Inverse Transform Sampling to typowy sposób generowania liczb pseudolosowych z zadanego rozkładu, który opiera się na funkcji odwrotnej $F^{-1}$ do dystrybuanty $F$ tego rozkładu. Procedura jest banalna, wystarczy wylosować $Y\sim U(0,1)$ i zwrócić $F^{-1}(Y)$. Niestety nie zawsze łatwe jest wyznaczenie jawnej postaci dystrybuanty, tym bardziej dotyczy to funkcji do niej odwrotnej. Dla przykładu – powszechny rozkład normalny charakteryzuje się funkcją gęstości w postaci „elementarnej”, natomiast jego dystrybuanta (i funkcja do niej odwrotna) wymagają zastosowania funkcji specjalnych – w tym przypadku funkcji błędu Gaussa.
Kiedyś kolega (pozdrowienia Marcin!) pokazał mi nieskomplikowany sposób generacji liczb losowych z rozkładu opisanego histogramem. Zwyczajnie „kładziemy” (skalując) słupki histogramu na odcinek $(0,1)$, losujemy $X\sim U(0,1)$, weryfikujemy „do którego słupka wpadło X”, zwracamy „właśnie ten słupek”. Genialne w swojej prostocie, i działa. Histogram to dyskretna reprezentacja rozkładu, dlatego postanowiłem metodę uogólnić na klasę rozkładów ciągłych opisanych zadaną funkcją gęstości. Otrzymaną metodę nazwałem „MaCDRG-yver” 🙂
Rozkład jednostajny na odcinku $(0,1)$, chyba najprostszy z możliwych rozkładów ciągłych, z pozoru niezbyt interesujący, a jednak 🙂 Dziś ciekawostka wiążąca rozkład sumy rozkładów jednostajnych z liczbą Eulera e.
Rozkład jednostajny ciągły na odcinku (a,b)
Rozkład jednostajny ciągły na odcinku $(a,b)$ jest opisany poniższą funkcją gęstości.
Pisząc $X\sim U(a,b)$ oznaczamy, że zmienna losowa $X$ ma rozkład jednostajny ciągły na odcinku $(a,b)$. Jest to rozkład ciągły, zatem przyjęcie wartości $0$ lub $\frac{1}{b-a}$ w punktach $x=a$ i $x=b$ jest umowne i nie ma zwykle wpływu na własności i rozważania.
Niemal w każdej literaturze z zakresu statystycznej analizy danych, czy też ogólnie analizy danych, spotkać można mniej lub bardziej zaawansowane wykorzystanie terminu zmiennej losowej. Jak sama nazwa wskazuje zmienna losowa stosowana jest typowo tam gdzie zachodzi potrzeba systematyzacji pojęcia cechy losowo obserwowanego obiektu, jego atrybutów, czy też posiadanych własności. Na tym proste intuicje jednak się kończą, szczególnie gdy zaczynamy rozpatrywać rozkłady wskazanych zmiennych, porównując je między sobą, starając się sformułować mniej lub bardziej czytelne wnioski.
Ale o co tak naprawdę chodzi? Dlaczego, w dobie tak szeroko dostępnej informacji w internecie, zdecydowałem się napisać kilka słów o sekretach zmiennych losowych? Motywacja pojawiła się po szeregu rozmów z moimi kolegami po fachu, gdzie okazało się, że jeden wniosek, jedno twierdzenie, często interpretujemy inaczej, może nie diametralnie inaczej, ale jednak pojawiające się różnice dotyczyły fundamentalnych kwestii takich jak „o które prawdopodobieństwo tu chodzi”, czy też „a w jakiej przestrzeni probabilistycznej faktycznie jesteśmy”, lub „jaka jest faktycznie natura zmienności losowej i czego ta zmienność dotyczy”. Zdałem sobie sprawę, że wspomniane różnice wynikają z częstych uproszczeń stosowanych przez autorów różnych opracowań, resztę załatwia pozorna łatwość interpretacji szeregu pojęć, których zrozumienie wymaga wnikliwej obserwacji struktury matematycznych obiektów.
Uwaga – cykl jest refleksją nad modelem probabilistycznym – pewne subtelności można zauważyć dopiero w szczegółach, a jak wiemy z polskiego przysłowia, możemy tam spotkać nawet diabła 🙂
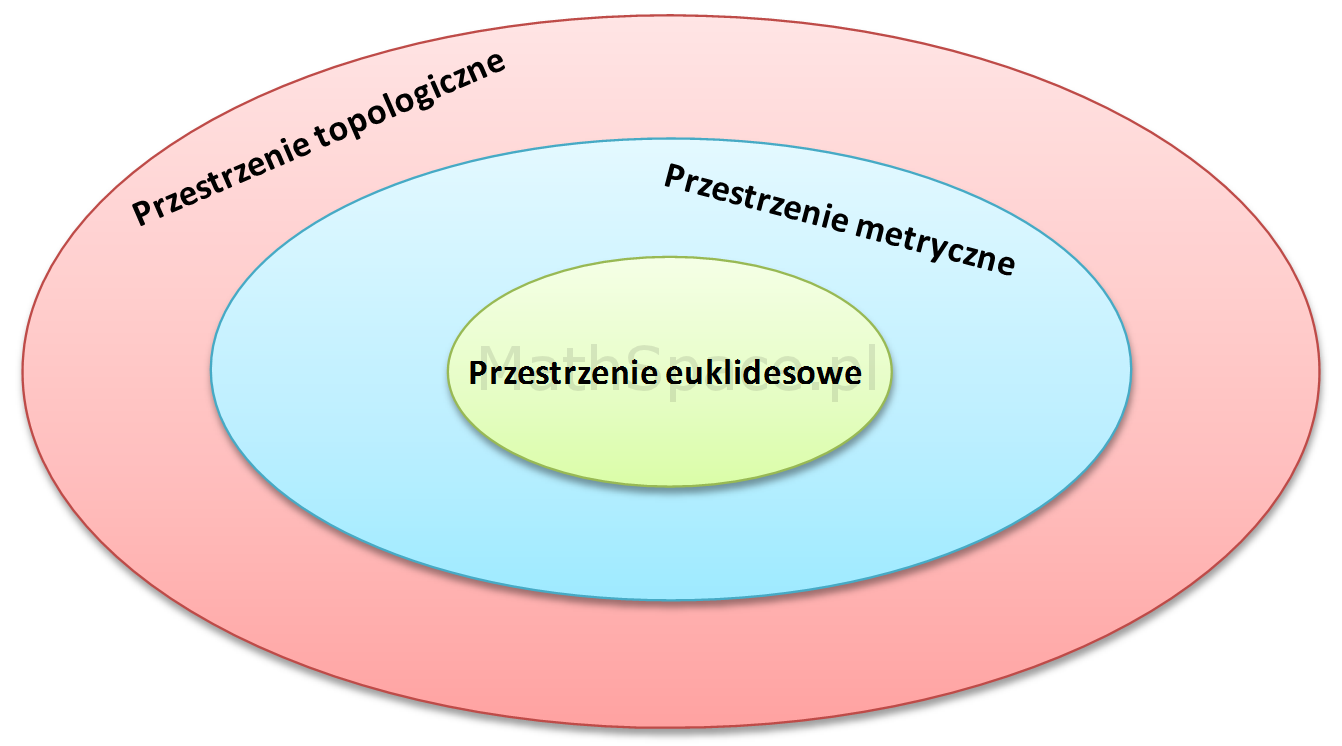
Model probabilistyczny – kilka słów
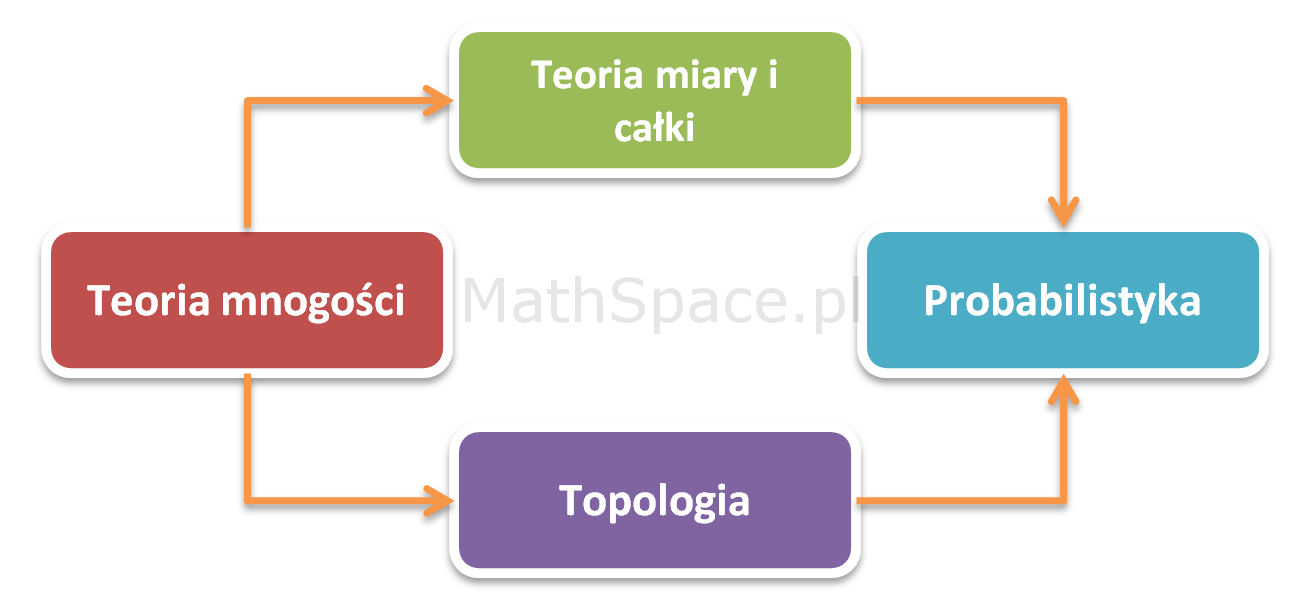
Rozkwit probabilistyki jako teorii był możliwy dzięki osiągnięciom w innych gałęziach matematyki, szczególnie w dziedzinie teorii miary i całki. Należy jednak pamiętać, że u podstaw większości współczesnych dyscyplin leży również teoria mnogości – dział matematyki, a zarazem logiki matematycznej, zapoczątkowany przez niemieckiego matematyka Georga Cantora pod koniec XIX wieku – oraz topologia.
