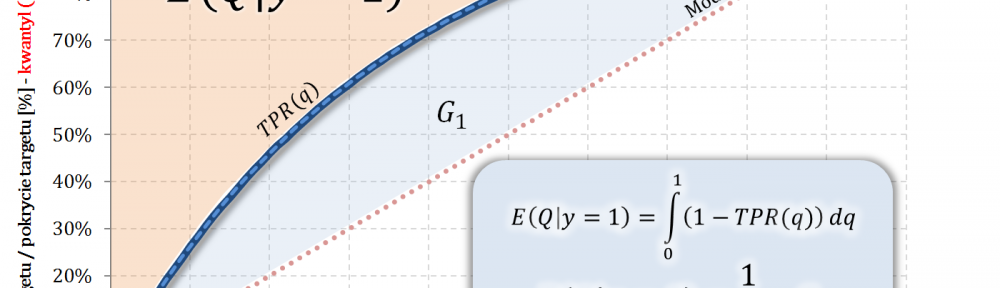Prelekcja wygłoszona w dniu 25.04.2017 podczas Konferencji Big Data – Bigger opportunities – zapraszam.
Omówione zagadnienia:
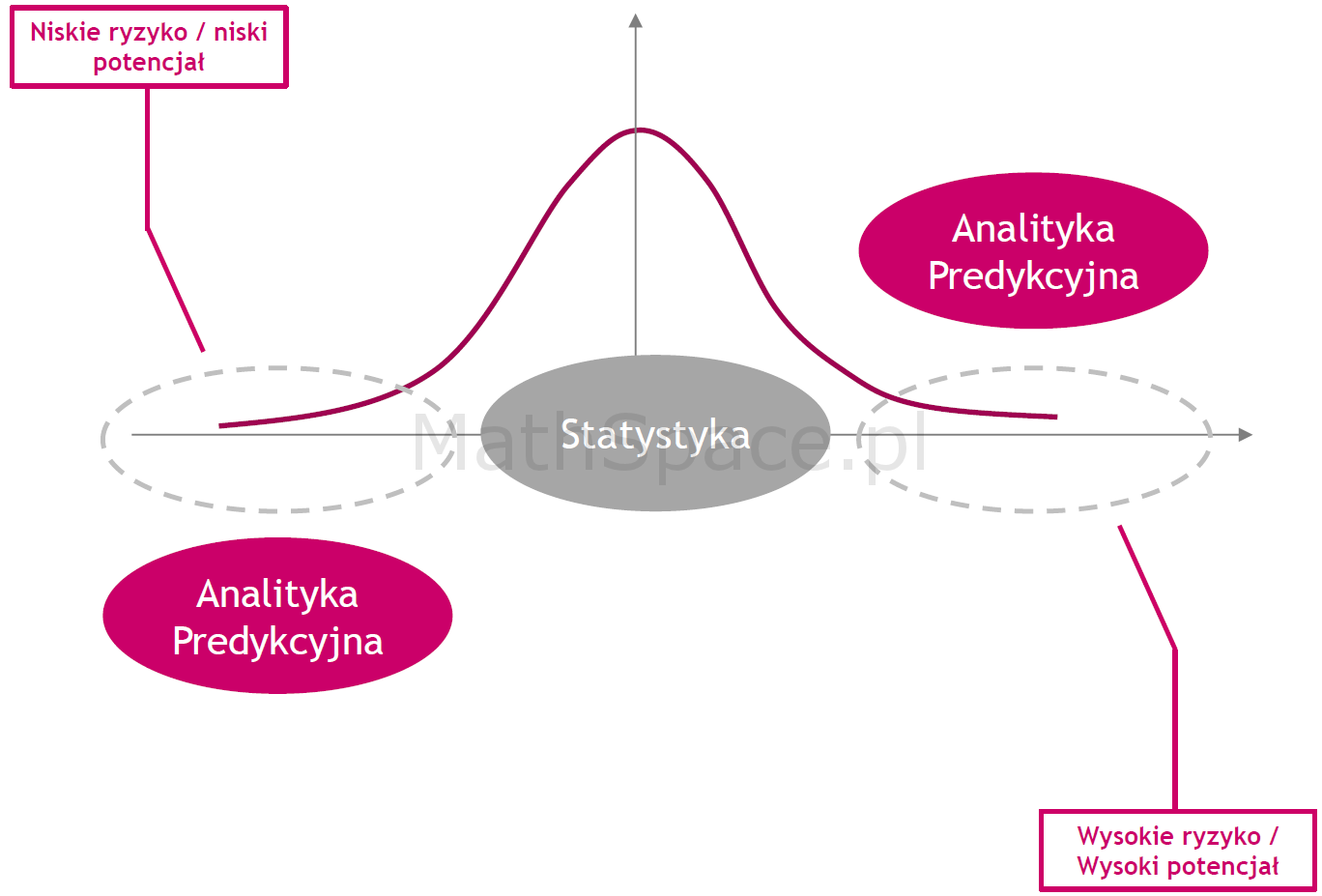
Analityka Predykcyjna
Model Predykcyjny
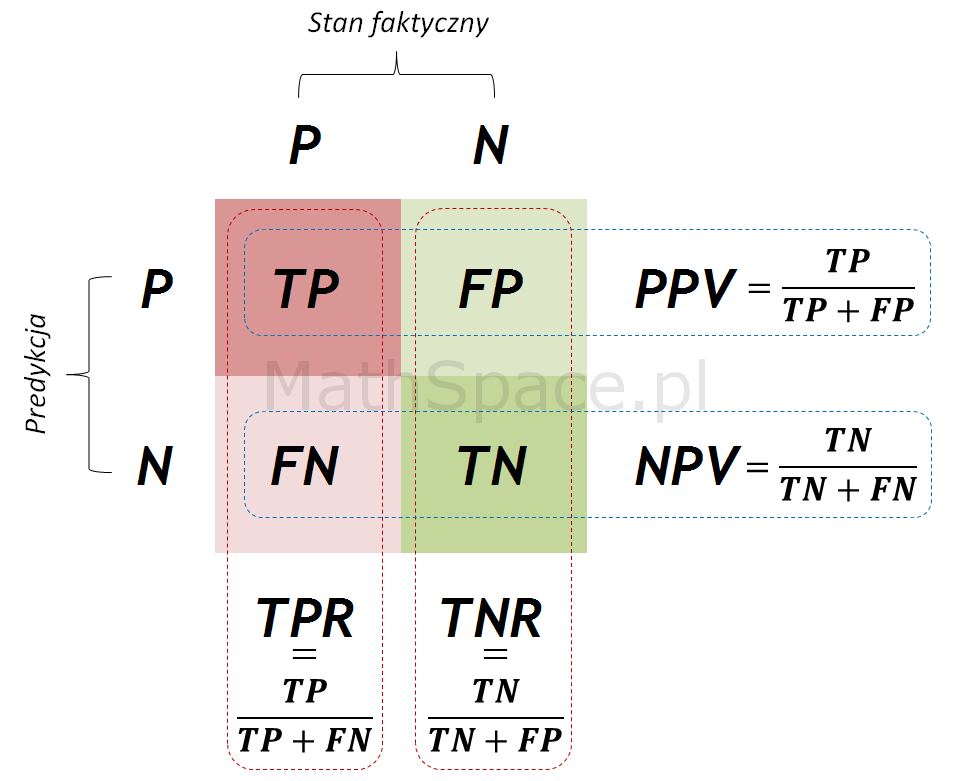
Confusion Matrix / Macierz błędu
Strategie doboru punktu odcięcia
Ocena jakości klasyfikacji
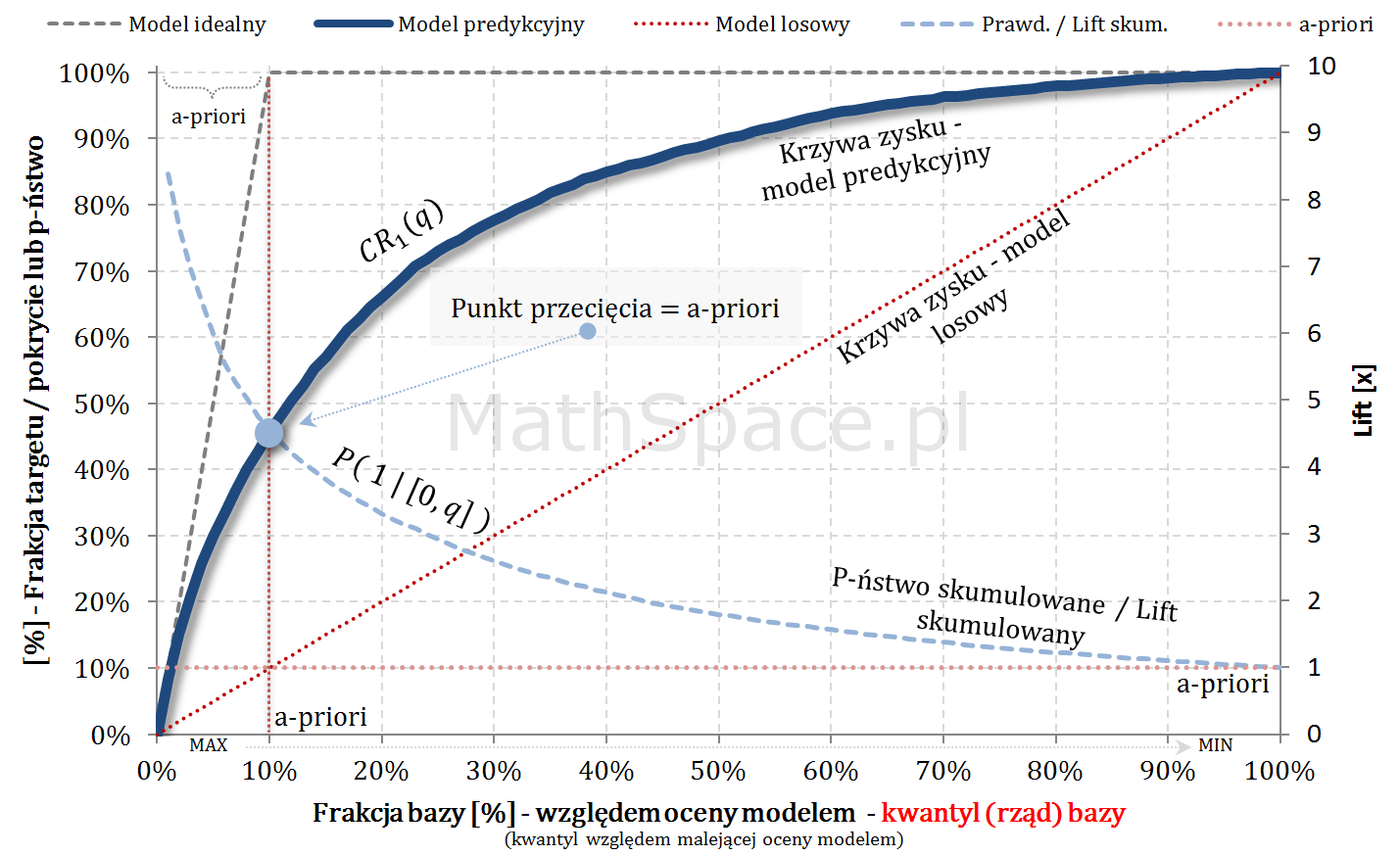
Krzywa zysku
Krzywa Lift
Krzywa ROC i wskaźnik Giniego
Krzywa Zysku vs ROC – równoważność?
