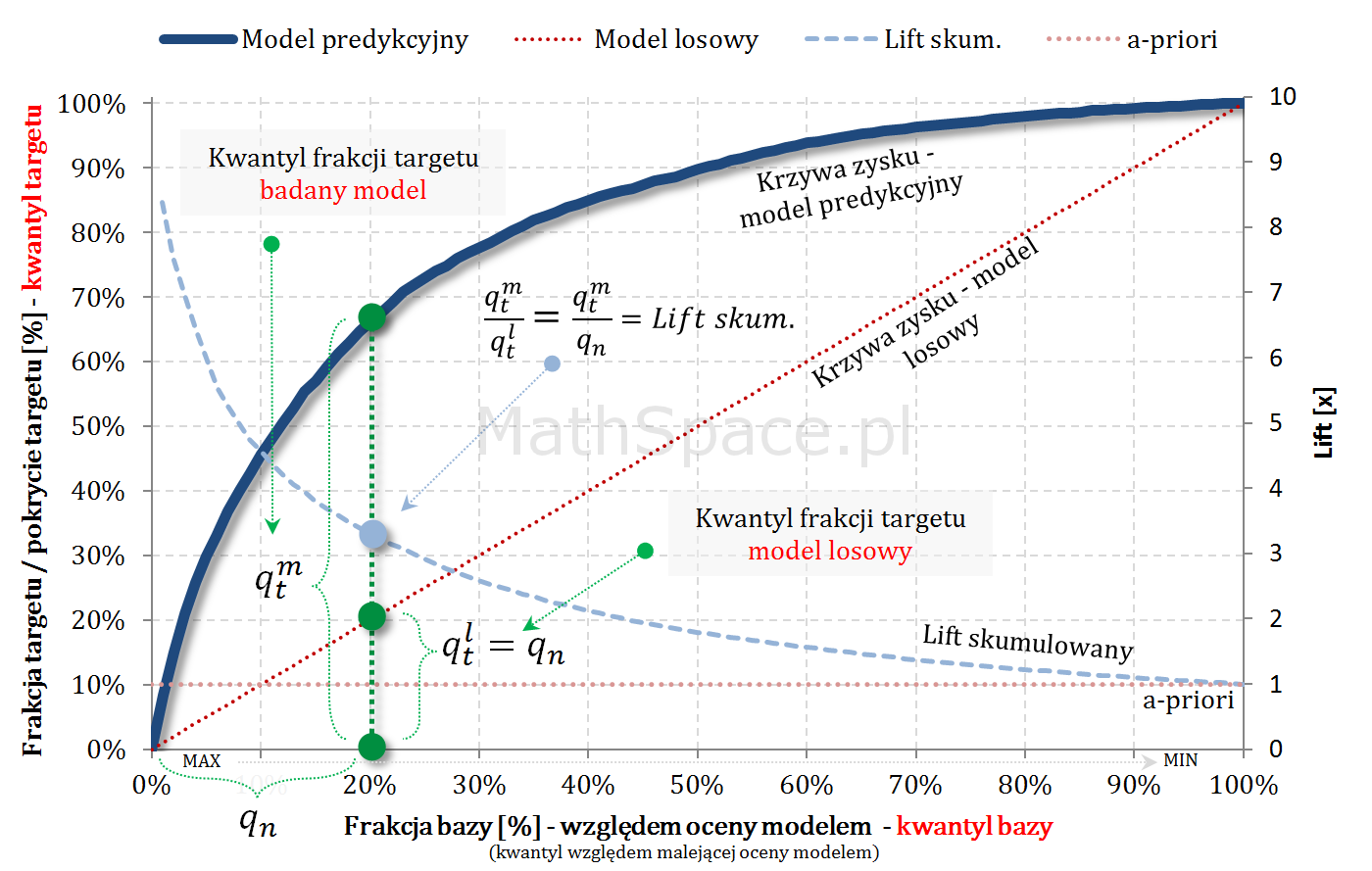
Oznaczamy:
- $N=N_1+N_0$ – liczba obiektów (np. klientów): total, z klasy „1”, z klasy”0″;
- $q_n$ – kwantyl bazy, czyli argument na osi poziomej;
- $n=n_1+n_0$ – liczba obiektów składających się na kwantyl $q_n$: total, z klasy „1”, z klasy”0″;