W dzisiejszych czasach każdy matematyk (i nie tylko) w sposób naturalny
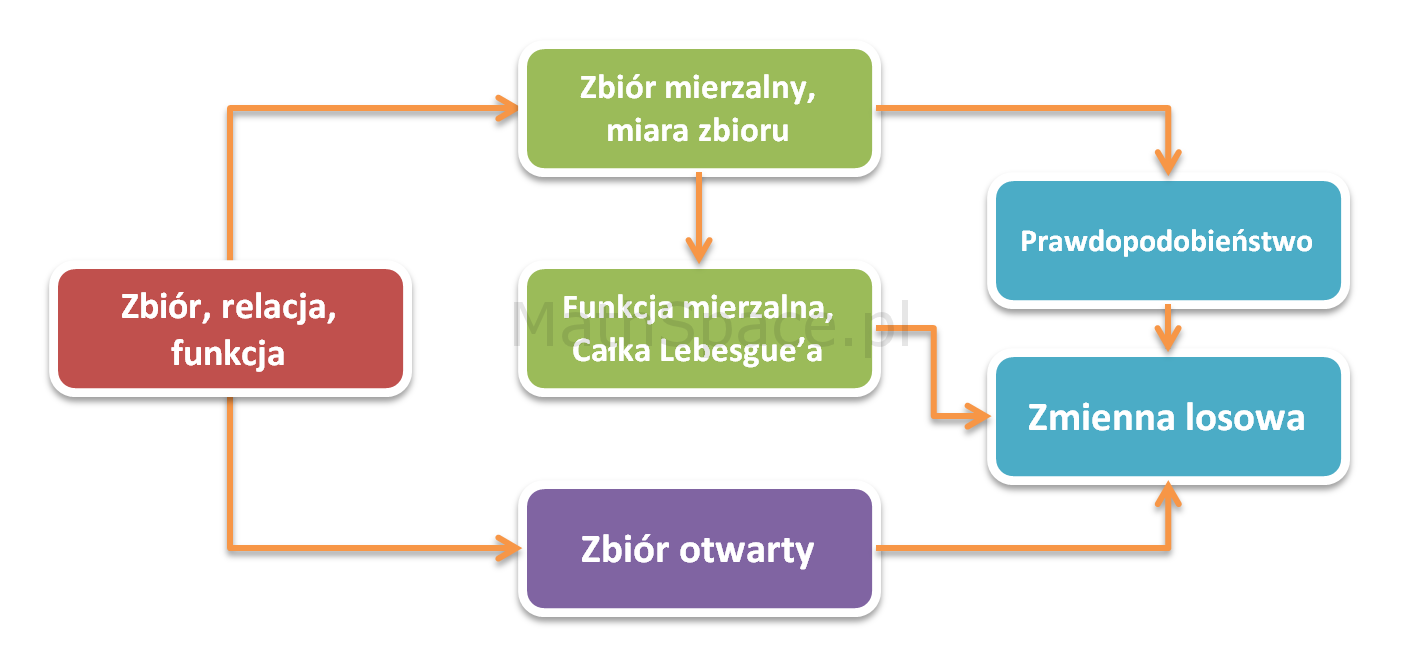
posługuje się takimi terminami jak zbiór, funkcja czy relacja – nic w tym dziwnego – te pojęcia to esencja teorii mnogości zarazem będąca filarem nauk ścisłych. Nietrudno więc o wniosek, że dziedzina dla matematyki jest tym czym fizyka cząstek elementarnych dla większości nauk przyrodniczych. Ponadto okazało się, że wiele własności obiektów studiowanych w analizie matematycznej (np. ciągłość funkcji) może być scharakteryzowanych bardziej uniwersalnie przy użyciu jedynie własności zbiorów otwartych, bez potrzeby odwoływania się do podstawowego pojęcia odległości pomiędzy punktami. W tym miejscu pojawia się topologia, której domeną jest badanie takich zbiorów. Poniżej wymieniam główne pojęcia wykorzystane w rachunku prawdopodobieństwa i należące do wymienionych wyżej bardziej ogólnych gałęzi:
Teoria mnogości
Zbiór
Relacja
Funkcja
Teoria miary i całki
Zbiór mierzalny
Miara zbioru
Funkcja mierzalna
Całka Lebesgue’a
Topologia
Zbiór otwarty
Zbiór borelowski
Probabilistyka
Prawdopodobieństwo
Zmienna losowa
Teoria mnogości, topologia oraz teoria miary i całki to mistrzowsko opracowane dziedziny, które stanowiąc fundament probabilistyki, sprawiają, że ta ostatnia jest jedną z najpiękniejszych dyscyplin w matematyce – uwaga – jest to prywatne zdanie autora! 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Błądzenie losowe jest dosyć podstawowym przykładem procesu stochastycznego. Poniżej wykres 20 błądzeń losowych, każda ścieżka o długości 200. Wszystkie ścieżki rozpoczynają w tym samym punkcie, następnie w każdym kolejnym kroku podejmowana jest losowa decyzja odnośnie kierunku „dół / góra”. Każdy kierunek jest równo prawdopodobny, wybór kierunku w danym kroku nie zależy od decyzji dokonanych poprzednio.
Prawo iterowanego logarytmu
Można zauważyć, że ścieżki pozostają skupione wokół punktu początkowego, jednak średnia odległość od tego punktu rośnie wraz ze wzrostem liczby kroków – co ciekawe – odległość rośnie wolniej niż liniowo, rośnie zgodnie z $\sqrt{n}$. Ogólnie zespół twierdzeń rachunku prawdopodobieństwa opisujących rozmiar fluktuacji w błądzeniu losowym określa się mianem prawa iterowanego logarytmu.
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Ze statystyk odwiedzin wynika, że cykl „Ocena jakości klasyfikacji” cieszy się Waszym zainteresowaniem – zatem wracam do tej tematyki. Dziś przedstawię wstęp do analizy jakości modeli predykcyjnych, skupiając się na jednym tylko aspekcie jakości – tzn. na sile modelu w kontekście separacji klas. Zapraszam 🙂
Jakość modelu predykcyjnego
Matematyka dostarcza wielu różnych miar służących ocenie siły modelu predykcyjnego. Różne miary są często ze sobą mocno powiązane, i choć przedstawiają bardzo podobne informacje, umożliwiają spojrzenie na zagadnienie z innych perspektyw. Przez jakość modelu predykcyjnego rozumiemy typowo ocenę jakości w trzech obszarach:
Analiza siły separacji klas – czyli jak dalece wskazania modelu są w stanie „rozdzielić” faktycznie różne klasy pozytywny i negatywne;
Analiza jakość estymacji prawdopodobieństwa – bardzo ważne w sytuacjach wymagających oceny wartości oczekiwanych, tzn. poszukujemy wszelkiego rodzaju obciążeń (inaczej – błędów systematycznych);
Analiza stabilności w czasie – kluczowy aspekt rzutujący na możliwość wykorzystywania modelu w faktycznych przyszłych działaniach.