Modele teoretycznie idealne
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Prelekcja wygłoszona w dniu 15.10.2015 podczas IV Konferencji Customer Intelligence – zapraszam.
Omówione zagadnienia:
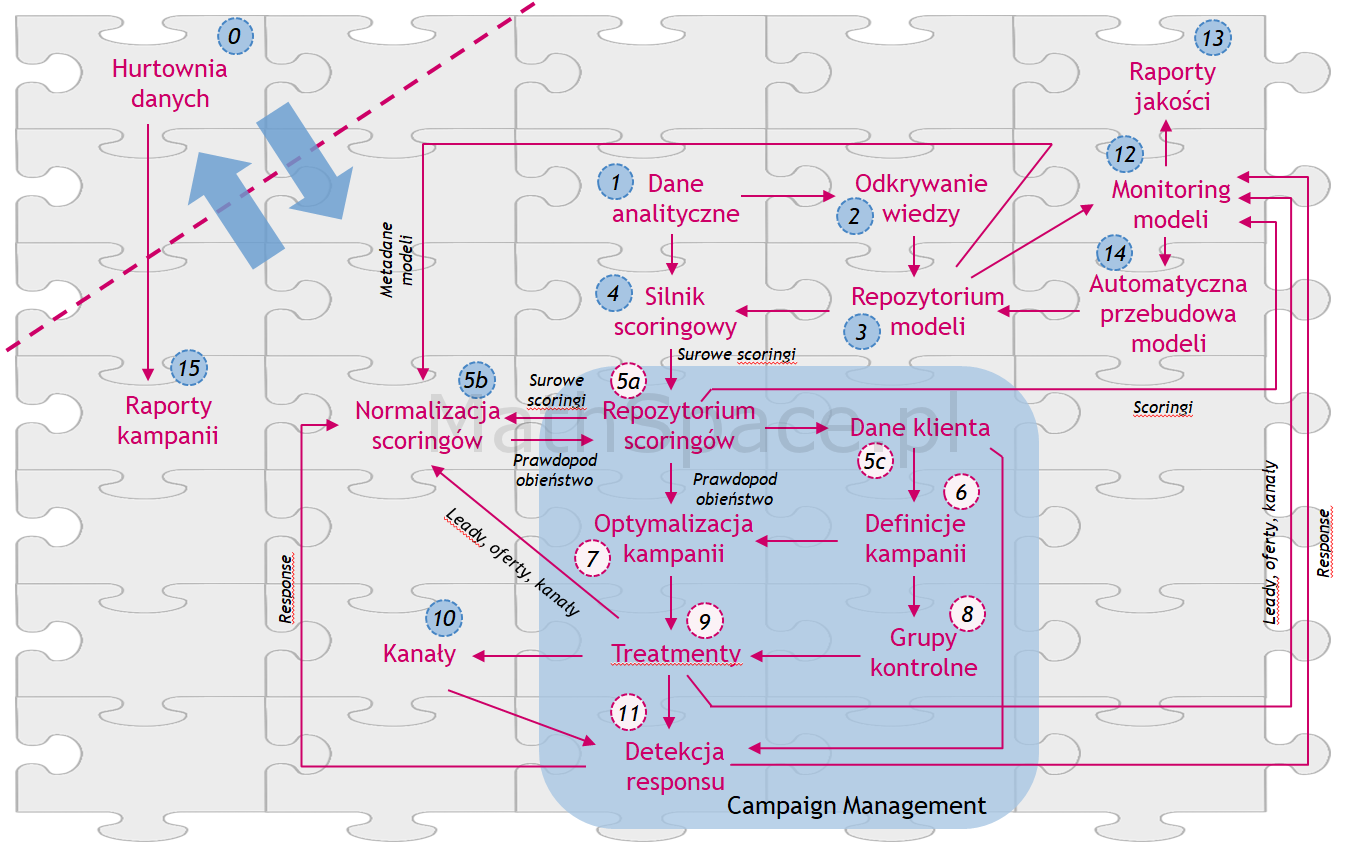
Komponenty środowiska analitycznego
Cykl analityczny / Integracja
Architektura funkcjonalna środowiska
– Obszar budowy / odkrywania wiedzy
– Obszar wdrażania przygotowanych modeli predykcyjnych
– Obszar repozytorium scoringowego
– Obszar definicji oraz uruchomienia kampanii
– Obszar monitoringu modeli predykcyjnych
– Obszar raportowania kampanii
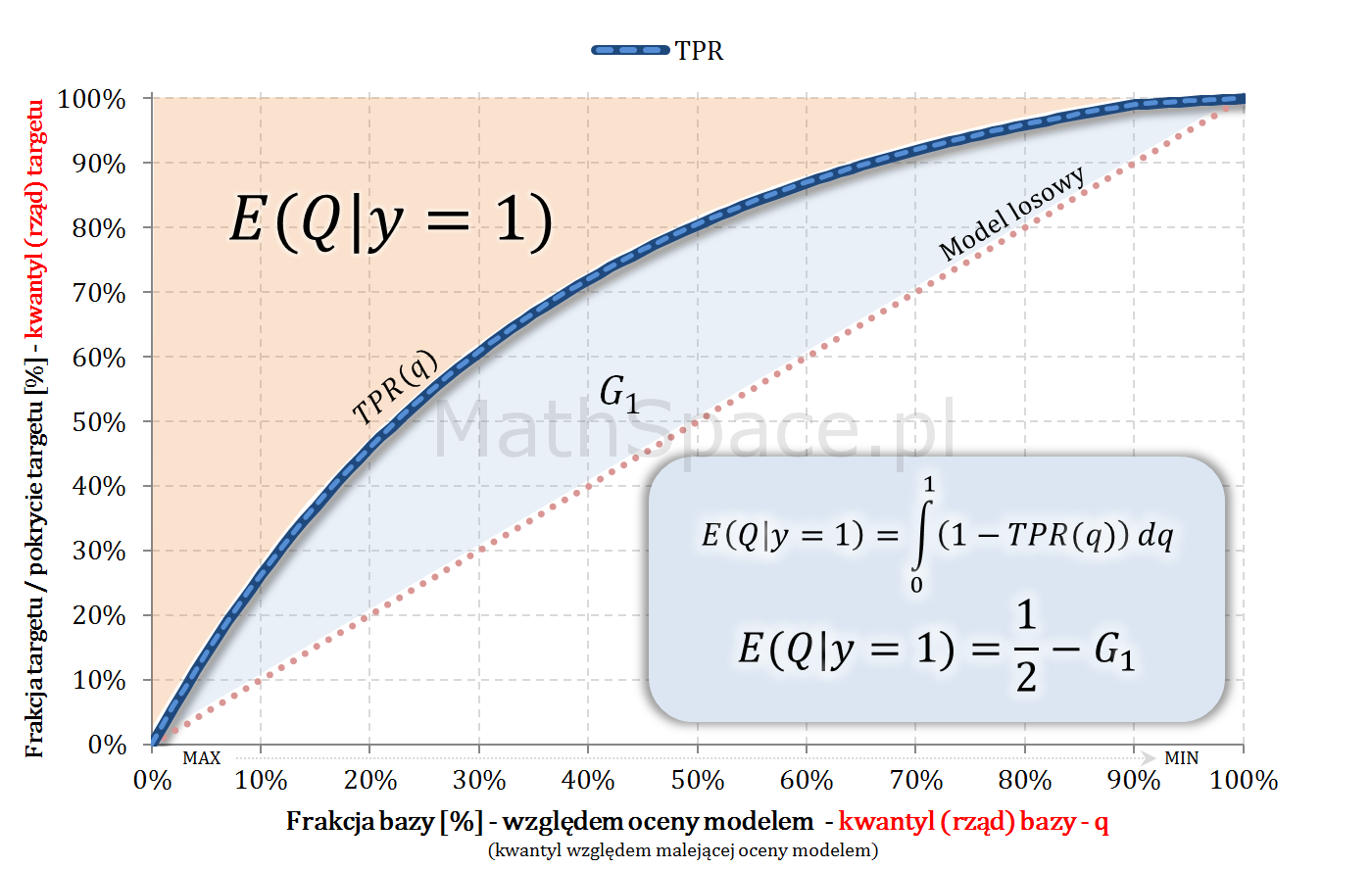
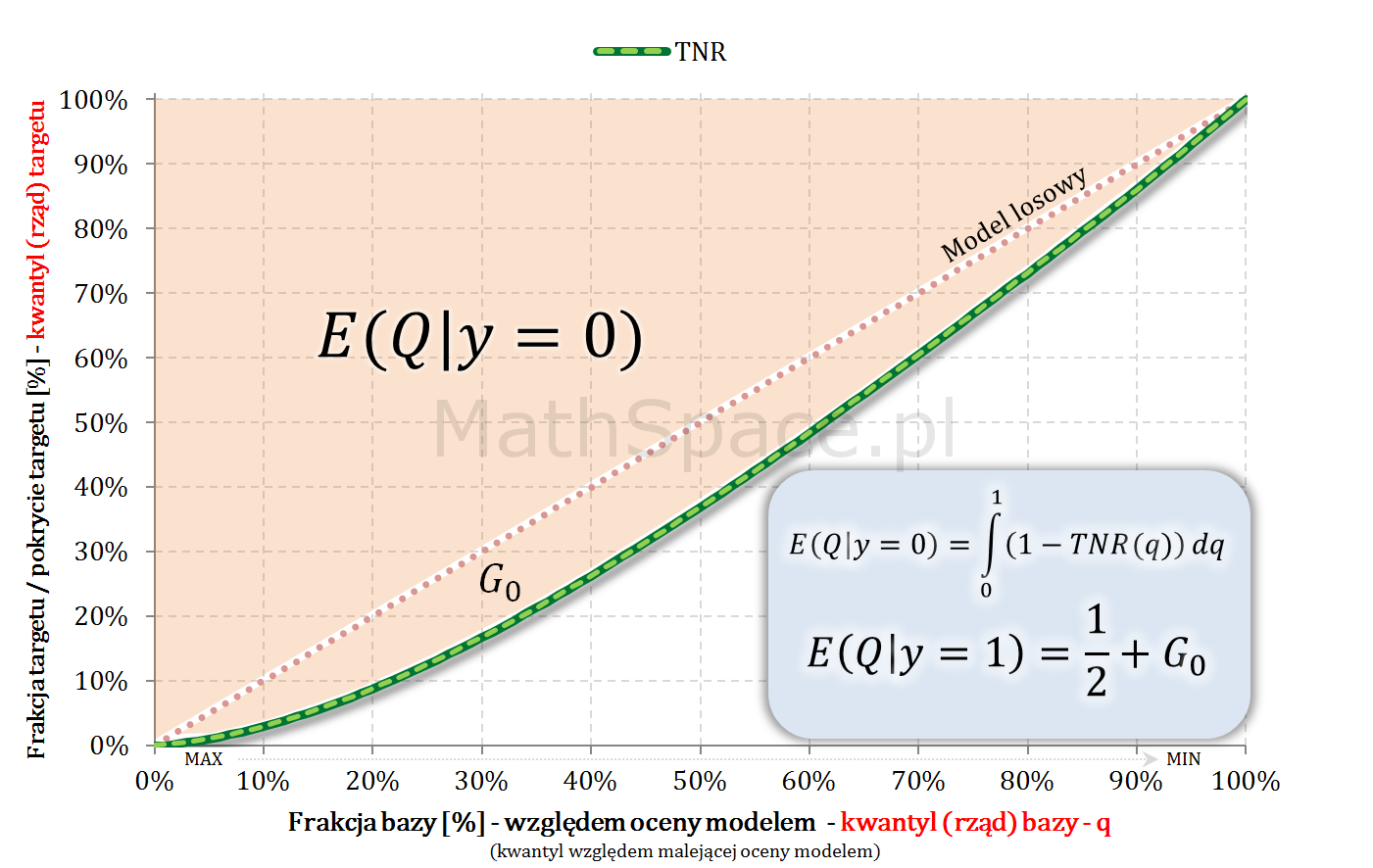
W trakcie minionej nocy, około godziny 02:00, miałem nagły przebłysk 🙂 Jakoś tak, nie wiem dlaczego, przypomniałem sobie pewną zależność dla wartości oczekiwanej zmiennej losowej o wartościach nieujemnych. Zdałem sobie sprawę, że na tej podstawie, jestem w stanie opracować twierdzenie dotyczące wskaźnika Giniego (dla modelu predykcyjnego), dające elegancką postać oraz łatwe narzędzie jego estymacji. Wzór, który wyprowadziłem, bazuje na wartości oczekiwanej, dającej się z powodzeniem przybliżyć średnią (np. w SQL). Zaczynamy część #19 cyklu „Ocena jakości klasyfikacji”, jest to „hardcorowy” wpis z serii „Tips & Tricks na krzywych” 🙂 Zapraszam!
Zmienna losowa reprezentująca rząd kwantyla (pozycję) elementu w populacji
