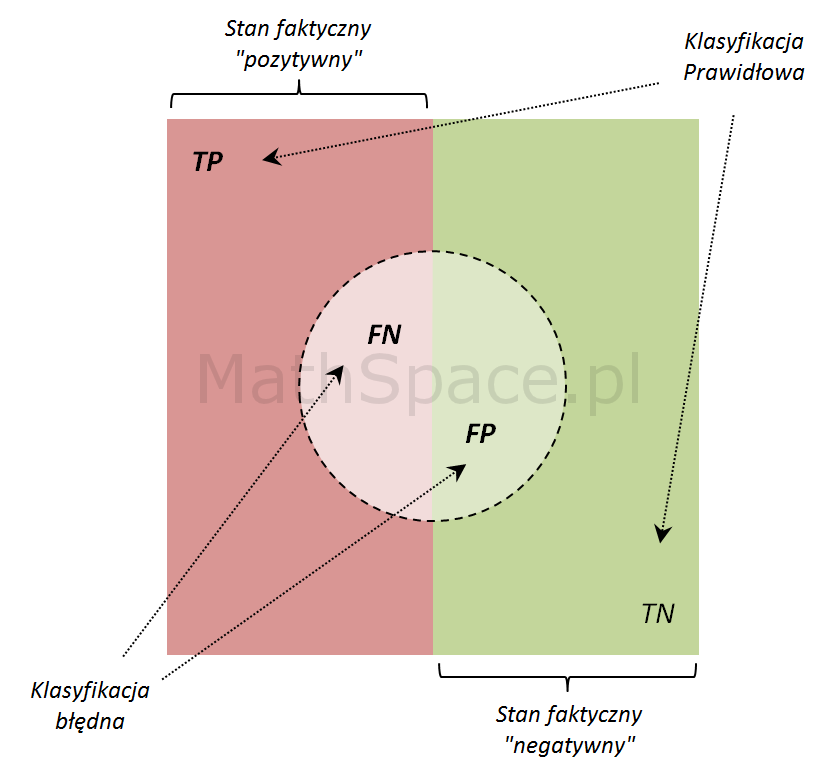
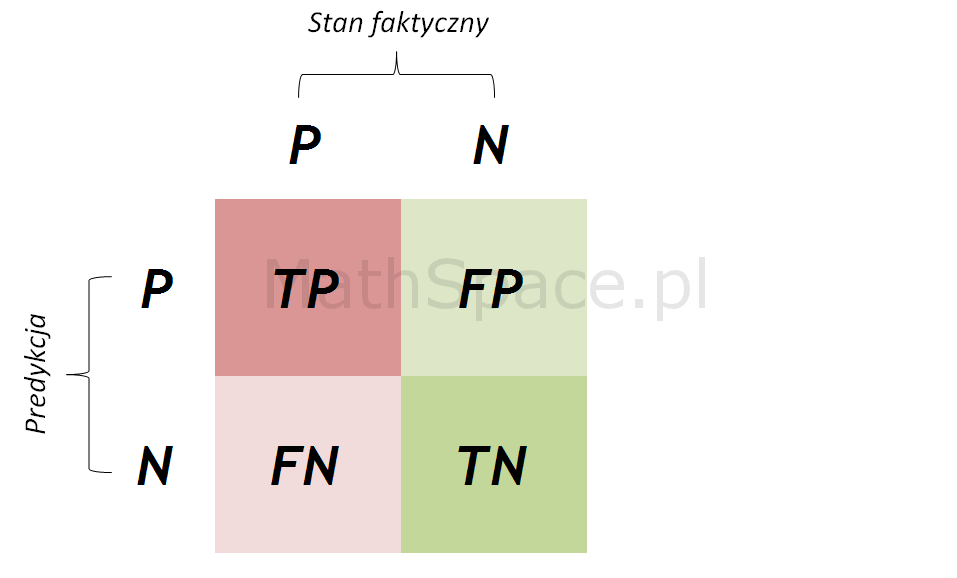
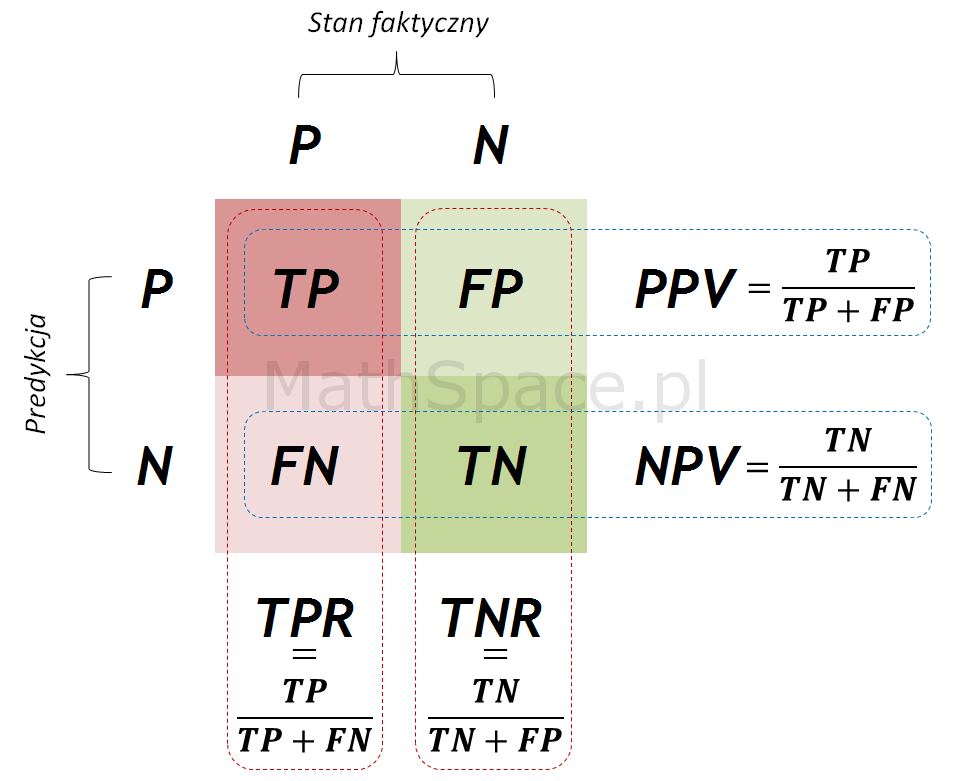
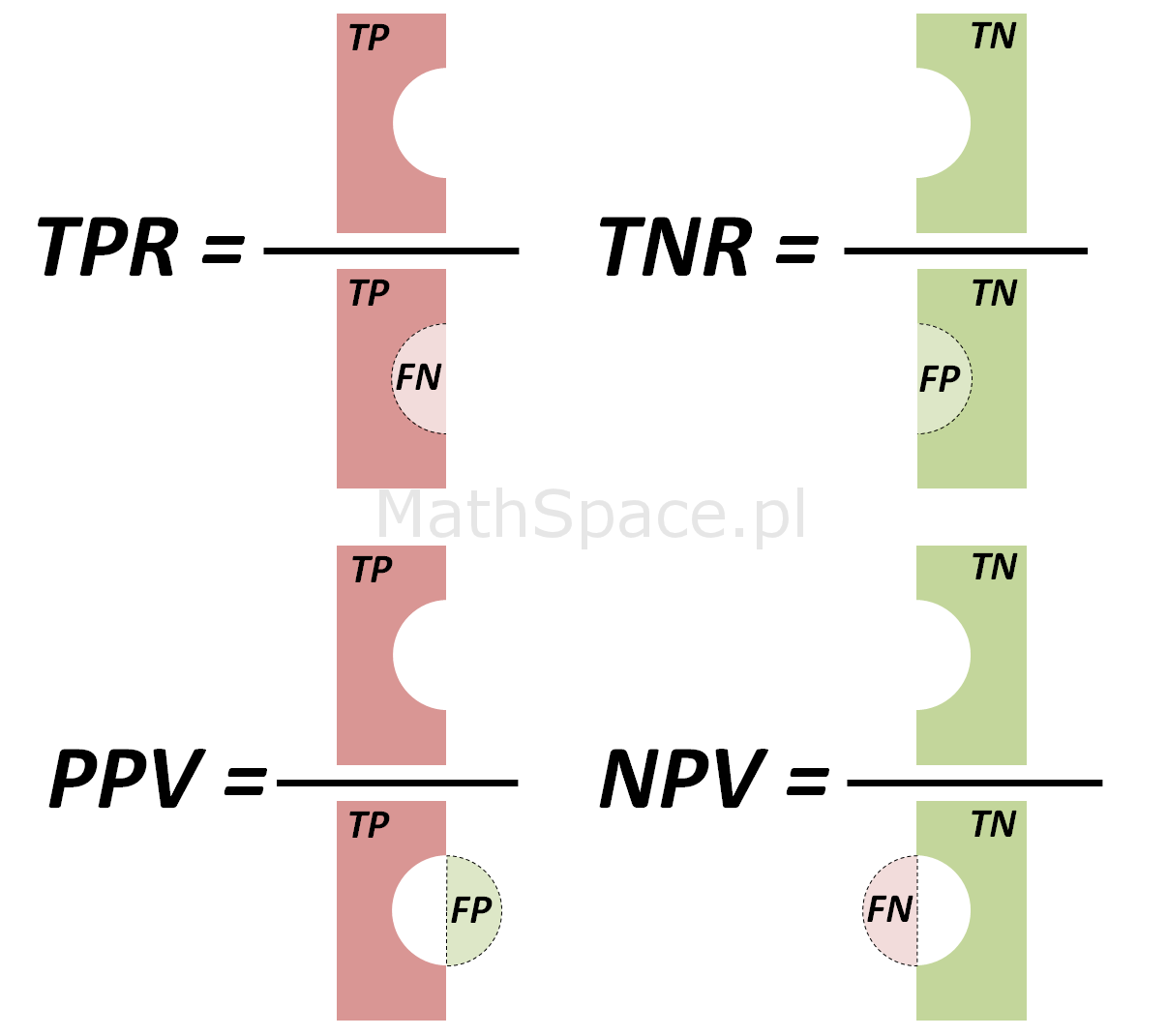
W poprzednich częściach omówiliśmy sposób tworzenia macierzy błędu oraz podstawowe miary oceny jakości klasyfikacji: czułość (TPR), specyficzność (TNR), precyzję przewidywania pozytywnego (PPV), precyzję przewidywania negatywnego (NPV). Opisane miary określone są dla klasyfikatora binarnego (klasyfikacja pozytywna bądź negatywna), jednak w praktyce najczęściej stosuje się modele predykcyjne z ciągłą zmienną odpowiedzi (np. estymator prawdopodobieństwa skorzystania z produktu, gdzie wynikiem działania modelu jest wartość z przedziału [0, 1] interpretowana właśnie jako wspomniane prawdopodobieństwo określane również skłonnością).