- $q_t^m$ – kwantyl targetu, czyli wartość Captured Response dla badanego modelu;
- $q_t^l$ – kwantyl targetu, czyli wartość Captured Response dla modelu losowego;
- $q_n=\frac{n}{N}$
- $q_t^m=\frac{n_1}{N_1}$
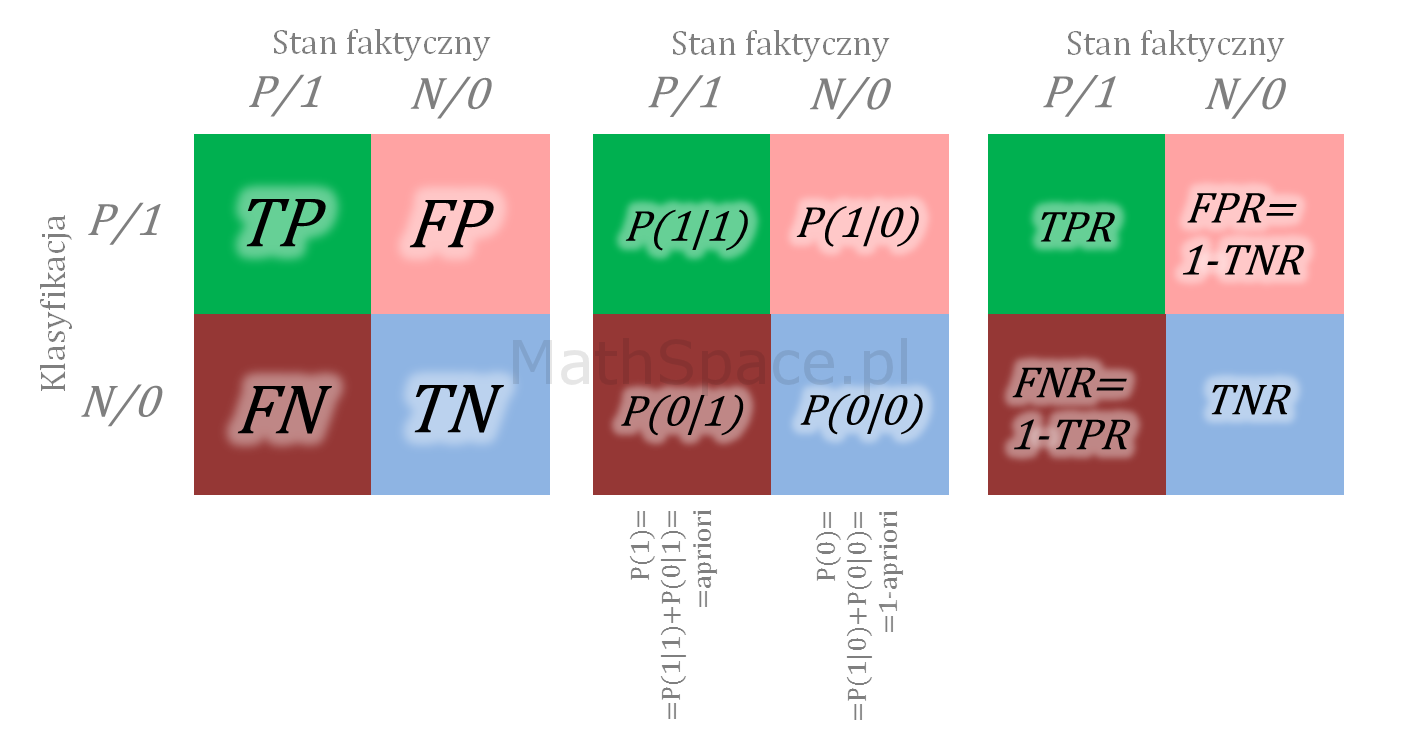
- Zauważmy, że $q_t^l=q_n=\frac{n}{N}$