Niech będzie dana zmienna losowa $Q\in[0;1]$, której wartość reprezentuje rząd kwantyla odpowiadający danemu elementowi, gdzie porządek jest dany malejącą oceną modelem. Inaczej – $Q$ to frakcja bazy.
Niech $y\in\{0,1\}$ oznacza klasę faktyczną.
Rozważmy zmienne losowe: $Q|y=1$ oraz $Q|y=0$.
W częściach #13 oraz #14 wykazałem, że zmienne $Q|y=1$ oraz $Q|y=0$ są opisane funkcjami gęstości podanymi przez: lifty nieskumulowane odpowiednio dla klasy „1” oraz klasy „0”.
Również w częściach #13 oraz #14 wykazałem, że zmienne $Q|y=1$ oraz $Q|y=0$ są opisane dystrybuantami podanymi przez: odpowiednio TPR dla klasy „1” oraz TNR dla klasy „0” (tam te funkcje nazywałem Captured Response).
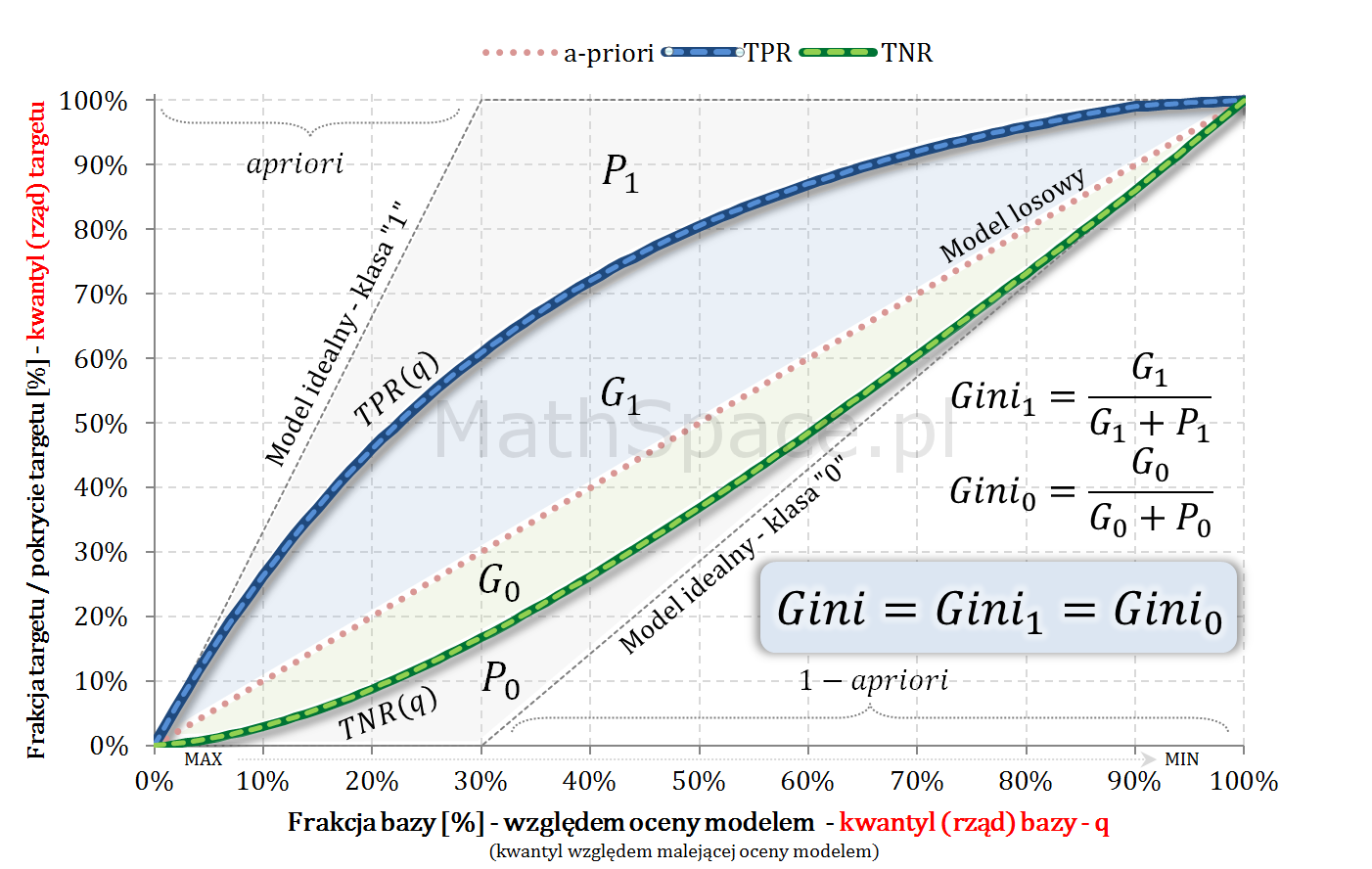
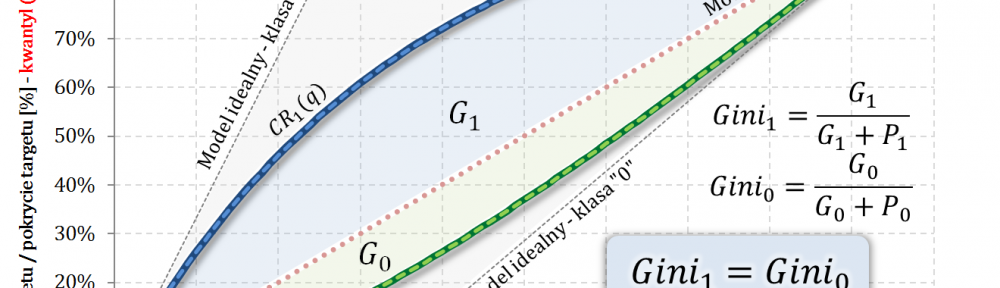
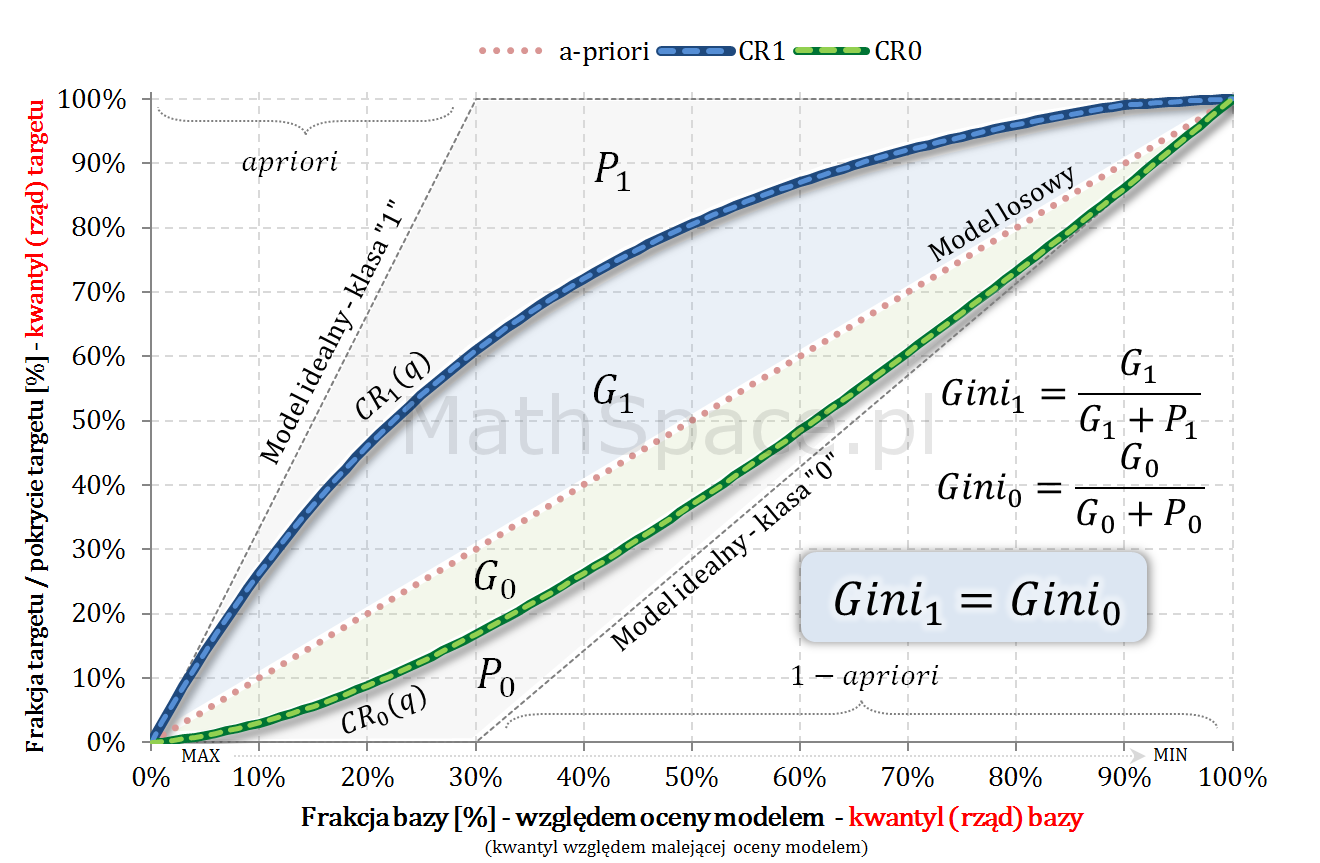
W części #15 wykazałem, że wskaźniki Giniego, zdefiniowane osobno dla klasy „1” oraz klasy „0”, są sobie równe – grafika poniżej.
Wartość oczekiwana zmienne losowej o wartościach nieujemnych
Poniższą zależność pamiętam z analizy przeżycia, gdzie średnią długość przeżycia liczono jako całkę pod funkcją przeżycia 🙂 Każda funkcja przeżycia ma postać $S(t)=1-F(t)$, gdzie $F$ to pewna dystrybuanta.
Twierdzenie: Jeśli zmienna losowa $X$, o ciągłym rozkładzie, przyjmuje wartości nieujemne to:
$$EX=\displaystyle\int_0^\infty P(X\geq x)dx$$
