Kilka dni temu Google udostępnił na zasadzie open source (licencja Apache 2.0) własną platformę „TensorFlow” przeznaczoną do uczenia maszynowego. TensorFlow obecnie wspiera większość usług Google, między innymi transkrypcja mowy na tekst, rozpoznawanie pisma ludzkiego, Google Translate, rozpoznawanie i kategoryzowanie obrazów, Gmail, i wiele innych. TensorFlow dostarcza wysokowydajne API w językach C++ i Python również w wersjach dla urządzeń mobilnych.
Geneza powstania TensorFlow
TensorFlow jest następcą rozwiązania DistBelief (Large Scale Distributed Deep Networks), którego Google używał z sukcesem od 2011 roku np. zwyciężając w konkursie Large Scale Visual Recognition Challenge 2014. DistBelief koncentrował się wyłącznie na sieciach neuronowych i był mocno osadzony w infrastrukturze Google, co uniemożliwiało udostępnienie platformy w ramach open source.
Na stronie www.tensorflow.org znajdziecie kody, pakiety instalacyjne, tutoriale i dokumentacje.
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
I Am Here – RELEARN – Mariusz Gromada (2024)
I Am Here – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
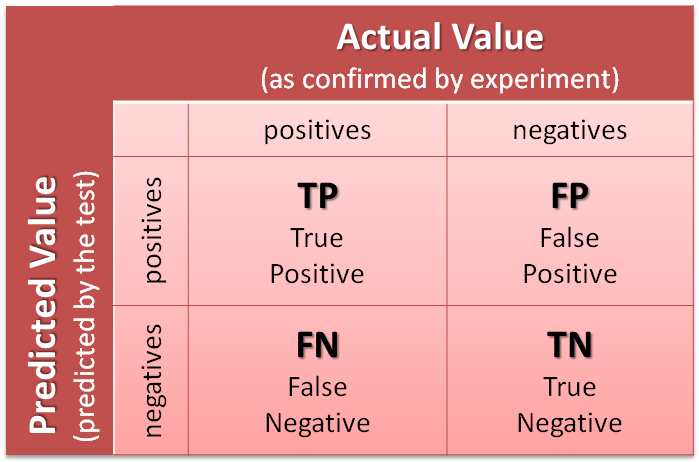
Macierz błędu jest podstawowym narzędziem stosowanym do oceny jakości klasyfikacji. Poniżej rozważymy przypadek klasyfikacji binarnej (dwie klasy). Kodowanie klas:
1 – Positive (np.: fakt skorzystania z produktu przez Klienta, pacjent z potwierdzoną chorobą, pacjentka z potwierdzoną ciążą)
0 – Negative (np.: fakt nieskorzystania z produktu przez Klienta, pacjent z wykluczoną chorobą, pacjentka z wykluczoną ciążą)
Możliwe wyniki klasyfikacji
Macierz błędu powstaje z przecięcia klasy prognozowanej i klasy faktycznie zaobserwowanej, mamy zatem 4 przypadki (2 dla zgodności i 2 dla niezgodności prognozy ze stanem faktycznym).
True-Positive(TP– prawdziwie pozytywna): przewidywanie pozytywne, faktycznie zaobserwowana klasa pozytywna (np. pozytywny wynik testu ciążowego i ciąża potwierdzona)
True-Negative(TN– prawdziwie negatywna): przewidywanie negatywne, faktycznie zaobserwowana klasa negatywna (np. negatywny wynik testu ciążowego i brak ciąży)
False-Positive(FP– fałszywie pozytywna): przewidywanie pozytywne, faktycznie zaobserwowana klasa negatywna (np. pozytywny wynik testu ciążowego, jednak faktyczny brak ciąży)
False-Negative(FN– fałszywie negatywna): przewidywanie negatywne, faktycznie zaobserwowana klasa pozytywna (np. negatywny wynik testu ciążowego, jednak ciąża potwierdzona)
Confusion Matrix
Stan faktyczny
P
N
Przewidywanie
P
TP True-Positive
FP False-Positive
N
FN False-Negative
TN True-Negative
Przykład – do grupy 2000 osób skierowano komunikację marketingową zachęcającą do skorzystania z produktu. Spośród 2000 osób produkt zakupiło 600. Grupę 2000 podzielono losowo na dwie równoliczne części, każda po 1000 osób (w tym w każdej po 300 klientów, którzy skorzystali z produktu). Pierwszej grupie przydzielono rolę „danych uczących”, zaś drugiej rolę „danych testowych”. Wykorzystując dane uczące, dostępne charakterystyki klientów oraz informacje o fakcie zakupienia produktu (tzw. target), przygotowano (wytrenowano / nauczono) klasyfikator umożliwiający przewidywanie czy dany klient skorzysta z produktu. Oceny jakości klasyfikatora dokonano przy wykorzystaniu danych testowych (tzn. danych, które nie były używane w procesie uczenia). Wyniki oceny zaprezentowano w postaci poniższej macierzy błędów.