$$\frac{q_t^m}{q_t^l}=\frac{n_1}{N_1}\bigg/\frac{n}{N}=\frac{n_1}{N_1}\cdot\frac{N}{n}=\frac{n_1}{n}\cdot\frac{N}{N_1}=\frac{n_1}{n}\bigg/\frac{N_1}{N}$$
$$\frac{q_t^m}{q_t^l}=\frac{n_1}{n}\bigg/\frac{N_1}{N}=\frac{p(1|q_n)}{p(1)}=Lift.Skumul$$
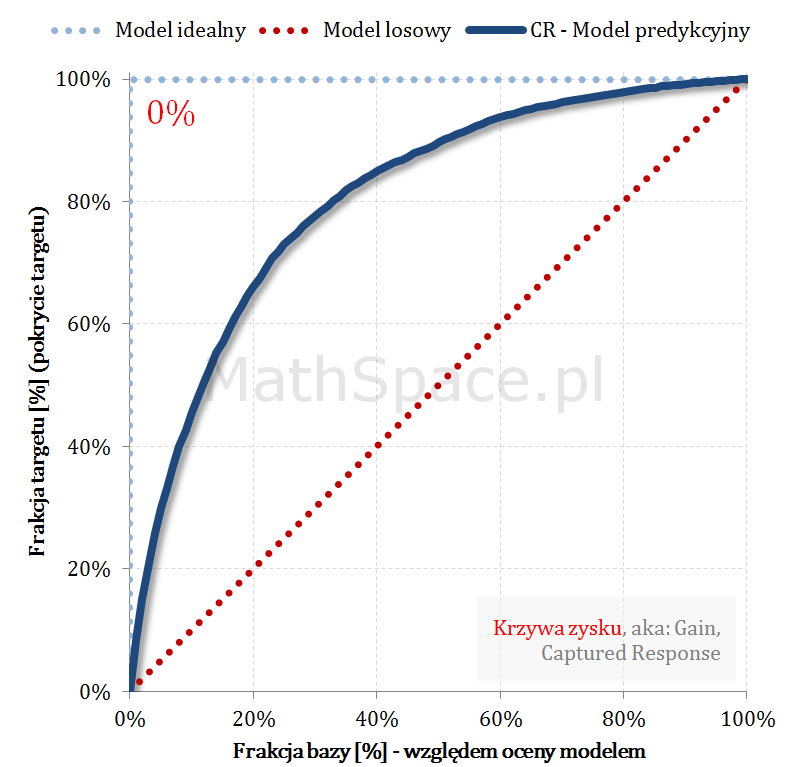
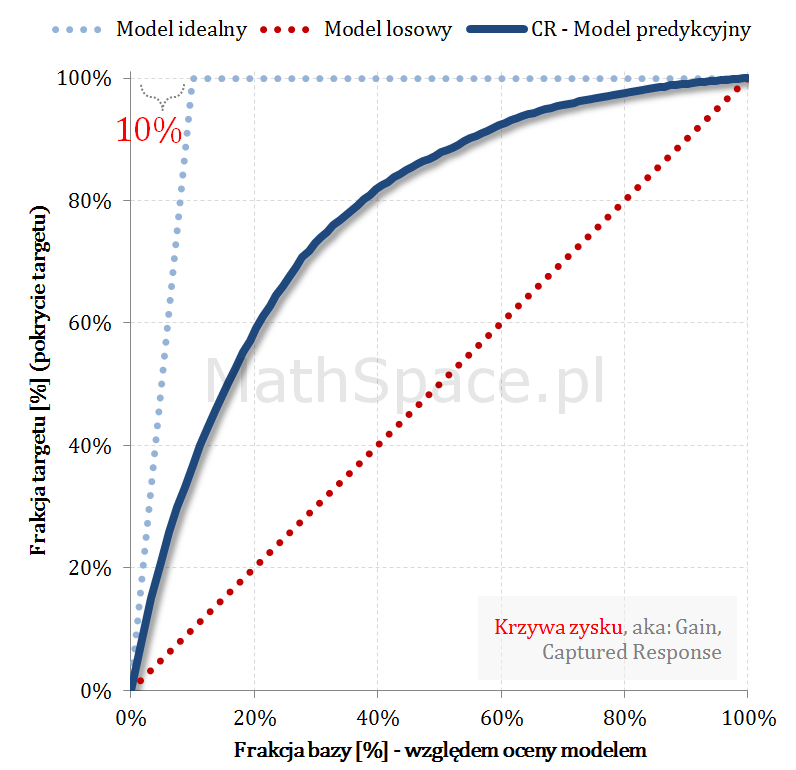