Model predykcyjny
Dla lepszego zrozumienia załóżmy, że analizujemy bazę $n$-klientów oznaczonych odpowiednio $x_1, x_2, \ldots, x_n$. Model predykcyjny to np. funkcja (estymator) zwracająca dla każdego klienta właściwe dla niego prawdopodobieństwo zakupienia produktu – oznaczmy więc fakt zakupienia produktu klasą pozytywną „1”. Teraz możemy podać bardziej formalne określenie – zatem model predykcyjny to estymator prawdopodobieństwa warunkowego $p(1|x_i)$, że wystąpi zakup produktu (klasa „1”), pod warunkiem, że zaobserwujemy cechy klienta $x_i$.
$$p(1| \cdot ) : \{x_1, x_2, \ldots, x_n\} \to [0;1]$$
$$x_i\mapsto p(1| x_i ) \in [0;1]$$
Obserwacja cech klienta, a nie samego klienta, jest tu niezwykle istotna. Mianowicie danego klienta mamy dokładnie jednego, natomiast klientów o tych samych / podobnych cechach (np. miejsce zamieszkania, wiek, itp.) możemy posiadać wielu, co dalej umożliwia wnioskowanie indukcyjne, a w wyniku otrzymanie upragnionego modelu 🙂 .
Segment wysokiej skłonności
Typowo mniejszość klientów charakteryzuje się „wysoką” skłonnością, natomiast „średnia” i „niska” skłonność jest przypisywana do znacznie większej części bazy. Łatwo to uzasadnić – zazwyczaj w określonym okresie czasu produkt kupuje maksymalnie kilka procent bazy klientów. Jeśli model predykcyjny posiada faktyczną wartość predykcyjną, wysokie prawdopodobieństwo przypisze do relatywnie niewielkiej części klientów. Idąc dalej – im lepszy model, tym segment o wysokiej skłonności jest mniejszy i bliższy rozmiarem do oszacowania pochodzącego ze średniej sprzedaży mierzonej dla całej analizowanej bazy klientów (tzw. oszacowanie a-priori).

Punkt odcięcia (cut-off point)
Zadaniem punktu odcięcia jest stworzenie na bazie ciągłej zmiennej odpowiedzi (np. szacowanego prawdopodobieństwa) segmentów (klas) – dla uproszczenia załóżmy, że dwóch (jeden punkt odcięcia). Oznaczmy przez $p_0 \in [0;1]$ punkt rozgraniczający segment wysokiej skłonności od segmentów średniej i niskiej skłonności. Jeśli szacowane prawdopodobieństwo $p(1|x_i) \geq p_0$ klientowi $x_i$ przypiszemy klasę pozytywną „1”, w przeciwnym wypadku klientowi przypisujemy klasę negatywną „0”.
W powyższy sposób z „ciągłego” modelu predykcyjnego otrzymaliśmy klasyfikator binarny – co, w zestawieniu z faktycznymi zdarzeniami zakupu, umożliwia utworzenie macierzy błędu i wyznaczenie wszystkich istotnych miar oceny jakości dokonanej klasyfikacji.
Ale jak dobrać punkt odcięcia? O tym w następnej części 🙂
- Confusion matrix, Macierz błędu, tablica pomyłek – czyli ocena jakości klasyfikacji (część 1)
- Zasięg (TPR – czułość / TNR – specyficzność) i precyzja (PPV / NPV) – czyli ocena jakości klasyfikacji (część 2)
- Model predykcyjny i siła separacji klas – czyli ocena jakości klasyfikacji (część 4)
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.