Wszystkie wymienione obszary są ze sobą powiązane terminem prawdopodobieństwa, za pomocą którego można wyrazić zarówno siłę separacji, jak też stabilność w czasie.
Założenia
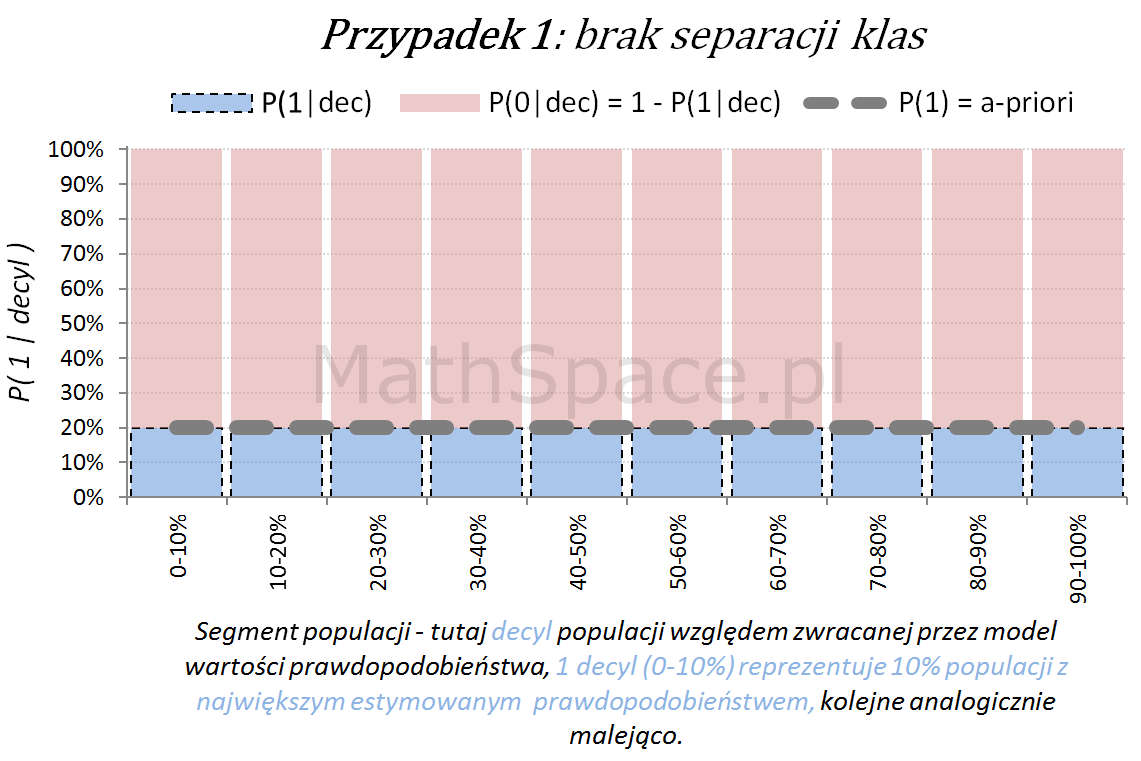
Podobnie do poprzednich część cyklu załóżmy, że rozważamy przypadek klasyfikacji binarnej (dwie klasy: „Pozytywna – 1” oraz „Negatywna – 0”). Załóżmy ponadto, że dysponujemy modelem predykcyjnym $p$ zwracającym prawdopodobieństwo $p(1|x)$ przynależności obserwacji $x$ do klasy „Pozytywnej -1” (inaczej „P od 1 pod warunkiem, że x”). I jeszcze ostatnie założenie, wyłącznie dla uproszczenia wizualizacji i obliczeń – dotyczy rozmiaru klasy pozytywnej – ustalmy, że jej rozmiar to 20%, inaczej, że prawdopodobieństwo a-priori P(1)=0.2.