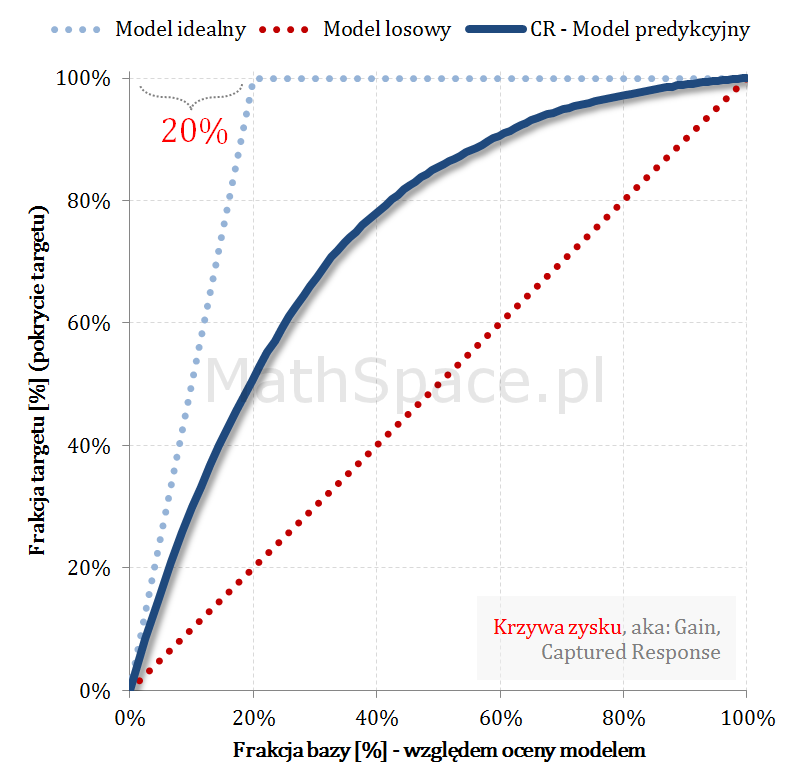
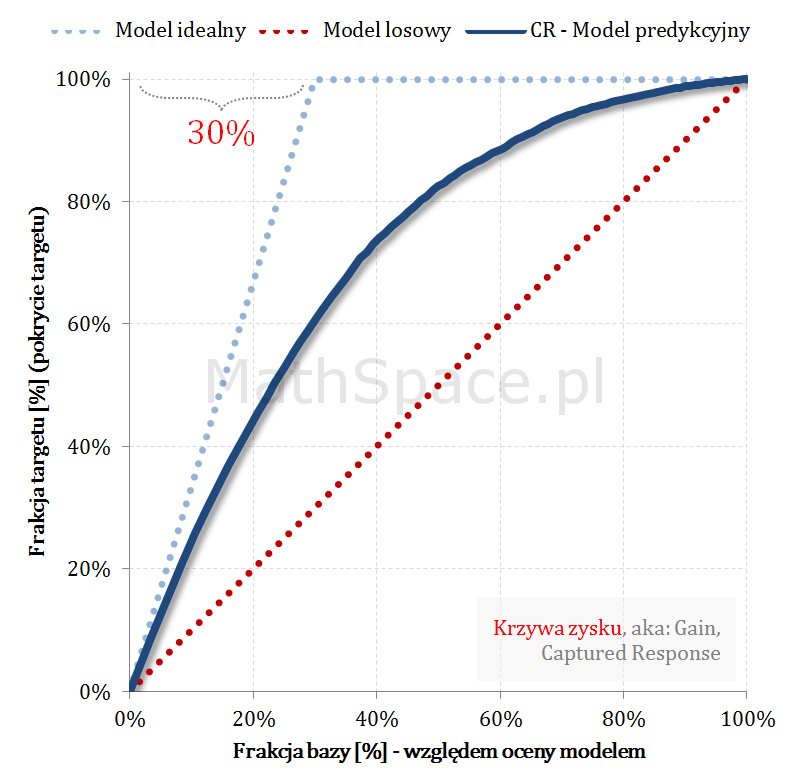
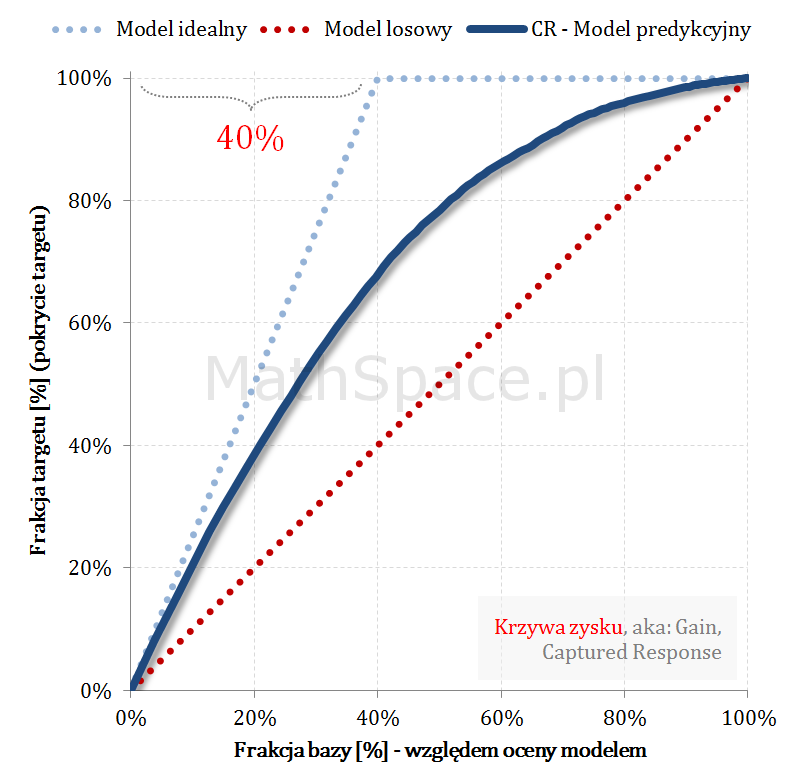
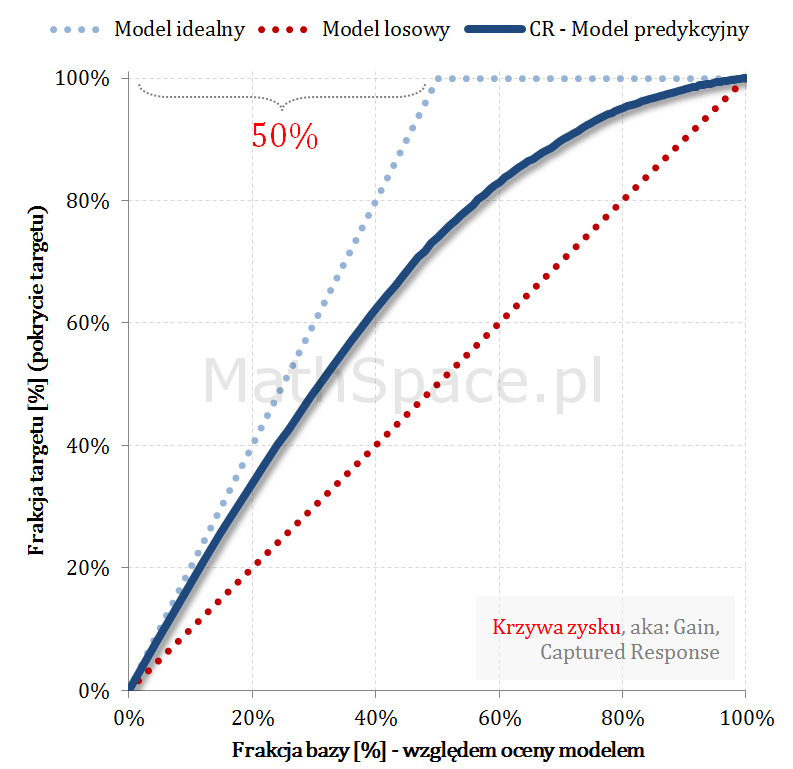
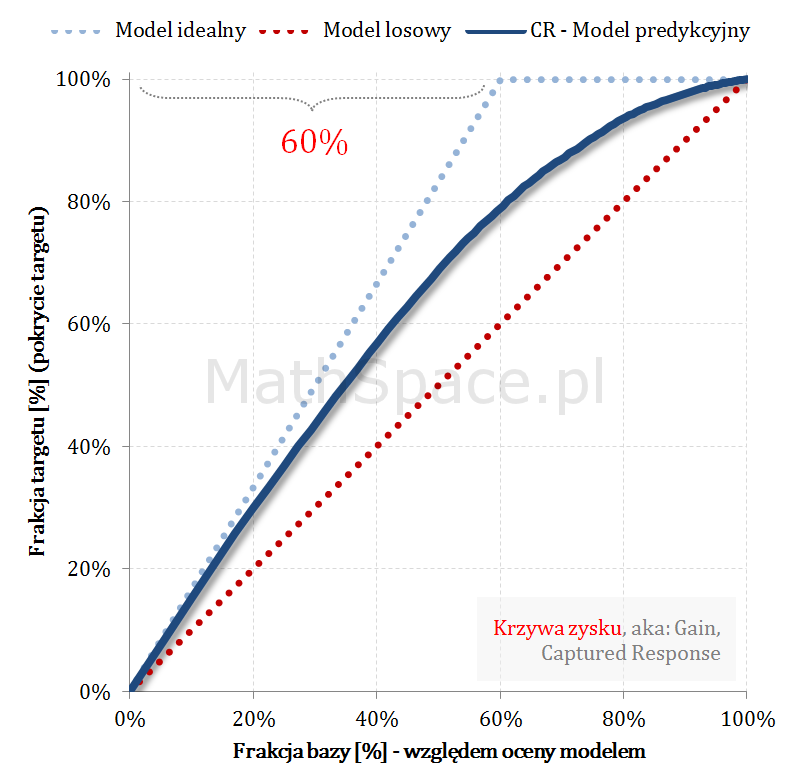
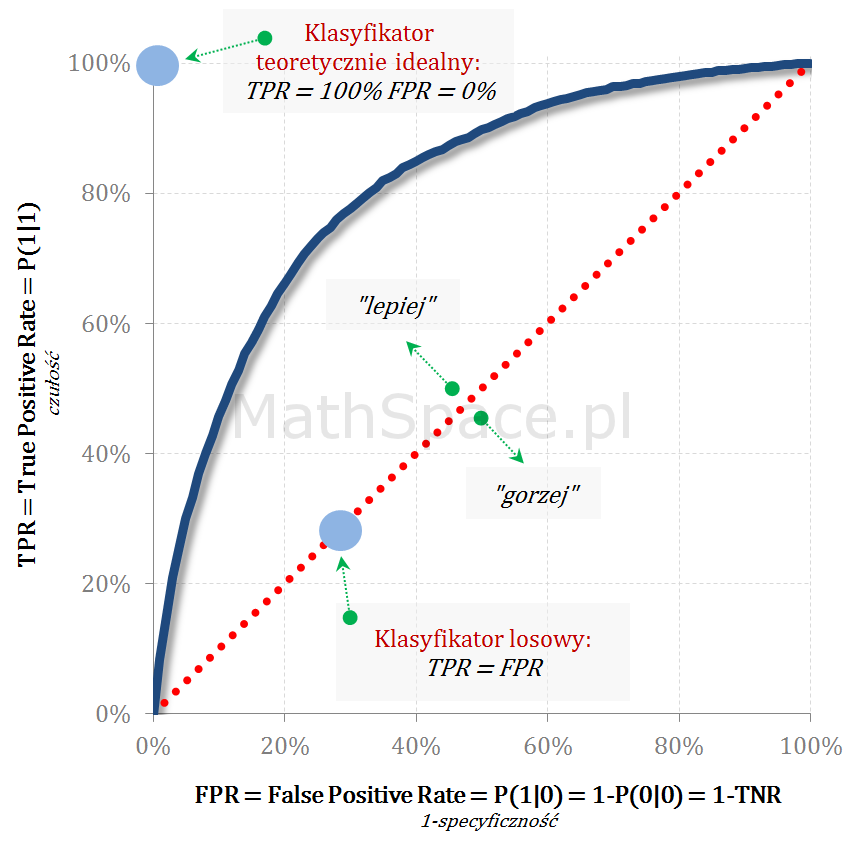
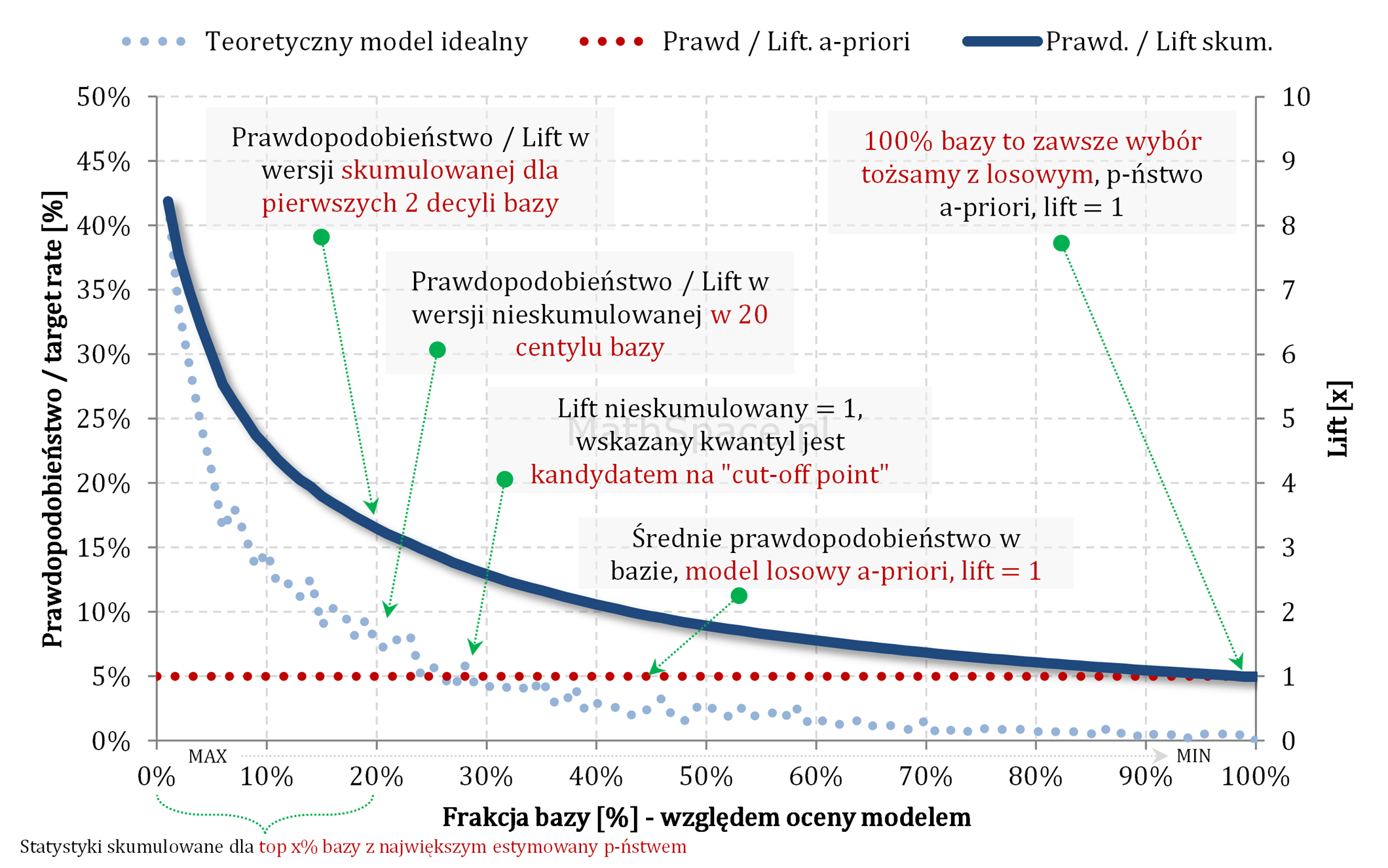