Zakładając, że $F$ jest dystrybuantą zmiennej $X$, bazując na ciągłości rozkładu, możemy zapisać
Jeśli model predykcyjny zwraca dużo nieunikalnych wartości, licząc rząd kwantyla, warto zastąpić go rzędem na bazie pozycji elementu – inaczej wyniki na bazie średniej mogą być nieprzewidywalne (szczególnie dla małych apriori). Wzory testowane na realnych danych 🙂
Pozdrowienia 🙂
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
I ponownie – wydaje mi się, że analogicznie można naszkicować TNR oraz FPR – tylko tu analizując: klasyfikację do klasy negatywnej, krzywą Liftu Skumulowanego dla klasy „0” oraz „przedłużenie” modelu idealnego dla klasy „0” – wymaga sprawdzenia 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Wydaje mi się, że analogicznie można wyznaczyć NPV – tylko tu analizując: klasyfikację do klasy negatywnej, krzywą Captured Response dla klasy „0” (TNR) oraz „przedłużenie” modelu idealnego dla klasy „0” – sprawdzimy 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
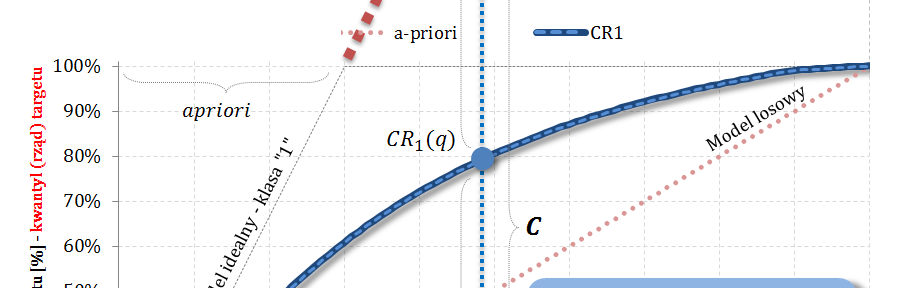
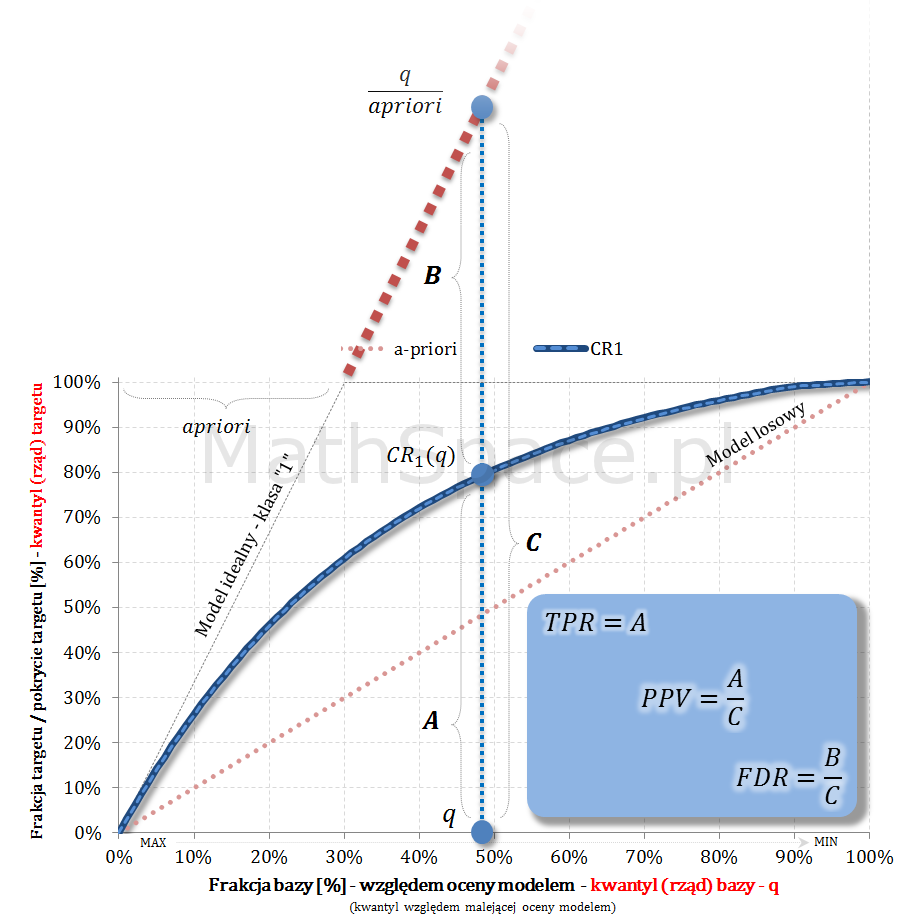
Do napisania 16 części cyklu „Ocena jakości klasyfikacji” zainspirował mnie Kolega i dawny współpracownik! Michał – dzięki za „hint” 🙂 Dziś wskażę pewien sympatyczny punkt przecięcia, którego znajomość jest przydatna, a już z pewnością można „zaszpanować” 🙂 Wpis stanowi zdecydowane wzbogacenie serii „Tips & Tricks na krzywych”.
