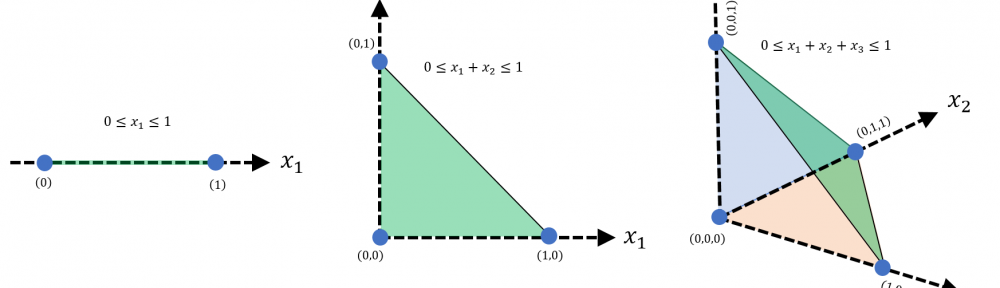
Pole powierzchni figur płaskich podobnych zmienia się z kwadratem skali podobieństwa – fakt nauczany już w szkole podstawowej. Dziś zadajemy pytanie „dlaczego” tak jest? O ile uzasadnienie dla najprostszych typów figur jest banalne (wynika bezpośrednio ze wzorów na pole), to w przypadku powierzchni ograniczonej dowolną krzywą (no może nie do końca dowolną) potrzeba już nieco więcej gimnastyki. Pokażę kilka podjeść, w tym osobno „pokryciowe”, osobno oparte na całce Riemanna, oraz osobno na bazie przekształcenia liniowego. Na koniec podam bardziej ogólne wnioski co do zmiany pola powierzchni względem znacznie szerszej niż podobieństwo klasy transformacji. Zapraszam 🙂