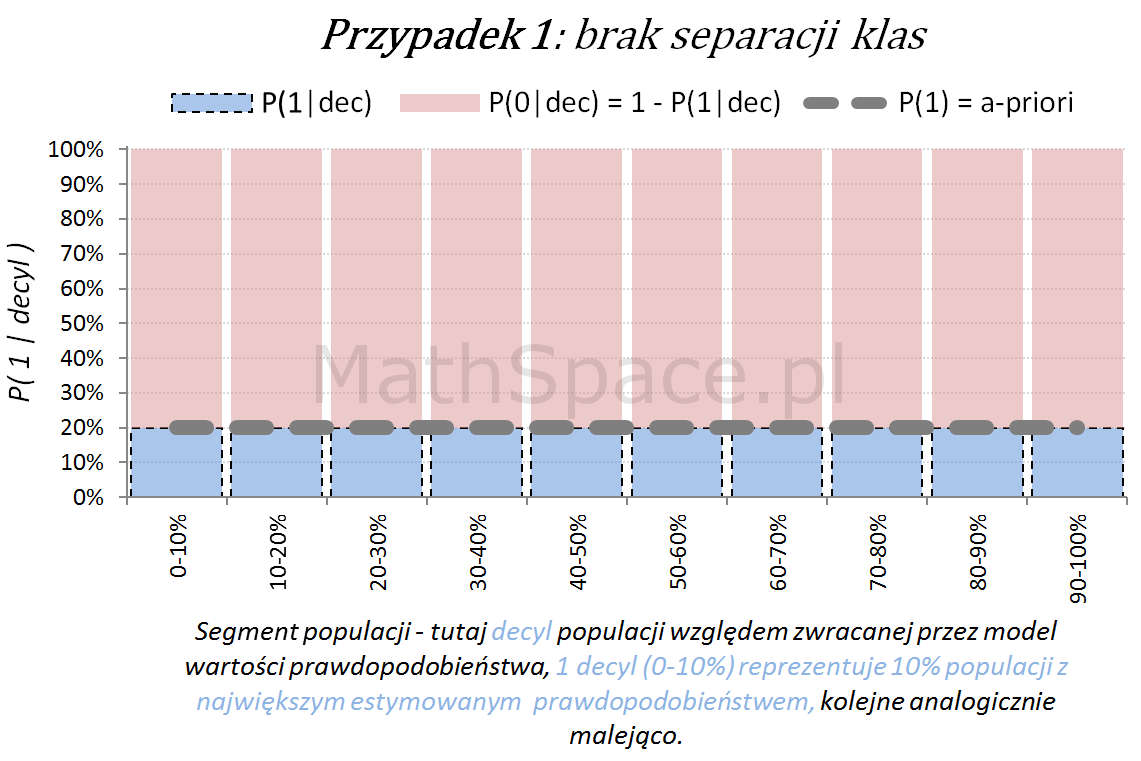
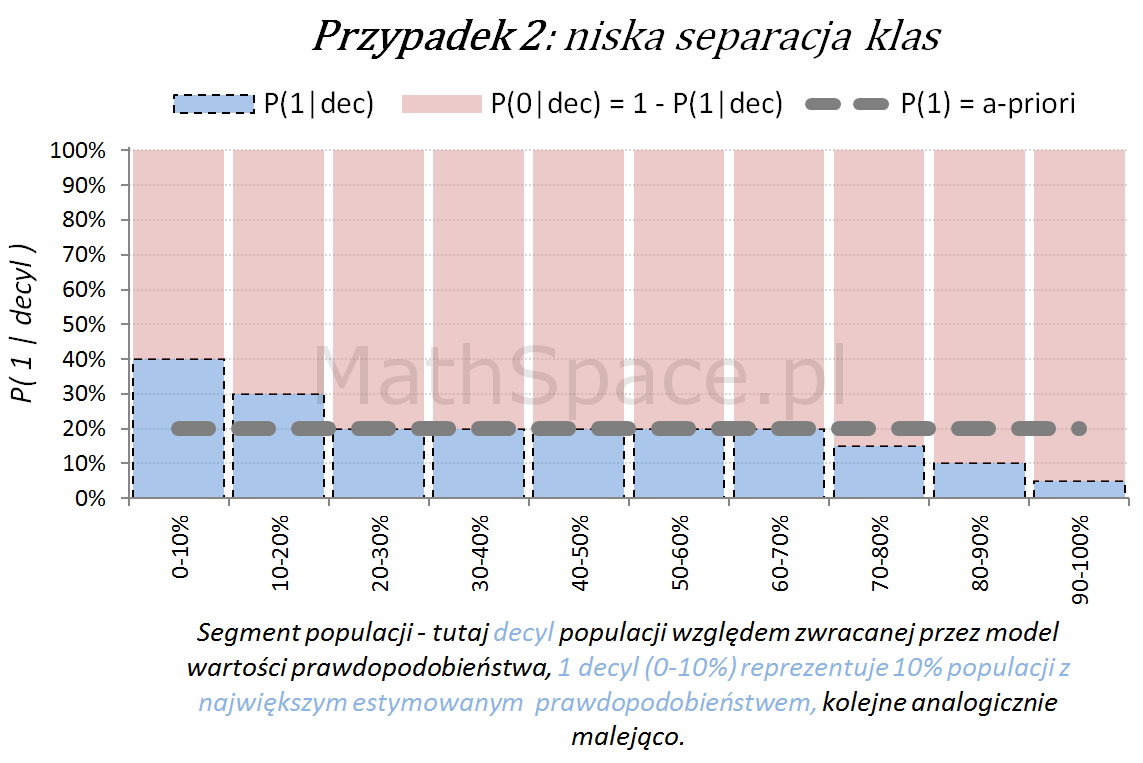
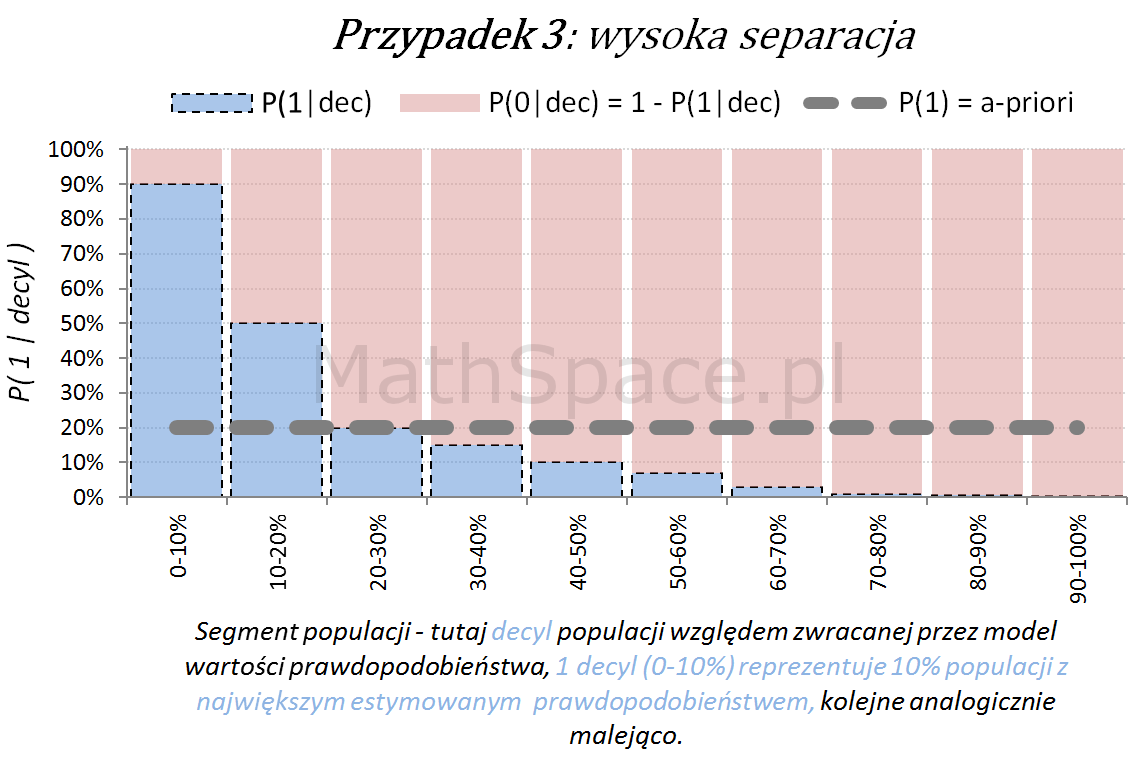
Kolejny fajny wniosek 🙂 , który można również łatwo uzasadnić na bazie wyżej opisanej zależności pomiędzy Captured Response i Liftem nieskumulowanym. Mianowicie wystarczy „delty liczyć” od punktu $(0,0)$ i zauważyć, że dla modelu losowego $q_t = q_n$. Pokazałem to na rysunku poniżej.
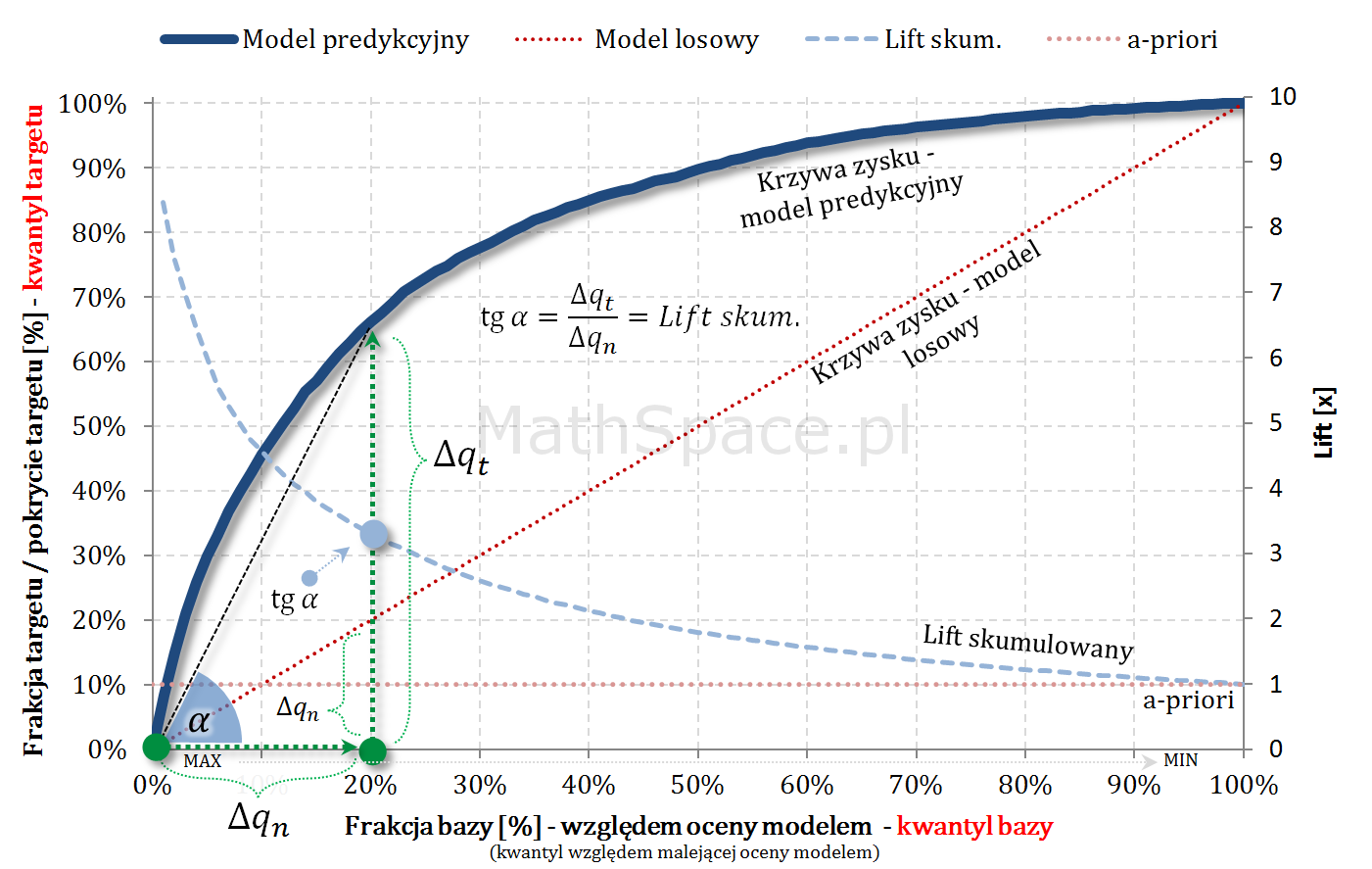
Lift skumulowany można jednoznacznie wyprowadzić z krzywej Captured Response poprzez analizę „globalnych” przyrostów frakcji bazy $\Delta q_n$ i frakcji targetu $\Delta q_t$.