Krzywe Captured Response (TPR) i prawdopodobieństwo skumulowane (PPV, Precision) przecinają się w punkcie a-priori 🙂
Dowód: zaczynamy od oznaczeń:
$N=N_1+N_0$ – liczba obiektów w populacji: total, z klasy pozytywnej „1”, z klasy negatywnej „0”;
$q$ – cut-off (jako kwantyl – a dokładnie jego rząd – względem malejącej oceny modelem);
Do czego „sympatyczny” punkt przecięcia może się przydać?
Znajomość punktu przecięcia może się przydać do weryfikacji poprawności analizowanych wykresów i ich spójności z założeniami. Przykładowo – jeśli analityk na jednym wykresie naniesie Captured Response wraz z modelem idealnym, następnie do wykresu doda p-ństwo skumulowane (czyli PPV), i jeśli te krzywe przetną się w innym punkcie niż „aprirori”, to gdzieś mamy błąd! Być może prezentowane wykresy przedstawiają różne modele?
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Dziś zadałem sobie pytanie: jak mają się do siebie wskaźniki Giniego, gdyby je osobno zdefiniować dla klasy pozytywnej „tzn. klasy 1” oraz klasy negatywnej „tzn. klasy 0”? Odpowiedź uzyskałem, czego efektem jest 15 część cyklu „Ocena jakości klasyfikacji”. Tytuł wpisu nawiązuje do faktu, że separację dwóch klas uzyskujemy jednym (i tym) samym modelem 🙂 co poniekąd sugeruje, że … 🙂
… wskaźniki Giniego dla klasy pozytywnej i klasy negatywnej są sobie równe!
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
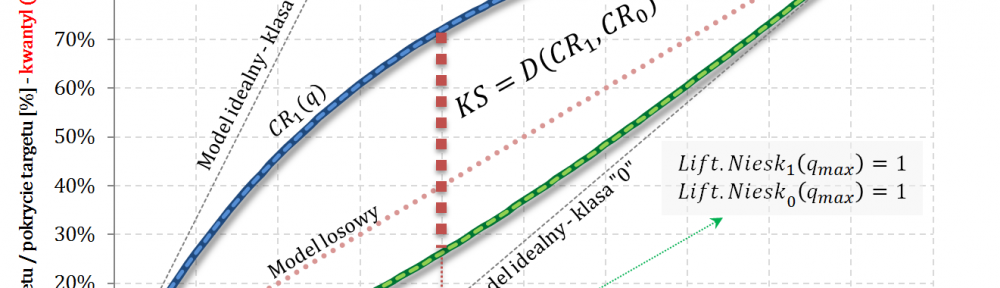
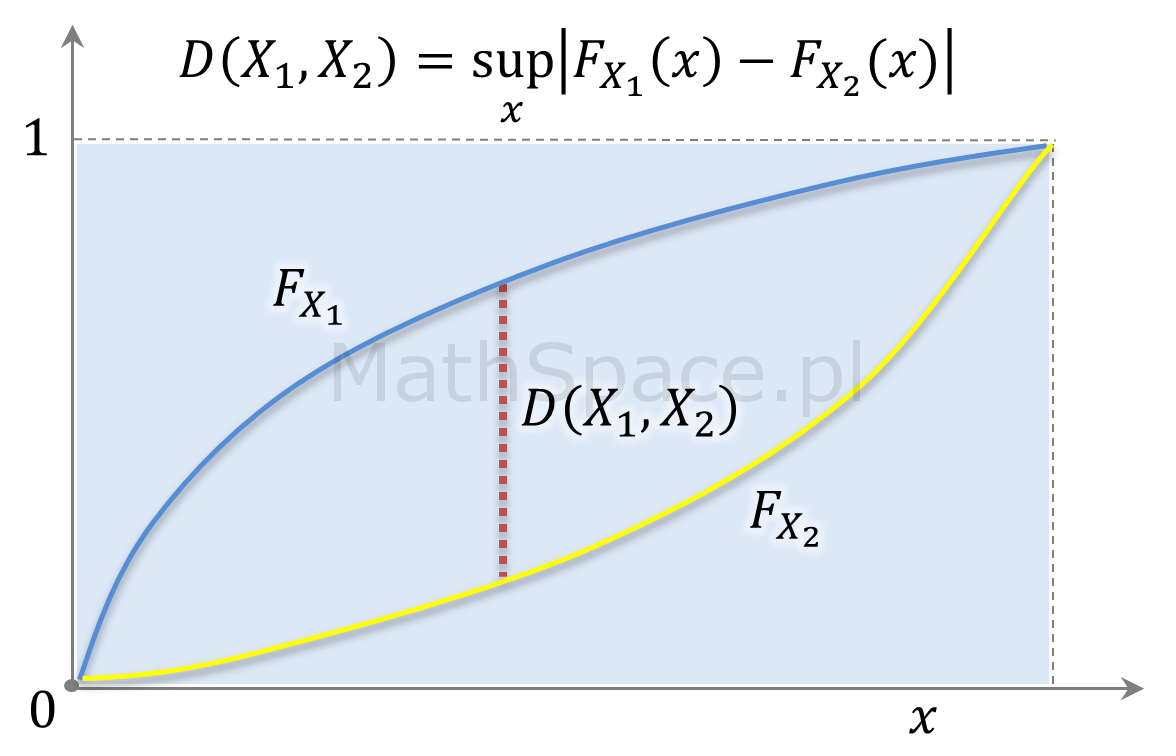
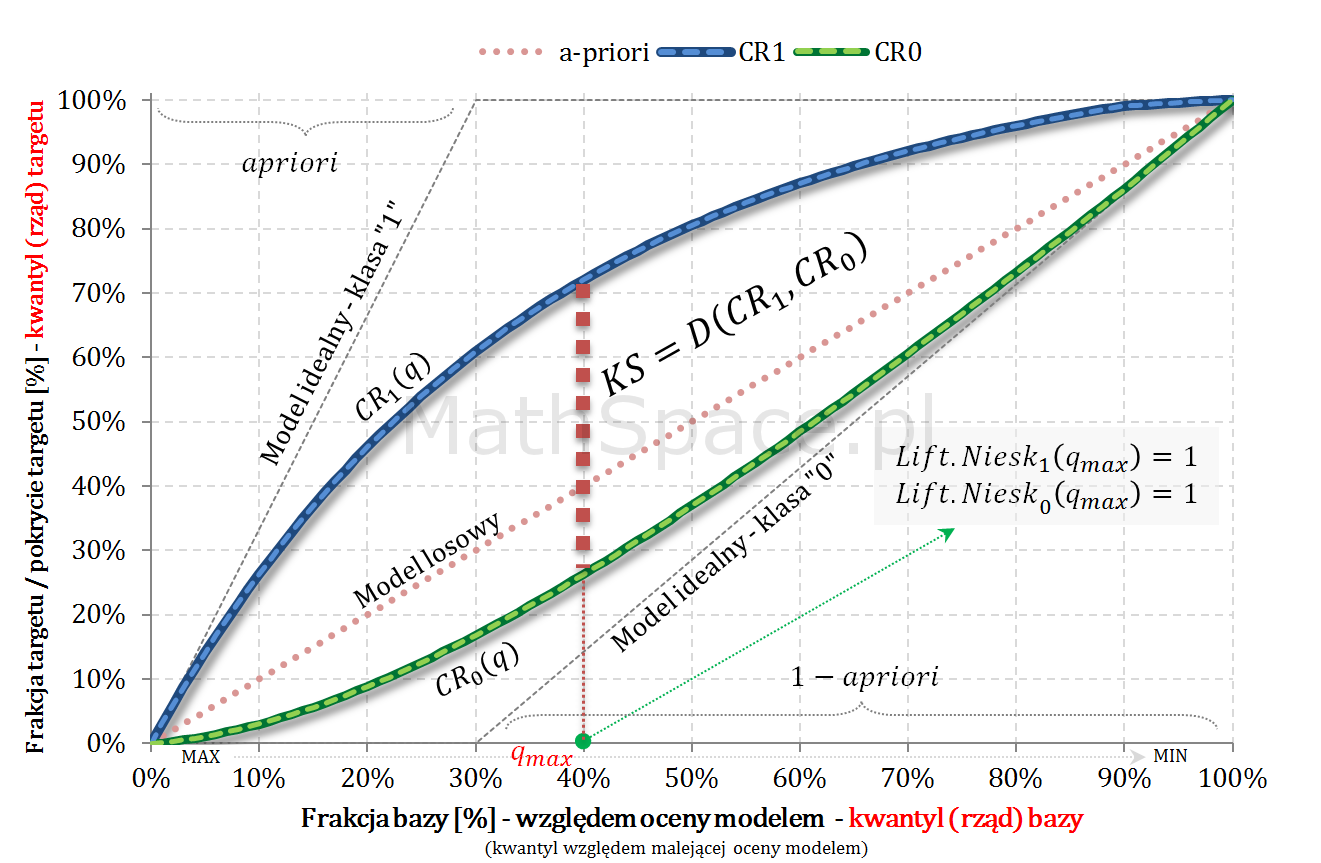
Statystyka KS Kołmogorowa-Smirnowa jako miara różnicy rozkładów
Rozważmy dwie rzeczywiste zmienne losowe $X_1$ i $X_2$ oraz ich dystrybuanty odpowiednio $F_{X_1}$ oraz $F_{X_2}$. Statystyką Kołmogorowa-Smirnowa dla zmiennych $X_1$ oraz $X_2$ nazywamy odległość $D\big(X_1,X_2\big)$ zdefiniowaną następująco:
Jeśli $x$ jest badaną wartością, to odległość KS interpretujemy jako maksymalną różnicę pomiędzy rzędem kwantyla w rozkładzie pierwszym i rzędem kwantyla w rozkładzie drugimi, które to rzędy odpowiadają wspólnej wartości $x$.