Model predykcyjny a siła separacji klas – nieskumulowane prawdopodobieństwo
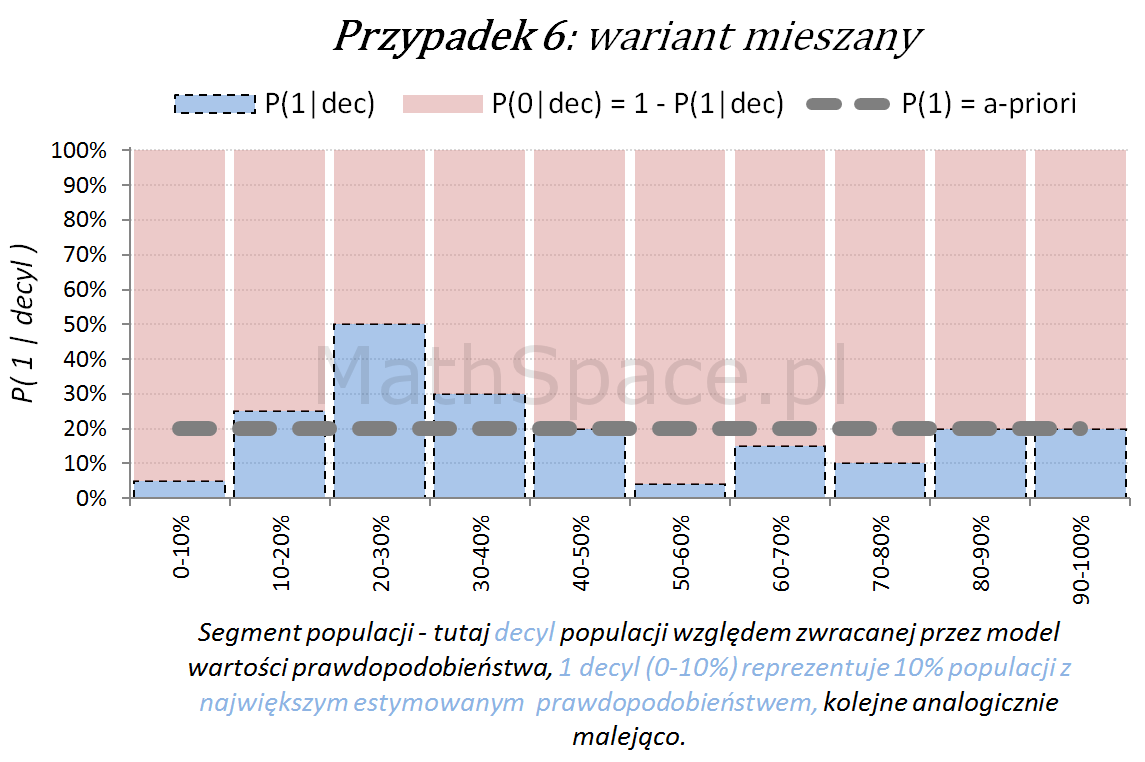
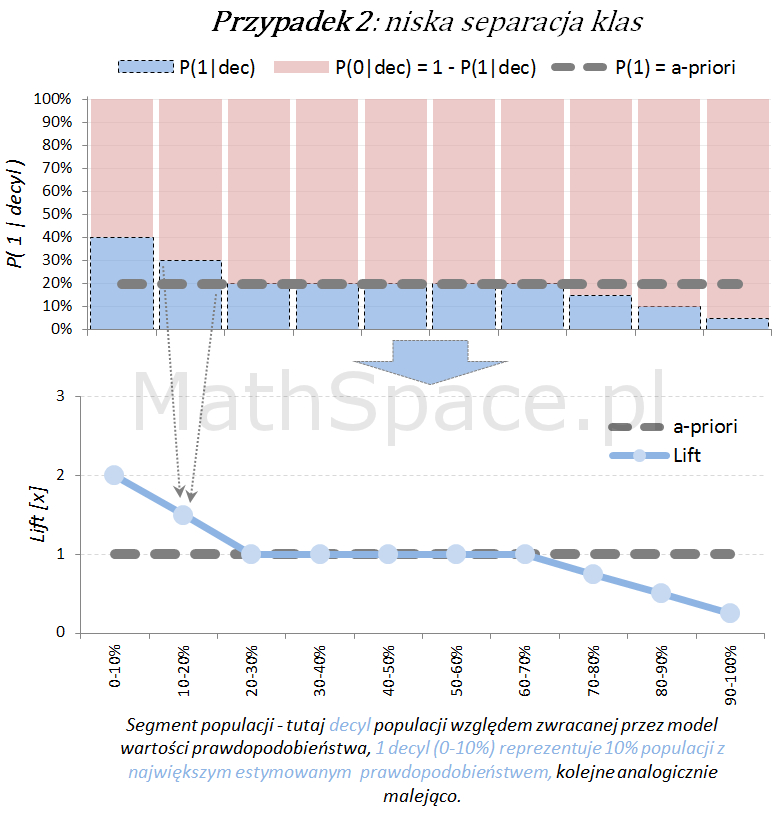
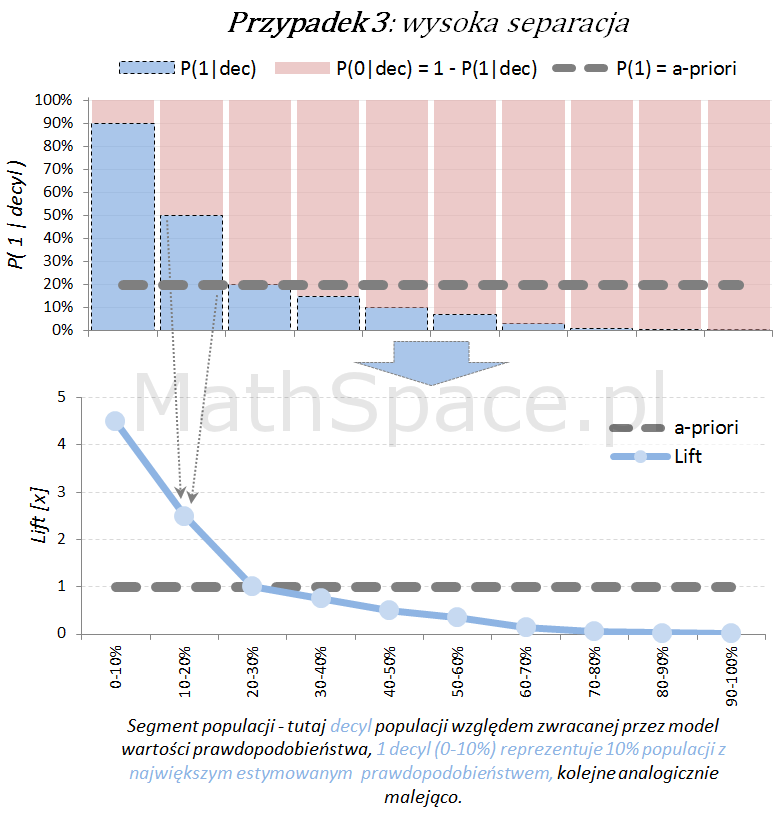
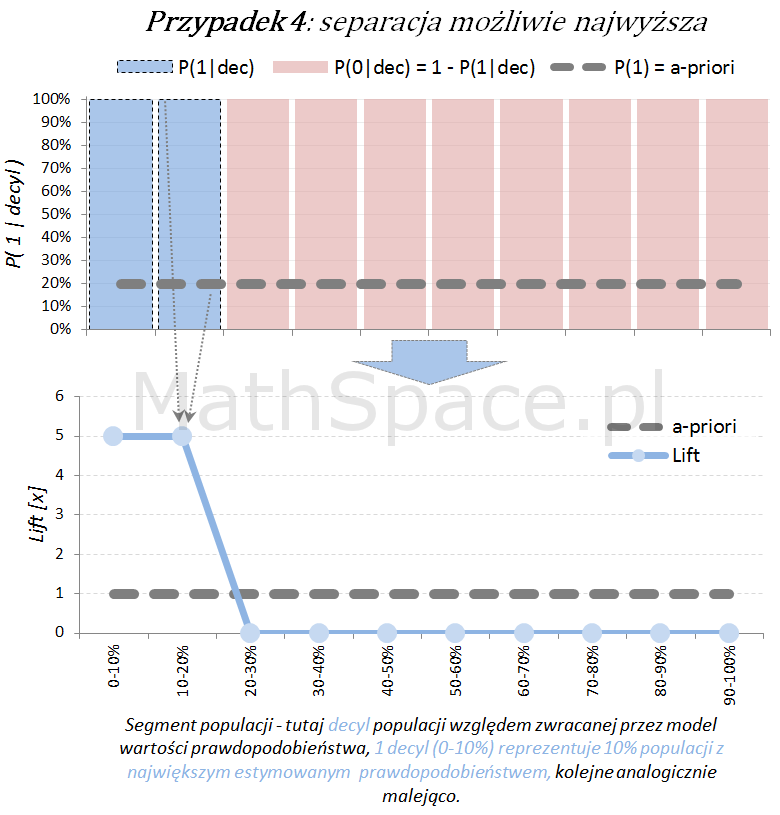
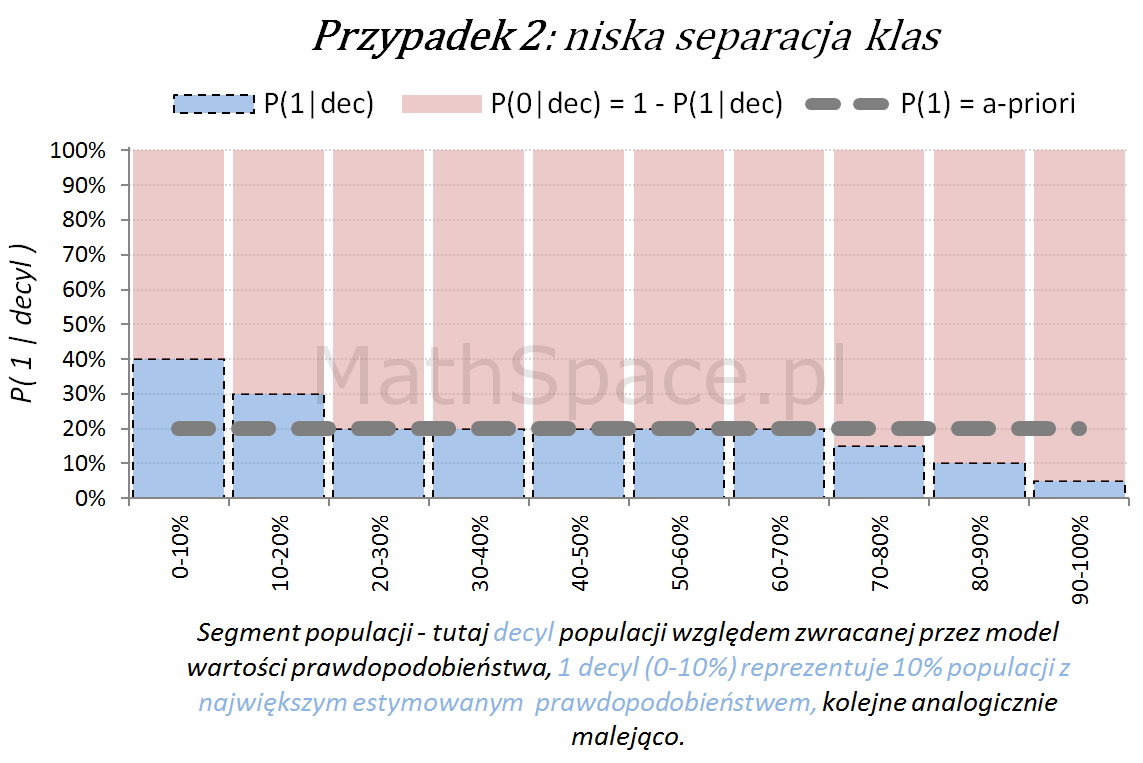
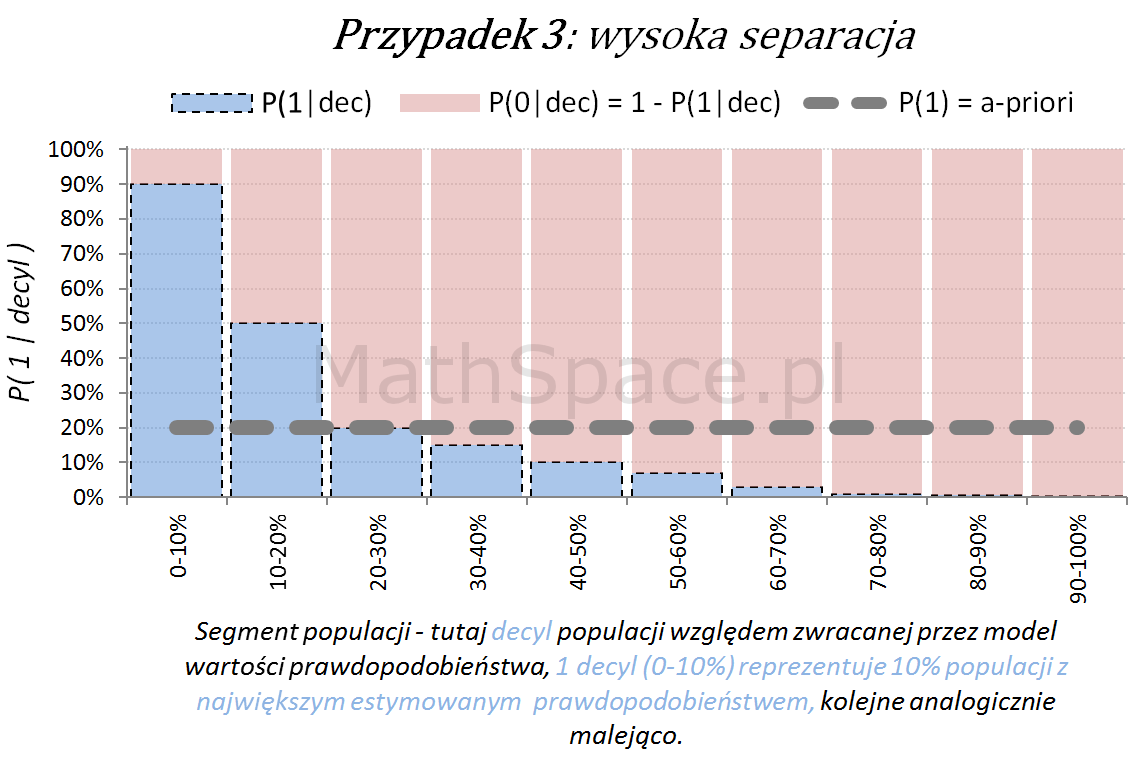
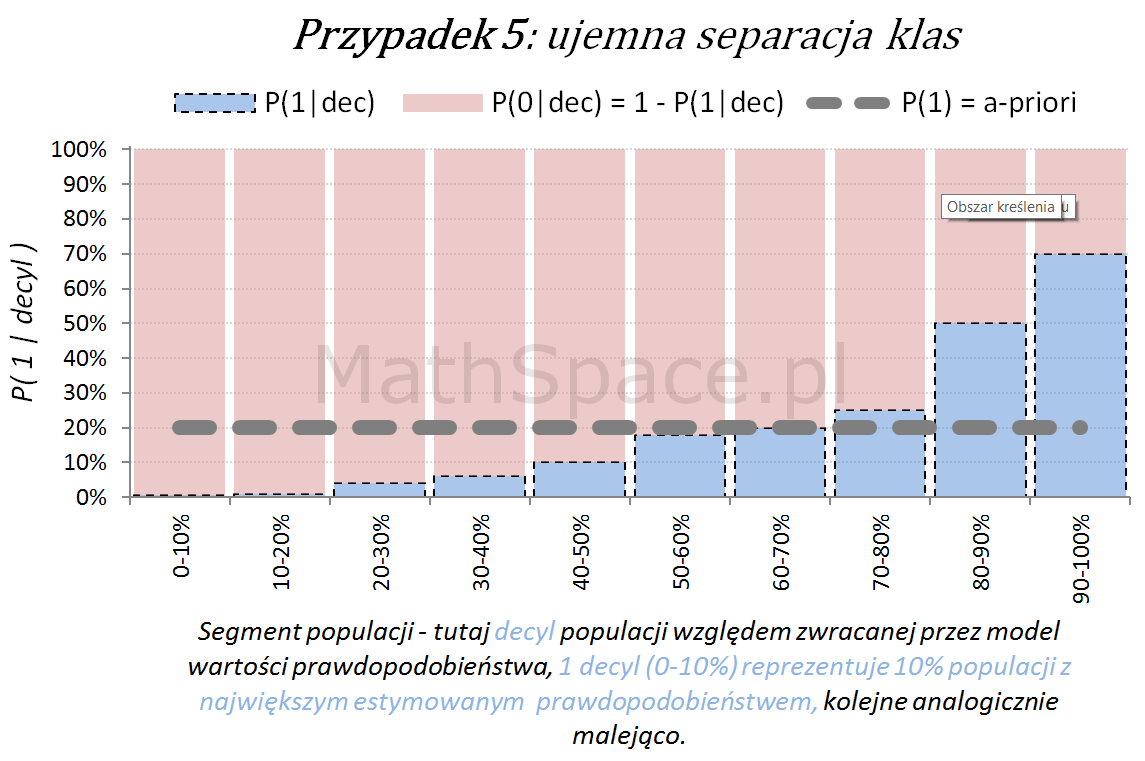
Poniżej przedstawiamy różne przypadki wizualnej oceny siły modelu. Interpretacja zamieszczonych wykresów jest następująca:
Oś pozioma reprezentuje kolejne segmenty populacji, tu zostały użyte decyle bazy względem zwracanej wartości prawdopodobieństwa przez model. Zatem 1 decyl agreguje 10% populacji z największym estymowanym prawdopodobieństwem, kolejne decyle – analogicznie.