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.



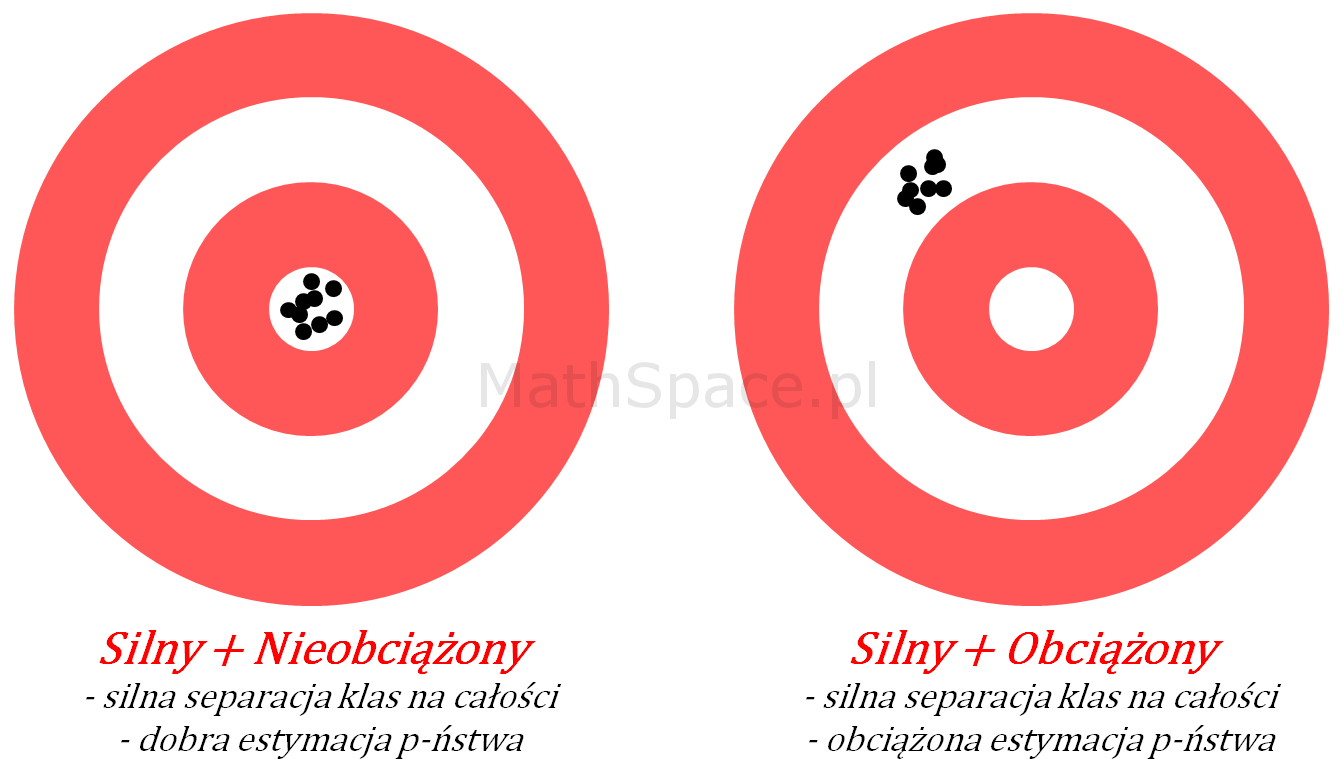
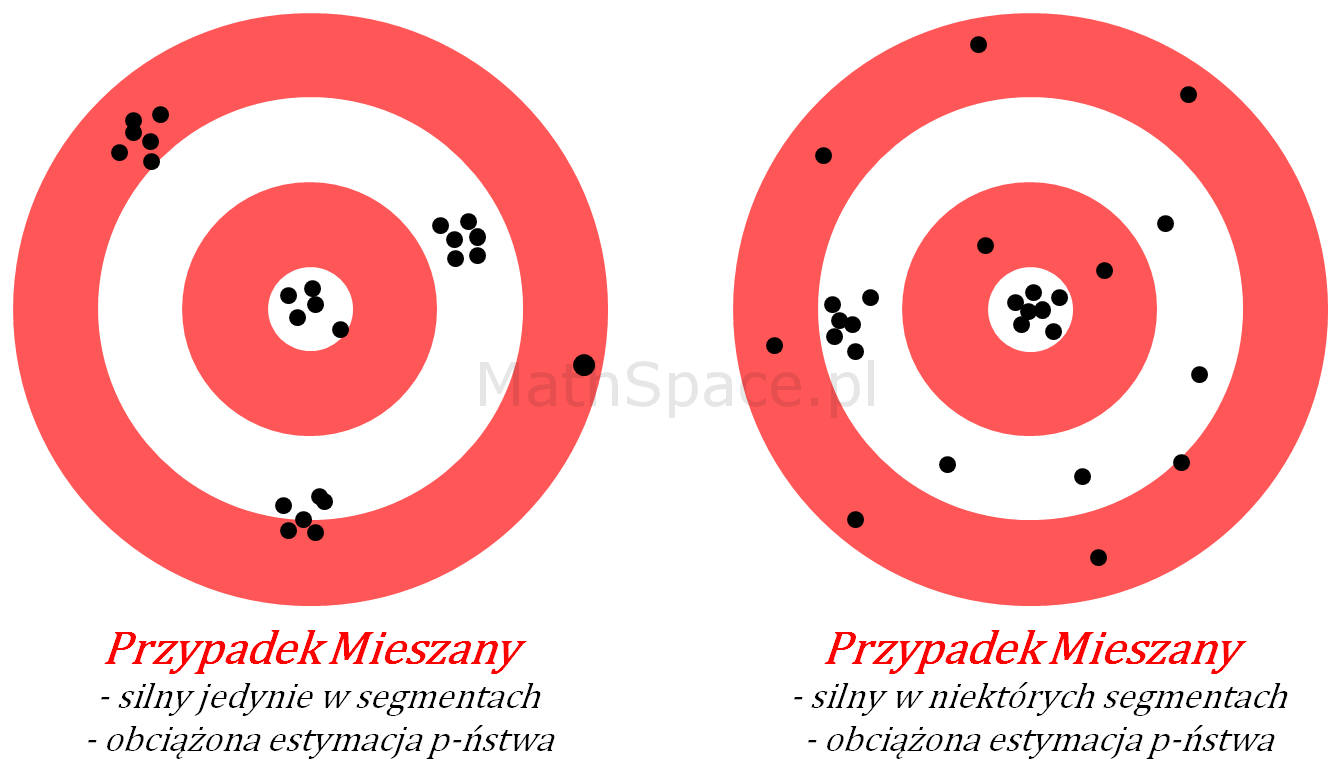