Do tanga trzeba dwojga
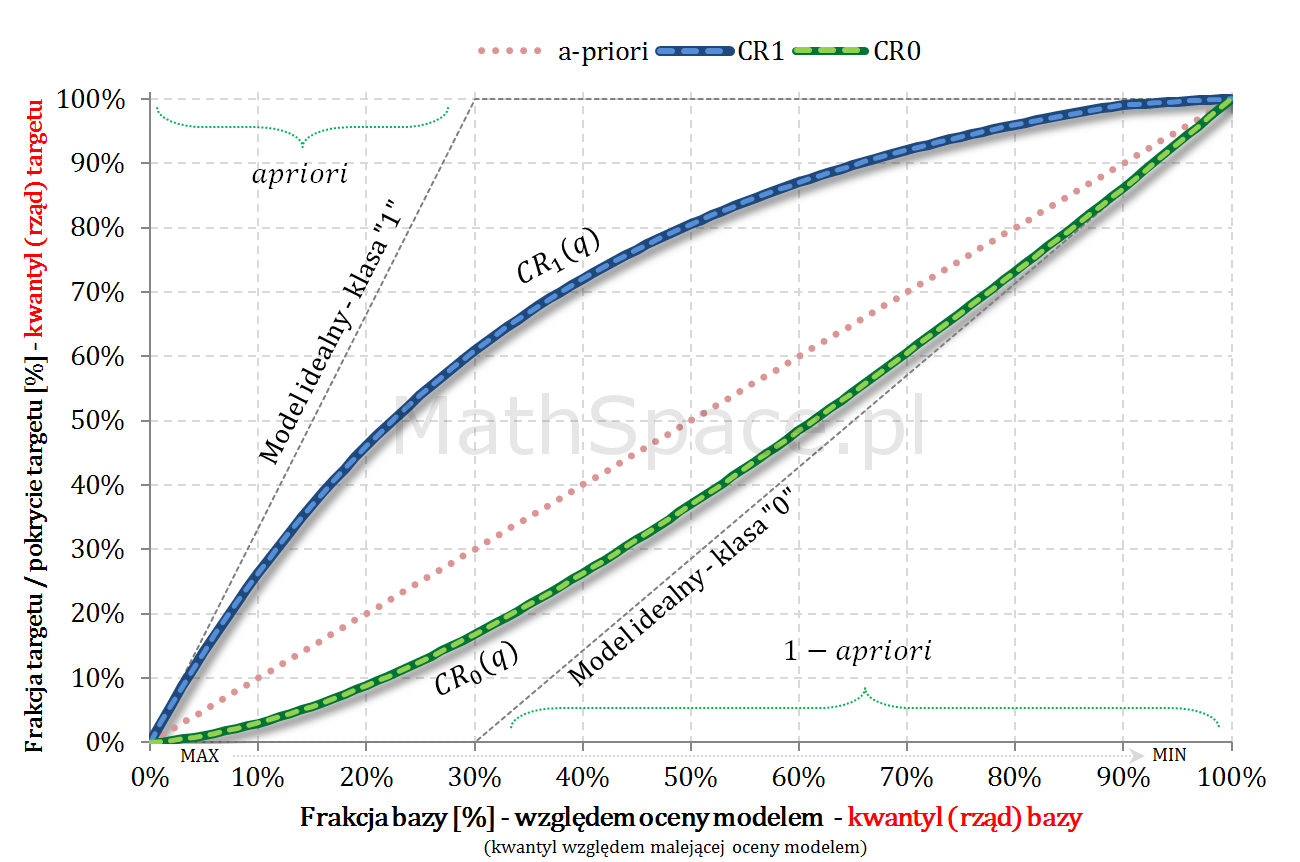
Przy modelach predykcyjnych, dla problemu klasyfikacji binarnej, tak naprawdę dysponujemy trzema rozkładami:
rozkład populacji / próby względem oceny modelem;
rozkład klasy pozytywnej względem oceny tym samym modelem;
rozkład klasy negatywnej również względem oceny tym samym modelem.
Lift nieskumulowany dla klasy negatywnej – tzn. „klasy 0”
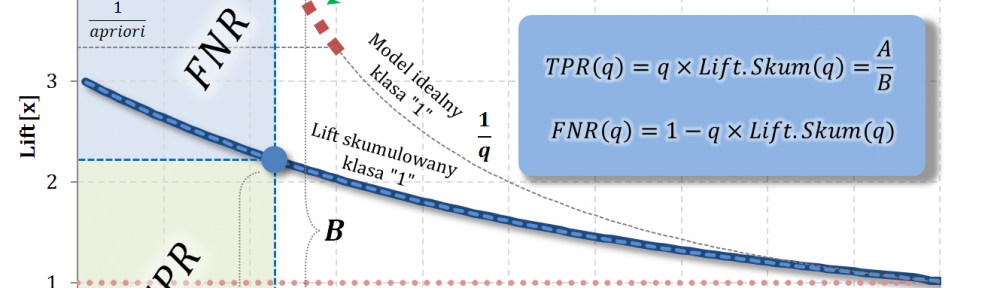
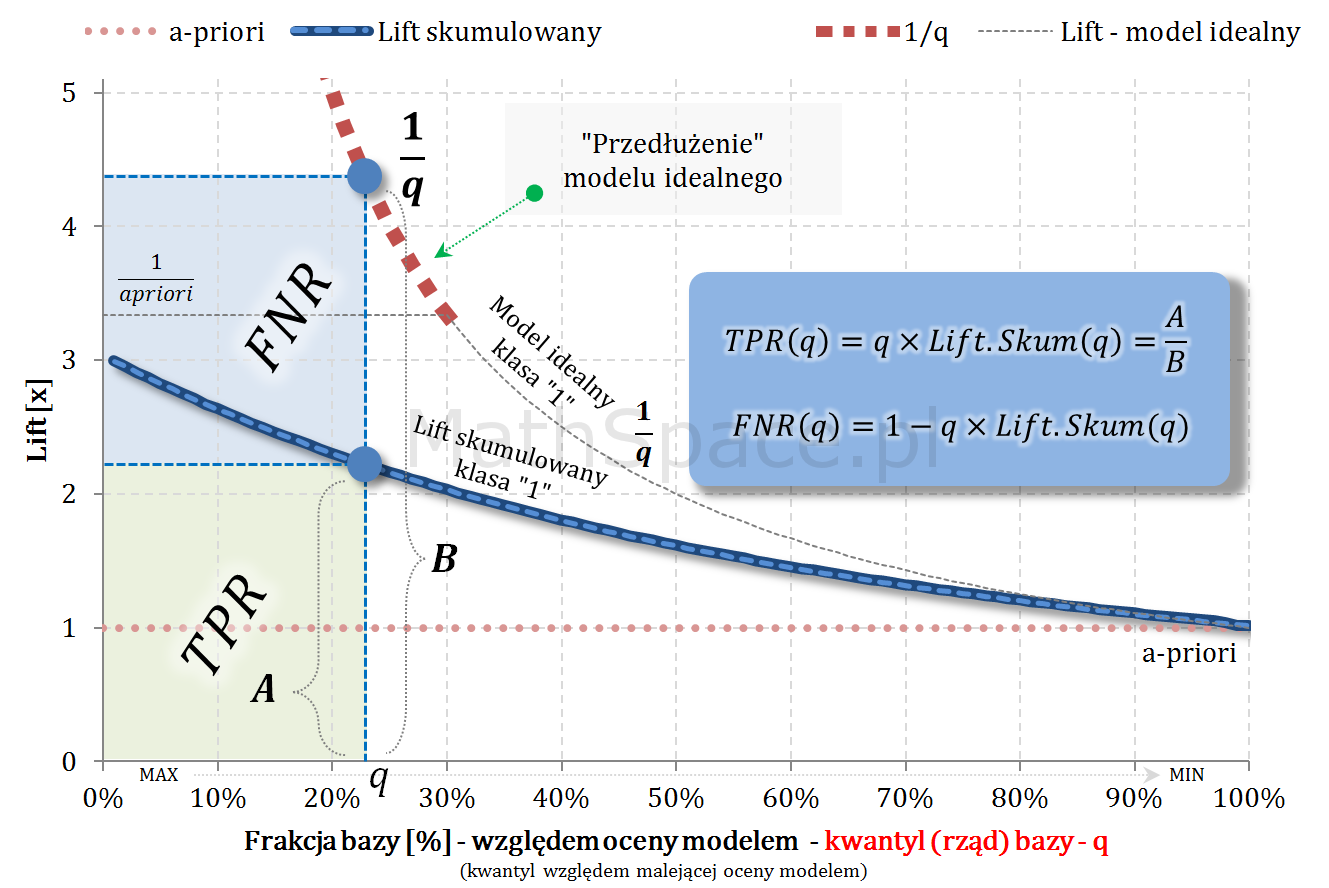
Załóżmy, że dana jest funkcja $Lift.Niesk_1(\Delta q)$ liftu nieskumulowanego dla klasy pozytywnej, gdzie $\Delta q$ to przedział rzędu kwantyla (w całej populacji) względem malejącej oceny modelem.
Przykład dla pewnej funkcji liftu nieskumulowanego i apriori = 30%.
Warto zwrócić uwagę na punkt przecięcia tych krzywych – spotykają się w tym samym miejscu, gdzie dochodzi do zrównania z krzywą dla modelu losowego. Dosyć łatwo to uzasadnić: jeśli $P(1|\Delta q^i)=apriori$ to $P(0|\Delta q^i)=1-apriori$.
Sprawdźmy jeszcze czy $Lift.Niesk_0(\Delta q)$ spełnia warunek „unormowania”.