Oś pionowa przedstawia prawdopodobieństwo warunkowe, że obserwacja z danego segmentu populacji (tutaj decyl bazy) faktycznie pochodzi z klasy „Pozytywnej – 1”.
Naturalnym jest, że model predykcyjny posiadający dodatnią siłę separacji klas, wykorzystany do podziału populacji na segmenty względem wartości malejącej (tutaj 10 decyli), powinien wpłynąć na faktyczną częstość obserwacji klasy „Pozytywnej – 1”. Tzn. w pierwszych decylach powinniśmy widzieć więcej klasy „1” – kolejne przykłady właśnie to obrazują.
Dla każdego przypadku klasyfikacji istnieje również teoretyczny model idealny, z możliwie najwyższą siłą separacji klas. Tak model się „nie myli”, co obrazuje poniższy schemat.
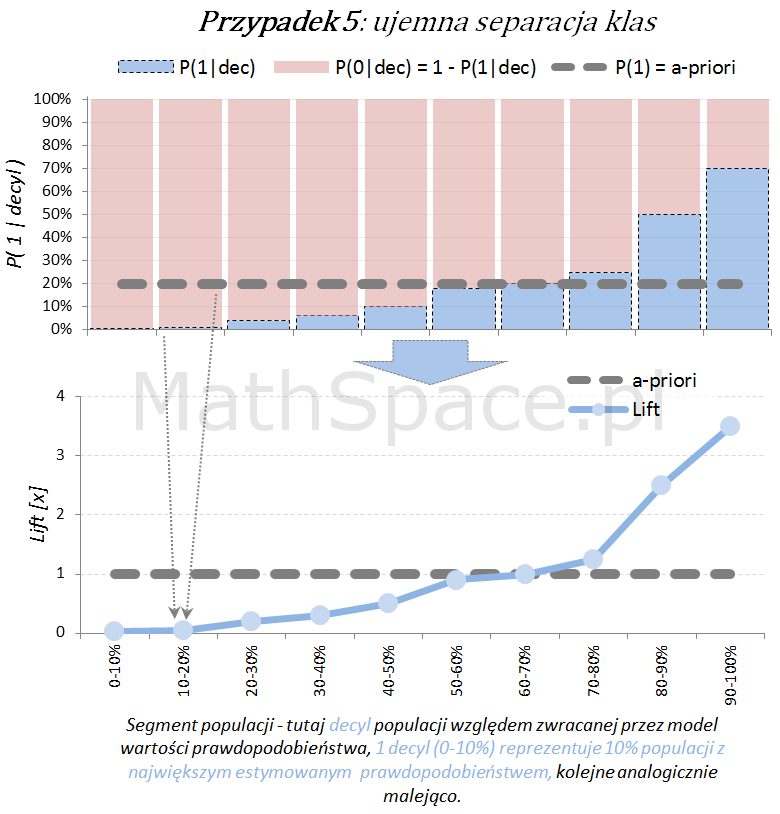
Inne „nietypowe” przypadki (jednak czasami spotykane w praktyce) to modele z ujemną korelacją w stosunku do targetu.