Confusion Matrix dla powyższego przykładu
Stan faktyczny
P
N
Przewidywanie
P
250 True-Positive
100 False-Positive
N
50 False-Negative
600 True-Negative
Wnioski:
TP + FN + TN + FP = 250 + 50 + 600 + 100 = 1000 – liczba klientów (baza, na której dokonano oceny)
P = TP + FN = 250 + 50 = 300 – liczba klientów, którzy kupili produkt
N = TN + FP = 600 + 100 = 700 – liczba klientów, którzy nie skorzystali z produktu
TP + TN = 250 + 600 = 850 – liczba poprawnych klasyfikacji
FP + FN = 100 + 50 = 150 – liczba błędnych klasyfikacji
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
I Am Here – RELEARN – Mariusz Gromada (2024)
I Am Here – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Temat pracy dotyczy problemu dyskryminacji oraz budowy i zastosowań rodzin klasyfikatorów, w tym głównie metody typu bagging, metody typu boosting oraz lasów losowych. Przedmiotem pracy jest zbadanie metematyczno-statystycznych fundamentów, na których opierają się metodologie budowy rodzin klasyfikatorów. Istotną częścią pracy jest analiza rozwiązań podanych zagadnień.
W pierwszym rozdziale omówiony został problem klasyfikacji pod nadzorem, zwanej analizą dyskryminacyjną. Podano model analizy dyskryminacyjnej oraz przedstawiono podstawowe metody rozwiązań podanych zagadnień. Dużo uwagi poświęcono ocenie jakości klasyfikacji.
Rozdział drugi skupia się na idei łączenia klasyfikatorów, w tym przede wszystkim na podaniu i uzasadnieniu ich zalet. Wprowadzono precyzyjną definicję rodziny oraz miarę pewności predykcji opartej na rodzinie klasyfikatorów.
Kolejne trzy rozdziały poświęcone są wspomnianym metodom łączenia klasyfikatorów w analizie dyskryminacyjnej. Rozdział trzeci omawia metodę typu bagging. Rozdział czwarty przedstawia metodę typu boosting. Natomiast rozdział piąty skupia się na metodzie lasów losowych.
Pracę kończy szeroka analiza danych, potwierdzająca własności rozważanych metod.
Autorem pracy jest Iwona Głowacka-Gromada – praca została przygotowana pod opieką Pana Profesora Jacka Koronackiego. Serdecznie zapraszam do lektury 🙂
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
I Am Here – RELEARN – Mariusz Gromada (2024)
I Am Here – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Temat pracy dotyczyproblemu dyskryminacji oraz budowy drzew klasyfikacyjnych w kontekście ich przydatności do rozwiązywania zadań o dużym wymiarze prób losowych i/lub dużym wymiarze wektora obserwacji, w których podstawowego znaczenia nabiera złożoność obliczeniowa drzewa. Radzenie sobie z dużymi zbiorami danych wymaga konstrukcji specjalnych technik sortowania danych w trakcie budowy drzewa, kodowania, organizacji wzrostu i przycinania drzewa. Wymaga także zrównoleglenia obliczeń. Przedmiotem pracy jest sformułowanie modelu analizy dyskryminacyjnej oraz analiza możliwych rozwiązań podanych zagadnień, wraz z implementacją jednego z nich.
W pierwszym rozdziale omawiam problem dyskryminacji pod nadzorem, nazywanej analizą dyskryminacyjną, wprowadzając formalny model klasyfikacyjny osadzony w przestrzeni probabilistycznej.
Rozdział drugi poświęcony jest budowie drzew klasyfikacyjnych, gdzie ze szczególną uwagą potraktowano problem złożoności i skalowalności. Rozdział wprowadza formalną definicję drzewa klasyfikacyjnego w oparciu o podstawy teorii grafów oraz o model klasyfikacyjny przedstawiony w rozdziale pierwszym. Dodatkowo omawiam nowatorską technikę przycinania drzew wykorzystującą zasadę minimalnej długości kodu, MDL – Minimum Description Length (M. Mehta, J. Rissanen, R. Agrawal, 1995).
W rozdziale trzecim i czwartym skupiam się na przedstawieniu indukcji drzew decyzyjnych metodą Supervised Learning in Quest – SLIQ (M. Mehta, R. Agrawal, J. Rissanen, 1996) oraz Scalable Parallelizable Induction of Decision Trees – SPRINT (J.C. Shafer, R. Agrawal, M. Mehta, 1996).
Rozdział piąty prezentuje implementację klasyfikatora SLIQ wraz z implementacją przycinania drzew metodą MDL. Implementację przeprowadziłem we współpracy z Instytutem Podstaw Informatyki Polskiej Akademii Nauk w ramach rozwoju pakietu „dmLab”. Tekst rozdziału zawiera również analizę złożoności czasowej i skalowalności implementacji.
Pracę kończą dodatki A i B, w których zebrałem podstawowe pojęcia wykorzystane w tekście z topologii, teorii miary, probabilistyki oraz teorii grafów.
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
I Am Here – RELEARN – Mariusz Gromada (2024)
I Am Here – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Deep Under – RELEARN – Mariusz Gromada (2024)
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Skalar - kalkulator, funkcje, wykresy i skrypty - Made in Poland
Skalar to potężny silnik matematyczny i matematyczny język skryptowy, który zbudowany jest na bazie MathParser.org-mXparser
Kliknij na wideo i zobacz Skalara w akcji 🙂
Scalar Lite – wersja lite
Scalar Pro – wersja profesjonalna
Kontynuując przeglądanie strony, wyrażasz zgodę na używanie przez nas plików cookies. więcej informacji
Aby zapewnić Tobie najwyższy poziom realizacji usługi, opcje ciasteczek na tej stronie są ustawione na "zezwalaj na pliki cookies". Kontynuując przeglądanie strony bez zmiany ustawień lub klikając przycisk "Akceptuję" zgadzasz się na ich wykorzystanie.