Captured Response dla klasy negatywnej – tzn. „klasy 0”
Załóżmy, że dana jest funkcja $CR_1(q)$ Captured Response dla klasy pozytywnej, gdzie $q$ to rząd kwantyla (w całej populacji) względem malejącej oceny modelem.
Oznaczenia:
$q$ – punkt, dla którego wyznaczamy wartość krzywej;
$N=N_1+N_0$ – liczba obserwacji: łączna, z „klasy 1”, z „klasy 0”;
$n=n_1+n_2=q\cdot N$ – liczba obserwacji „na lewo” od $q$: łączna, z „klasy 1”, z „klasy 0”;
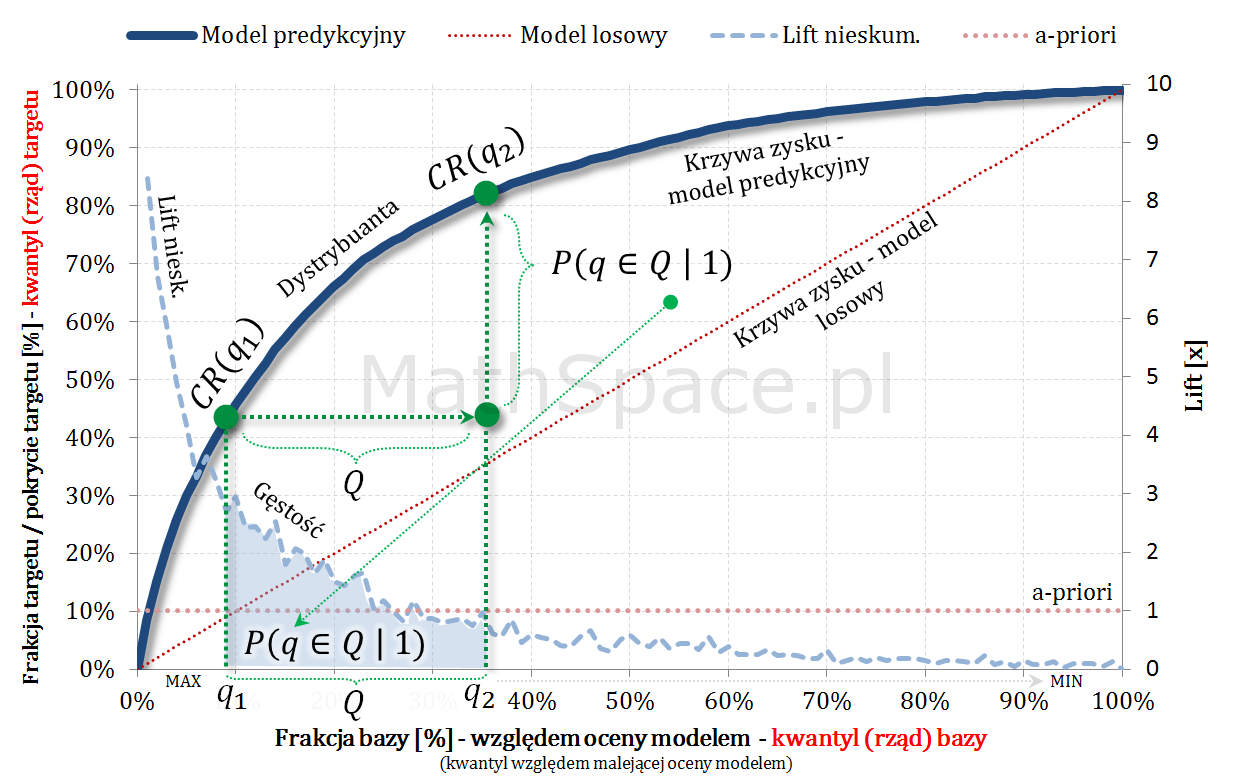
Aby w pełni zrozumieć powyższe przejścia zapoznaj się z częścią #11 „Captured Response vs Lift”, gdzie uzasadniam, że pochodna Captured Response to lift nieskumulowany.
Wniosek: Lift nieskumulowany dla klasy negatywnej oraz Captured Response dla klasy negatywnej to gęstość i dystrybuanta tego samego rozkładu.
Wniosek: odległość $CR_1(q)-CR_0(q)$ jest maksymalizowana w punkcie, w którym funkcja liftu nieskumulowanego ma wartość 1 – tzn. w punkcie przecięcia z liftem dla modelu losowego.
Powyższy wniosek jest dosyć intuicyjny – jeśli lift nieskumulowany „wchodzi w obszar bycia mniejszym niż 1” oznacza to, że jego efekt jest mniejszy od działania modelu losowego. Dodawanie kolejnych obserwacji zaczyna zmniejszać separację rozkładów.
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
W 13 części cyklu „Ocena jakości klasyfikacji” przedstawię dodatkowe interpretacje dla krzywej liftu nieskumulowanego i krzywej Captured Response. Obiecuję, że będzie ciekawie 🙂 przecież robimy „deep dive into predictive model assessment curves”. W dzisiejszym odcinku zapomnimy o punktach odcięcia, klasyfikatorach binarnych, rozważając rozkłady populacji jako całość. Chwilkę się do tego przygotowywałem – było warto – seria „Tips & Tricks na krzywych” nabiera rumieńców!
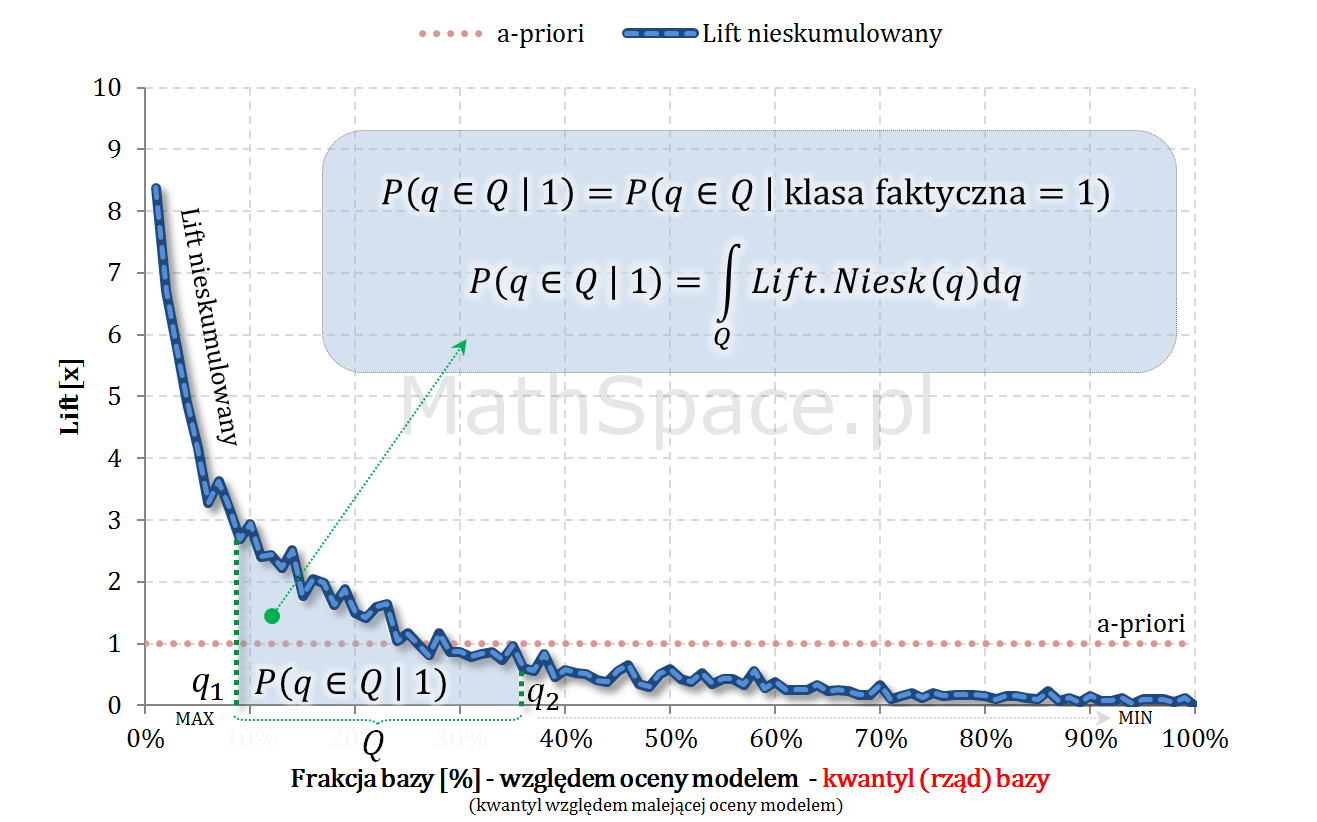
Pole powierzchni pod krzywą liftu nieskumulowanego
Lift nieskumulowany dla modelu losowego to funkcja stała o wartości 1. Pole pod taką krzywą równe jest polu kwadratu o boku 1 i wynosi oczywiście 1. Model losowy „rozrzuca” obserwacje z „klasy 1” równomiernie, tzn. taka sama część otrzymuje wysoki, średni i niski score. Głównym zadaniem modelu predykcyjnego, w pewnym sensie, jest „przepchnąć” obserwacje należące do „klasy 1” z segmentu niskiego score do segmentu wysokiego score – dzięki temu pojawia się separacja klas. Powyższe dobrze obrazuję animacją, gdzie siła modelu utożsamiana jest z „siłą podmuchu wiatru” 🙂
Takie „przepchnięcie” nie ma wpływu na ilość „jedynek”, zatem należy podejrzewać, że pole pod krzywą liftu nieskumulowanego zawsze wynosi 1. No to całkujemy:
$$\displaystyle\int_0^1 Lift.Niesk(q)dq$$
Oznaczenia + zależności:
$N=N_1+N_0$ – liczba obserwacji: łączna, z „klasy 1”, z „klasy 0”;
$k$ – liczba przedziałów, na które dzielimy odcinek $[0;1]$;
$p=\frac{1}{k}$ – szerokość pojedynczego przedziału (zakres zmienności rzędu kwantyli);
$p\cdot N$ – liczba obserwacji w przedziale (podział po kwantylach, zatem po równo);
$i=\{1,2,3,\ldots,k\}$ – numer przedziału;
$n_1^i+n_0^i=pN$ – liczba obserwacji w przedziale, osobno „z klasy 1” i „z klasy 0”;
$\Delta q^i$ – przedział, na którym wyznaczona jest wartość liftu nieskumulowanego;
$\displaystyle\sum_{i=1}^k n_1^i=N_1$
$\displaystyle\sum_{i=1}^k n_0^i=N_0$
$\displaystyle\sum_{i=1}^k n_1^i+n_0^i=N_1+N_0=N$
Lift nieskumulowany jest funkcją przedziałami stałą:
Lift nieskumulowany jako funkcja gęstości rozkładu prawdopodobieństwa
Funkcja liftu nieskumulowanego jest nieujemna i spełnia warunek „unormowania” (w przeciwieństwie do funkcji nieskumulowanego prawdopodobieństwa) w kontekście gęstości rozkładu prawdopodobieństwa – tzn. pole powierzchni pod krzywą wynosi 1. Taka gęstość opisuje rozkład rzędu kwantyli (kwantyle wyznaczane dla całej populacji „klasa 0 + klasa 1” względem malejącej oceny modelem) w klasie faktycznie pozytywnej – tzn. w „klasie 1”.