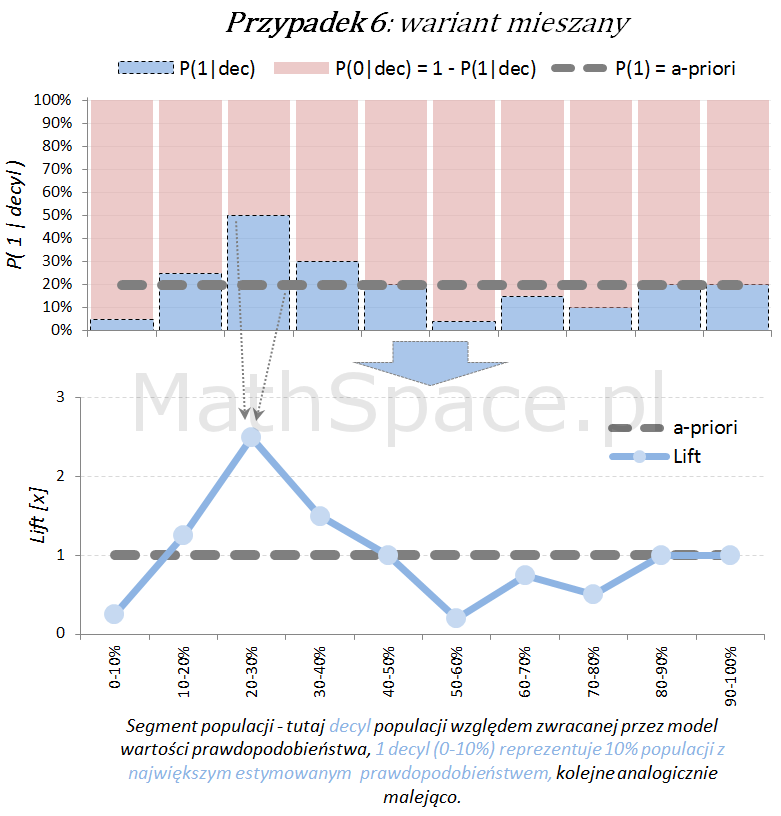
Ostatecznie możliwy jest również wariant „mieszany”, obserwowany często po długim czasie wykorzystywania modelu, bez jego aktualizacji, w wyniku zmian w danych, błędów w danych, zmian definicji klas (tzw, targetu), itp.
Model predykcyjny a siła separacji klas – nieskumulowany lift
Lift jest normalizacją oceny prawdopodobieństwa do rozmiaru klasy pozytywnej, czyli do rozmiaru reprezentowanego przez prawdopodobieństwo a-priori $P(1)$. Lift powstaje przez podzielenie wartości prawdopodobieństwa właściwej dla segmentu przez prawdopodobieństwo a-priori. W ten sposób powstaje naturalna interpretacja liftu, jako krotności w stosunku do modelu losowego (czyli modeli bez separacji klas):
lift < 1 – mniejsza częstość „klasy 1” niż średnio w populacji
lift = 1 – częstość „klasy 1” na średnim poziomie dla populacji
lift > 1 – większa częstość „klasy 1” niż średnio w populacji
Poniżej prezentacja graficzna
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
W poprzednich częściach omówiliśmy sposób tworzenia macierzy błędu oraz podstawowe miary oceny jakości klasyfikacji: czułość (TPR), specyficzność (TNR), precyzję przewidywania pozytywnego (PPV), precyzję przewidywania negatywnego (NPV). Opisane miary określone są dla klasyfikatora binarnego (klasyfikacja pozytywna bądź negatywna), jednak w praktyce najczęściej stosuje się modele predykcyjne z ciągłą zmienną odpowiedzi (np. estymator prawdopodobieństwa skorzystania z produktu, gdzie wynikiem działania modelu jest wartość z przedziału [0, 1] interpretowana właśnie jako wspomniane prawdopodobieństwo określane również skłonnością).
Model predykcyjny
Dla lepszego zrozumienia załóżmy, że analizujemy bazę $n$-klientów oznaczonych odpowiednio $x_1, x_2, \ldots, x_n$. Model predykcyjny to np. funkcja (estymator) zwracająca dla każdego klienta właściwe dla niego prawdopodobieństwo zakupienia produktu – oznaczmy więc fakt zakupienia produktu klasą pozytywną „1”. Teraz możemy podać bardziej formalne określenie – zatem model predykcyjny to estymator prawdopodobieństwa warunkowego $p(1|x_i)$, że wystąpi zakup produktu (klasa „1”), pod warunkiem, że zaobserwujemy cechy klienta $x_i$.
Obserwacja cech klienta, a nie samego klienta, jest tu niezwykle istotna. Mianowicie danego klienta mamy dokładnie jednego, natomiast klientów o tych samych / podobnych cechach (np. miejsce zamieszkania, wiek, itp.) możemy posiadać wielu, co dalej umożliwia wnioskowanie indukcyjne, a w wyniku otrzymanie upragnionego modelu 🙂 .
Segment wysokiej skłonności
Typowo mniejszość klientów charakteryzuje się „wysoką” skłonnością, natomiast „średnia” i „niska” skłonność jest przypisywana do znacznie większej części bazy. Łatwo to uzasadnić – zazwyczaj w określonym okresie czasu produkt kupuje maksymalnie kilka procent bazy klientów. Jeśli model predykcyjny posiada faktyczną wartość predykcyjną, wysokie prawdopodobieństwo przypisze do relatywnie niewielkiej części klientów. Idąc dalej – im lepszy model, tym segment o wysokiej skłonności jest mniejszy i bliższy rozmiarem do oszacowania pochodzącego ze średniej sprzedaży mierzonej dla całej analizowanej bazy klientów (tzw. oszacowanie a-priori).
Punkt odcięcia (cut-off point)
Zadaniem punktu odcięcia jest stworzenie na bazie ciągłej zmiennej odpowiedzi (np. szacowanego prawdopodobieństwa) segmentów (klas) – dla uproszczenia załóżmy, że dwóch (jeden punkt odcięcia). Oznaczmy przez $p_0 \in [0;1]$ punkt rozgraniczający segment wysokiej skłonności od segmentów średniej i niskiej skłonności. Jeśli szacowane prawdopodobieństwo $p(1|x_i) \geq p_0$ klientowi $x_i$ przypiszemy klasę pozytywną „1”, w przeciwnym wypadku klientowi przypisujemy klasę negatywną „0”.
W powyższy sposób z „ciągłego” modelu predykcyjnego otrzymaliśmy klasyfikator binarny – co, w zestawieniu z faktycznymi zdarzeniami zakupu, umożliwia utworzenie macierzy błędu i wyznaczenie wszystkich istotnych miar oceny jakości dokonanej klasyfikacji.
Ale jak dobrać punkt odcięcia? O tym w następnej części 🙂
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Osiągnięcia matematyczne są tym większe im bardziej uogólnione rezultaty są przedstawiane. Teorie matematyczne zawsze dążą do systematyzowania i generalizowania pojęć, umożliwiając ich aplikację w znacznie szerszej klasie problemów. Przykładowo matematyk nie zgłosi trudności z wyobrażeniem sobie 4 wymiarów, zwyczajnie analizuje n-wymiarów i podstawia n = 4 🙂 .
Teoria miary i całki
Jednym z ciekawszych przejawów tego trendu jest teoria miary i całki, która wyrosła z potrzeby ujednolicenia pod pojęciem rozmiaru zbioru jego długości, pola powierzchni, czy też objętości. Nową dziedzinę matematyki zaproponował na początku XX wieku Henri Lebesgue swoimi pracami na temat całki.
Podstawowe własności miary
Zastanawiając się jakie cechy powinna posiadać „dobra” funkcja miary najlepiej jest rozważać wspomniane wyżej „miary” naturalne takie jak: objętość, długość, waga. Dobrze skalibrowana waga nigdy nie pokazuje wartości ujemnych. Taka waga powinna wskazać zero jeżeli nic nie ważymy. Ponadto, jeżeli ważmy różne produkty, oczekujemy łącznej wagi równej sumie wag poszczególnych produktów. Idąc jeszcze dalej, jeśli podzielimy ważony element na części, które można zważyć, również oczekujemy zgodności odpowiednich pomiarów.