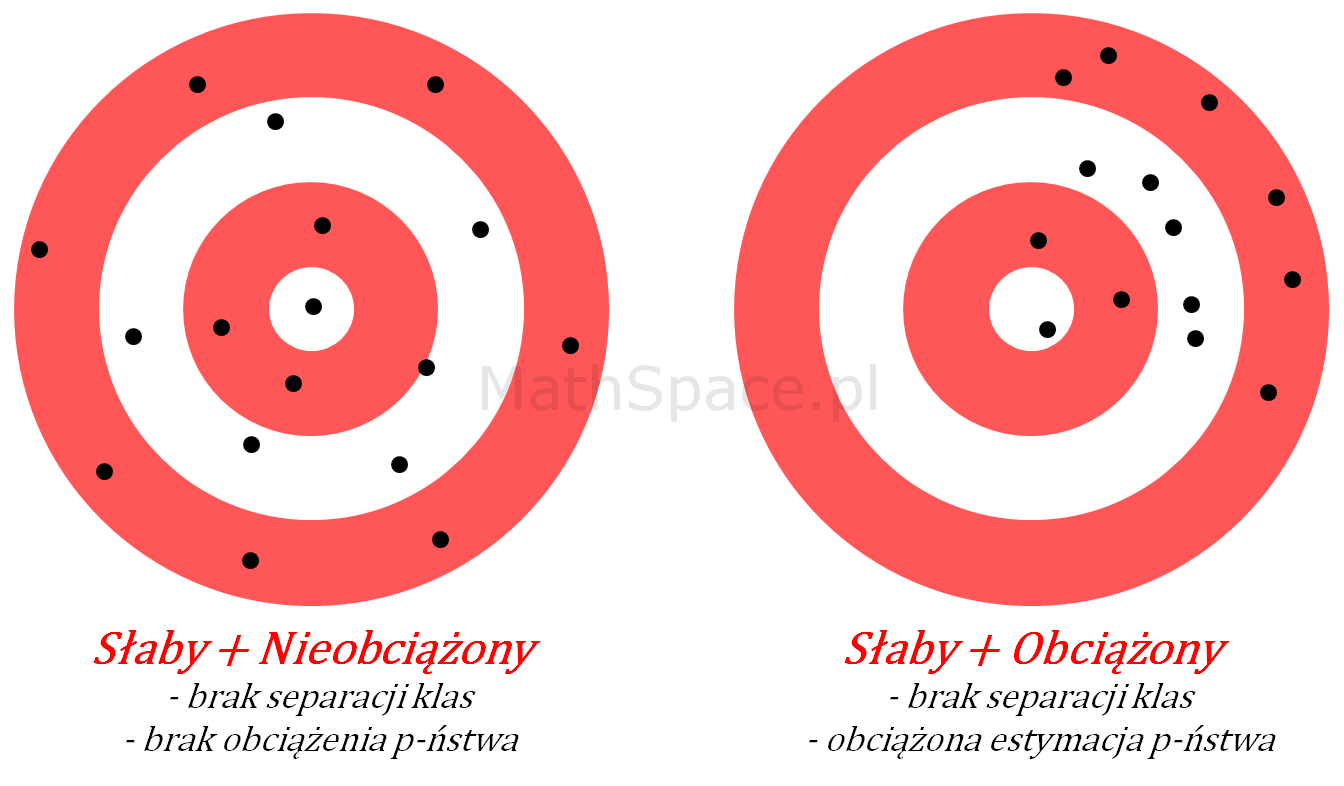
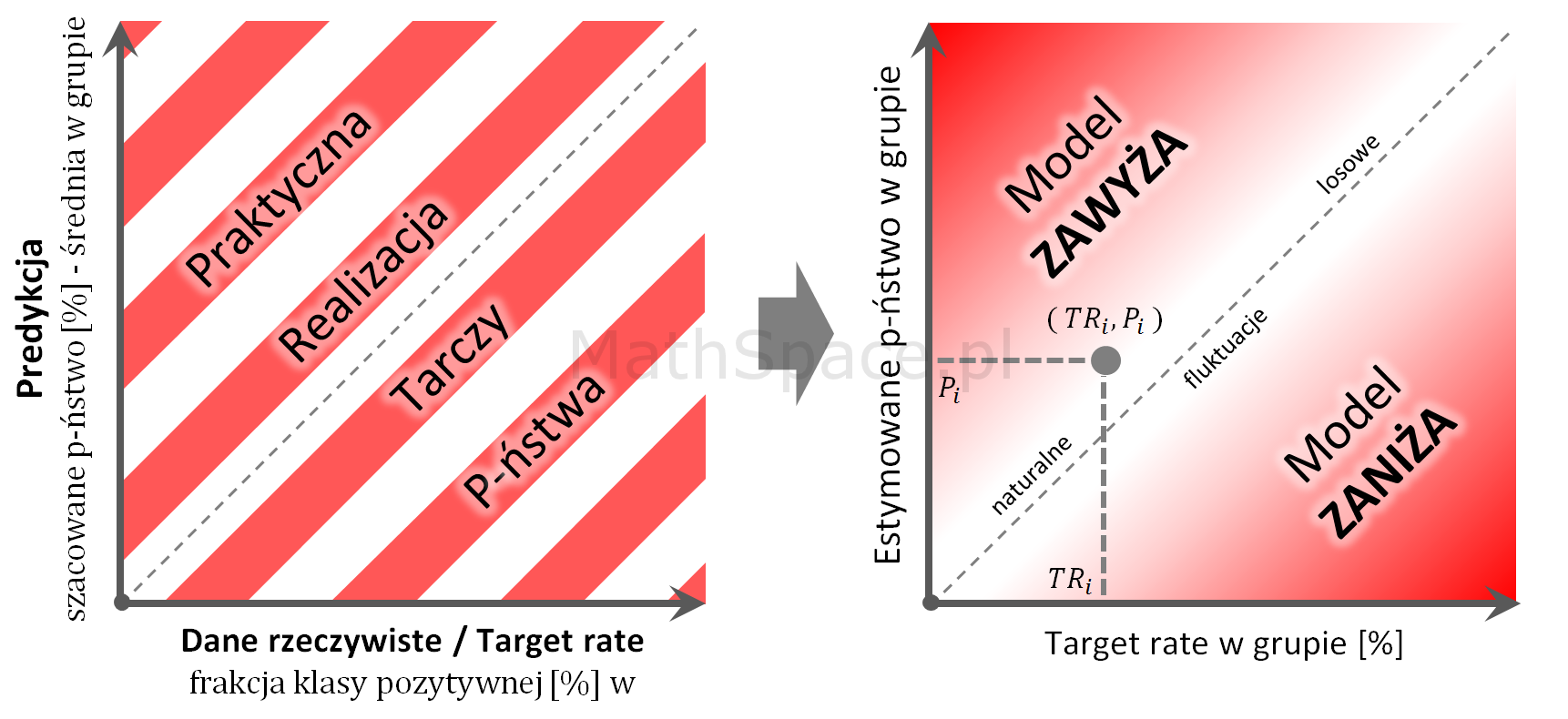





 Ostatecznie możliwy jest również
Ostatecznie możliwy jest również