Co możemy mierzyć
Na tym etapie rozważmy dowolny niepusty zbiór $\Omega$. Mówiąc o pomiarach na zbiorze $\Omega$ będziemy myśleli o pomiarach na jego podzbiorach $\big(\Omega$ jest „maksymalnym” zbiorem podlegającym pomiarowi – np. może to być cała płaszczyzna $\mathbb{R}^2\big)$ – niech zatem $\mathfrak{F}$ oznacza rodzinę mierzalnych podzbiorów zbioru $\Omega$. Od takiej rodziny mierzalnych zbiorów oczekujemy spełnienia jedynie 3 warunków:
Możemy zmierzyć „nic” – tzn. zbiór pusty jest mierzalny, co zapiszemy $\emptyset \in \mathfrak{F}$
Jeżeli możemy zmierzyć zbiór $A$, możemy również zmierzyć to co pozostało (tzn. $\Omega \setminus A$), co zapisujemy $\big(A \in \mathfrak{F} \big) \Rightarrow \big( \Omega \setminus A \in \mathfrak{F} \big)$
Jeśli dysponujemy wieloma zbiorami, które można zmierzyć, to o ile można je ponumerować, również można zmierzyć ich sumę, co zapisujemy $\big(A_i \in \mathfrak{F}$ dla $i=1,2,\ldots \big) \Rightarrow \bigg(\displaystyle \bigcup_{i =1}^\infty A_i \in\mathfrak{F}\bigg)$
Powyższe warunki (i ich konsekwencje) określają jakiego typu podzbiory przestrzeni $\Omega$ mogą zostać zmierzone. Oczekuje się, że jeżeli można zmierzyć podzbiór, to można również zmierzyć jego dopełnienie. Jeżeli można zmierzyć wiele podzbiorów przestrzeni, można również zmierzyć ich sumę, jak też ich część wspólną. Ponadto, jeżeli można zmierzyć dwa dowolne podzbiory przestrzeni, można również zmierzyć ich różnicę. W szczególności zakłada się, że możliwe jest dokonanie pomiaru na zbiorze pustym, jak też na całej przestrzeni.Rodziny $\mathfrak{F}$ podzbiorów zbioru $$\Omega$$ spełniające powyższe warunki nazywa się sigma-ciałami.
Funkcja miary zbioru
Miarą zbioru nazwiemy funkcję, która każdemu zbiorowi, który można zmierzyć (elementy sigma-ciała), przyporządkuje wartości liczbowe (również nieskończoność) spełniające poniższe 3 warunki:
Miara zbioru ($\mu$) nie przyjmuje wartości ujemnych, ale może być zerowa, co zapisujemy $\forall ~A \in \mathfrak{F}$, $\mu(A) \mathfrak{\geq} 0$
Miara „nic” jest zawsze równa 0, co zapisujemy $\mu(\emptyset)=0$
Jeśli podzielimy zbiór na rozłączne części, to miara zbioru jest równa sumie miar jego części, co zapisujemy $\big( A_i \cap A_j = \emptyset \quad \mathrm{dla} \quad i \ne j \big) \Rightarrow \Bigg( \mu \bigg(\bigcup_{i = 1}^\infty A_i \bigg) = \sum_{i = 1}^\infty \mu(A_i) \Bigg)$
Powyższe warunki są wystarczające, aby funkcja miary zbioru dodatkowo spełniała poniższe:
Miara podzbioru jest nie większa niż miara wyjściowego zbioru, co zapisujemy $\big( A \subseteq B \big)$ $\Rightarrow$ $\big( \mu(A) \leq \mu(B) \big)$
Dodatkowo $\big( A \subseteq B \big)$ $\wedge$ $\big( \mu(B) < +\infty \big)$ $\Rightarrow$ $\big( \mu(B \setminus A) = \mu(B) – \mu(A) \big)$
Miara zbioru (i ogólnie mierzalność) jest zupełnie podstawowym pojęciem w probabilistyce, to właśnie na przestrzeniach mierzalnych oparty jest cały model probabilistyczny, a w konsekwencji też model statystyczny. Wykorzystując okazję serdecznie polecam niesamowitą książkę Patrick’a Billingsley’a pod tytułem „Prawdopodobieństwo i miara”.
Miara Lebesgue’a
W kolejnych artykułach przedstawimy miarę Lebesgue’a, która stanowi podstawę określania rozmiarów zbiorów w przestrzeniach euklidesowych.
Pozdrawiam,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
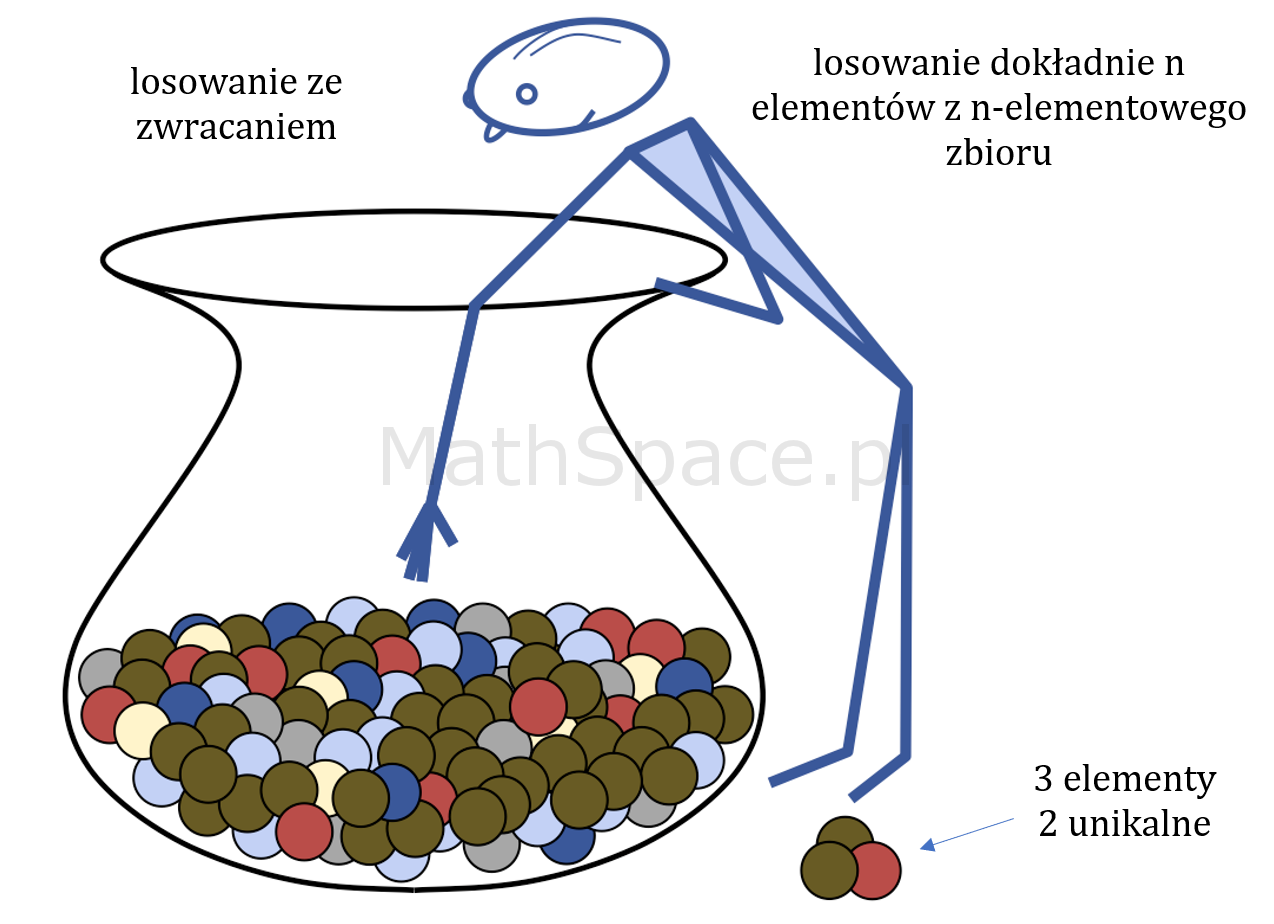
Jakiś czas temu rozważałem problem losowania ze zwracaniem dokładnie $n$-elementów z $n$-elementowego zbioru (dla uściślenia w zbiorze wyjściowym znajduje się dokładnie $n$ różnych elementów). W wyniku takiej operacji, w wylosowanej próbie, mogą pojawić się duplikaty – załóżmy zatem, że otrzymaliśmy $k$ unikalnych rezultatów (oczywiście $1\leq k\leq n$). Naturalnie pojawia się pytanie kombinatoryczne.
Ile istnieje sposobów takiego wylosowania (ze zwracaniem) $n$ elementów spośród $n$-elementowego zbioru, że w wyniku otrzymamy dokładnie $k$ unikalnych rezultatów?
Liczba sposobów otrzymania k-unikalnych rezultatów
Liczbę takich sposobów oznaczmy przez $B_n^k$.
„Kombinowanie” czas start! Początkowo wyszedłem od losowania $k$ różnych elementów, w kolejnym kroku planując losowanie $n-k$ z wylosowanych wcześniej $k$. Tego typu podejście prowadziło do bardzo skomplikowanych rozważań, szczegóły pominę. Na rozwiązanie wpadłem po około 2 dniach.
Wariacja bez powtórzeń
Pierwszy krok – liczba sposobów wyboru $k$ różnych elementów z $n$ zwracając uwagę na kolejność – jest to wariacja bez powtórzeń $V_n^k$.
$$V_n^k=\frac{n!}{(n-k)!}$$
Liczba Stirlinga II rodzaju
Drugi krok – zapominamy, że właśnie wylosowaliśmy $k$ unikalnych i należy jeszcze dolosować $n-k$ (choć to prawda). W zamian ustalamy, że mamy już $n$, w tym $k$ unikalnych. Trick polega na zauważeniu, że mając $k$ różnych elementów w zbiorze $n$-elementowym, dokonaliśmy jego podziału na $k$-podzbiorów.
Ile mamy sposobów podziału $n$-elementowego zbioru na $k$ podzbiorów? Jest to właśnie liczba Stirlinga II rodzaju oznaczona $S_2(n,k)$. Zatem finalnie
Dlaczego w kroku pierwszym zwracałem uwagę na kolejność? Chętnych zapraszam do komentowania 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
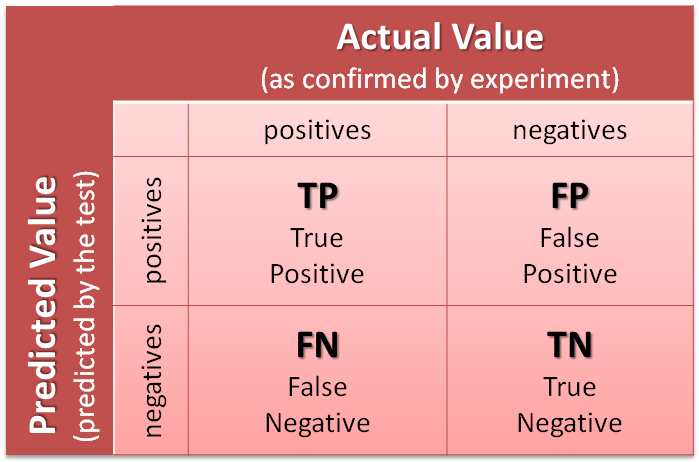
Macierz błędu jest podstawowym narzędziem stosowanym do oceny jakości klasyfikacji. Poniżej rozważymy przypadek klasyfikacji binarnej (dwie klasy). Kodowanie klas:
1 – Positive (np.: fakt skorzystania z produktu przez Klienta, pacjent z potwierdzoną chorobą, pacjentka z potwierdzoną ciążą)
0 – Negative (np.: fakt nieskorzystania z produktu przez Klienta, pacjent z wykluczoną chorobą, pacjentka z wykluczoną ciążą)
Możliwe wyniki klasyfikacji
Macierz błędu powstaje z przecięcia klasy prognozowanej i klasy faktycznie zaobserwowanej, mamy zatem 4 przypadki (2 dla zgodności i 2 dla niezgodności prognozy ze stanem faktycznym).
True-Positive(TP– prawdziwie pozytywna): przewidywanie pozytywne, faktycznie zaobserwowana klasa pozytywna (np. pozytywny wynik testu ciążowego i ciąża potwierdzona)
True-Negative(TN– prawdziwie negatywna): przewidywanie negatywne, faktycznie zaobserwowana klasa negatywna (np. negatywny wynik testu ciążowego i brak ciąży)
False-Positive(FP– fałszywie pozytywna): przewidywanie pozytywne, faktycznie zaobserwowana klasa negatywna (np. pozytywny wynik testu ciążowego, jednak faktyczny brak ciąży)
False-Negative(FN– fałszywie negatywna): przewidywanie negatywne, faktycznie zaobserwowana klasa pozytywna (np. negatywny wynik testu ciążowego, jednak ciąża potwierdzona)
Confusion Matrix
Stan faktyczny
P
N
Przewidywanie
P
TP True-Positive
FP False-Positive
N
FN False-Negative
TN True-Negative
Przykład – do grupy 2000 osób skierowano komunikację marketingową zachęcającą do skorzystania z produktu. Spośród 2000 osób produkt zakupiło 600. Grupę 2000 podzielono losowo na dwie równoliczne części, każda po 1000 osób (w tym w każdej po 300 klientów, którzy skorzystali z produktu). Pierwszej grupie przydzielono rolę „danych uczących”, zaś drugiej rolę „danych testowych”. Wykorzystując dane uczące, dostępne charakterystyki klientów oraz informacje o fakcie zakupienia produktu (tzw. target), przygotowano (wytrenowano / nauczono) klasyfikator umożliwiający przewidywanie czy dany klient skorzysta z produktu. Oceny jakości klasyfikatora dokonano przy wykorzystaniu danych testowych (tzn. danych, które nie były używane w procesie uczenia). Wyniki oceny zaprezentowano w postaci poniższej macierzy błędów.
Confusion Matrix dla powyższego przykładu
Stan faktyczny
P
N
Przewidywanie
P
250 True-Positive
100 False-Positive
N
50 False-Negative
600 True-Negative
Wnioski:
TP + FN + TN + FP = 250 + 50 + 600 + 100 = 1000 – liczba klientów (baza, na której dokonano oceny)
P = TP + FN = 250 + 50 = 300 – liczba klientów, którzy kupili produkt
N = TN + FP = 600 + 100 = 700 – liczba klientów, którzy nie skorzystali z produktu
TP + TN = 250 + 600 = 850 – liczba poprawnych klasyfikacji
FP + FN = 100 + 50 = 150 – liczba błędnych klasyfikacji
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Zarządzaj zgodą
Aby zapewnić jak najlepsze wrażenia, korzystamy z technologii, takich jak pliki cookie, do przechowywania i/lub uzyskiwania dostępu do informacji o urządzeniu. Zgoda na te technologie pozwoli nam przetwarzać dane, takie jak zachowanie podczas przeglądania lub unikalne identyfikatory na tej stronie. Brak wyrażenia zgody lub wycofanie zgody może niekorzystnie wpłynąć na niektóre cechy i funkcje.
Funkcjonalne
Zawsze aktywne
Przechowywanie lub dostęp do danych technicznych jest ściśle konieczny do uzasadnionego celu umożliwienia korzystania z konkretnej usługi wyraźnie żądanej przez subskrybenta lub użytkownika, lub wyłącznie w celu przeprowadzenia transmisji komunikatu przez sieć łączności elektronicznej.
Preferencje
Przechowywanie lub dostęp techniczny jest niezbędny do uzasadnionego celu przechowywania preferencji, o które nie prosi subskrybent lub użytkownik.
Statystyka
Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do celów statystycznych.Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do anonimowych celów statystycznych. Bez wezwania do sądu, dobrowolnego podporządkowania się dostawcy usług internetowych lub dodatkowych zapisów od strony trzeciej, informacje przechowywane lub pobierane wyłącznie w tym celu zwykle nie mogą być wykorzystywane do identyfikacji użytkownika.
Marketing
Przechowywanie lub dostęp techniczny jest wymagany do tworzenia profili użytkowników w celu wysyłania reklam lub śledzenia użytkownika na stronie internetowej lub na kilku stronach internetowych w podobnych celach marketingowych.
Cześć, z tej strony Mariusz Gromada, autor bloga MathSpace.pl.
Znacie mnie z tekstów o nauce i matematyce. Równolegle – od ponad 20 lat – zajmuję się projektowaniem, wdrażaniem oraz wykorzystywaniem wielkoskalowych systemów personalizacji w organizacjach B2C. Tę podwójną perspektywę – analityczno-inżynierską i biznesową – zebrałem w mojej najnowszej książce:
„Customer First, Value Next: The Executive Playbook for AI-Driven Omnichannel Personalization and Customer-Centric Growth.”
Jeśli jesteś liderem biznesowym, liderem technologicznym, inżynierem, analitykiem lub po prostu fascynuje Cię budowa skalowalnych systemów AI, które potrafią zrozumieć klienta – odchodząc od tradycyjnego modelu produktowego – to ta pozycja jest dla Ciebie.
„Technologia to nie tylko narzędzie do automatyzacji. To megafon dla empatii.”





 Ostatecznie możliwy jest również
Ostatecznie możliwy jest również