Captured Response jako dystrybuanta rozkładu prawdopodobieństwa
Captured Response jest funkcją niemalejącą, jednostronnie ciągłą (powiedzmy, że prawostronnie), o wartościach z przedziału $[0;1]$, wartości 0 dla $q\leq 0$ oraz wartości 1 dla $q\geq 1$. Tym samym spełnione są warunki bycia dystrybuantą pewnego rozkładu prawdopodobieństwa. W części „#11 – Captured Response vs Lift” wykazałem, że pochodna z Captured Response to lift nieskumulowany. Wniosek: Captured Response i lift nieskumulowany to dystrybuanta i gęstość tego samego rozkładu prawdopodobieństwa.
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
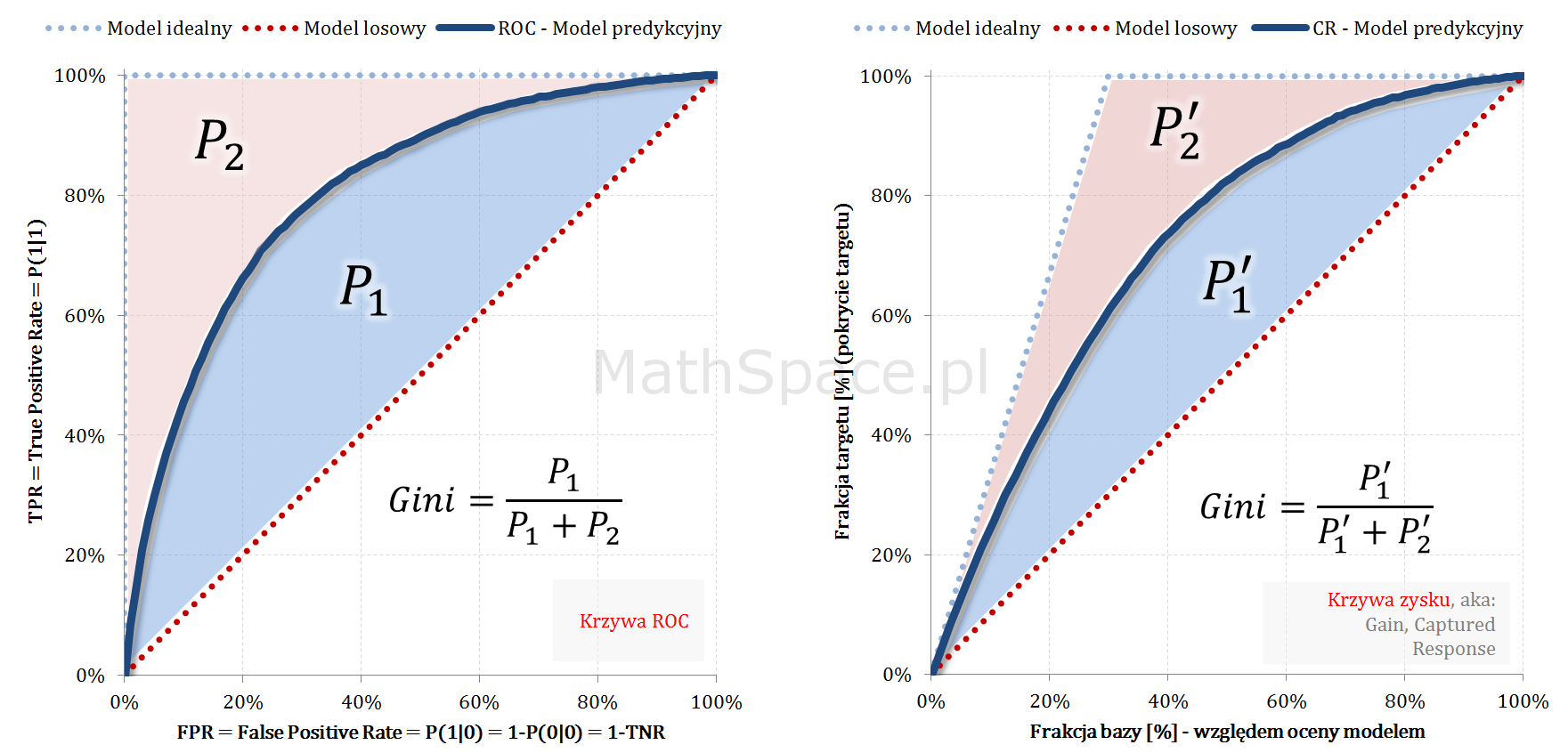
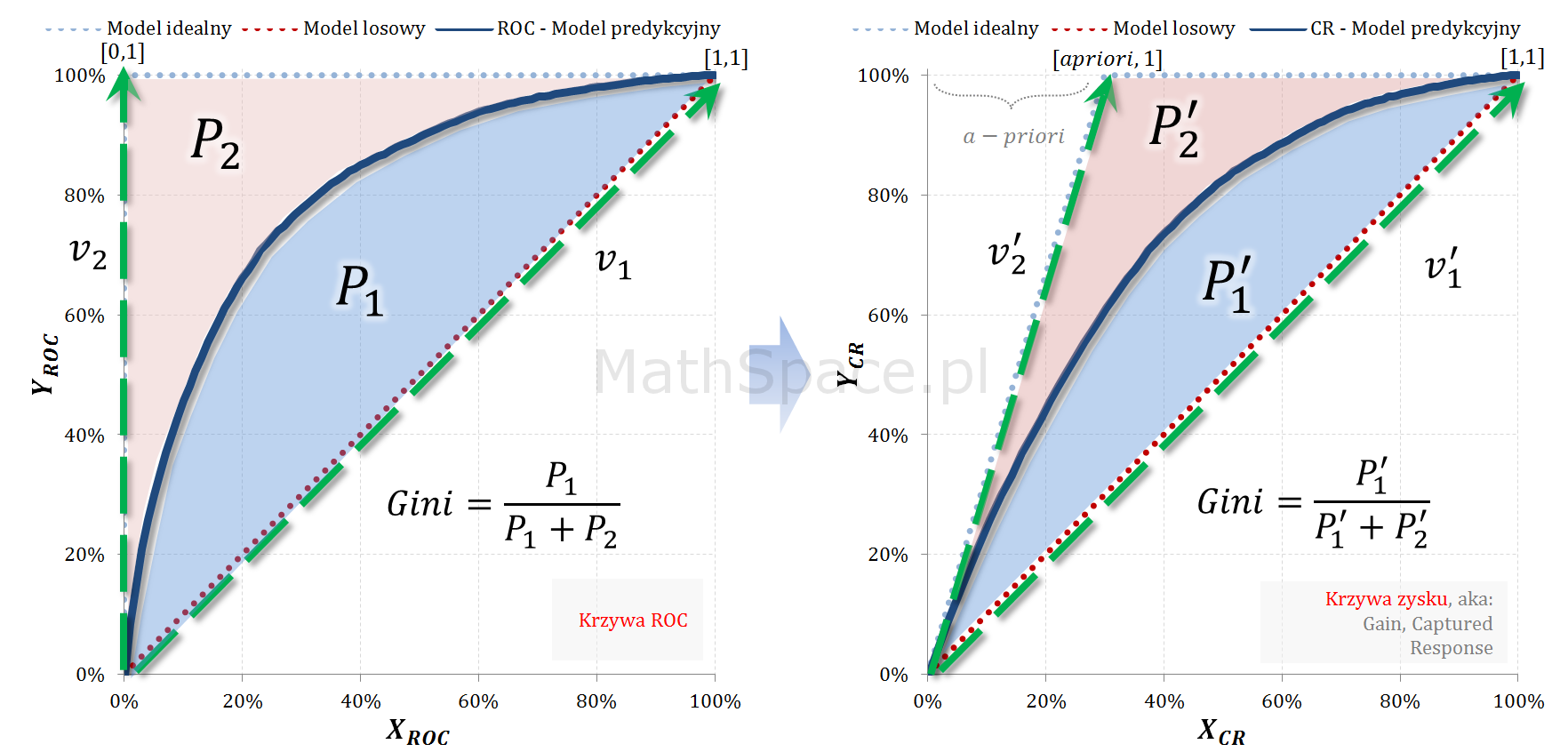
Wskaźnik Giniego, który opisałem w części #7 poświęconej krzywej ROC, jest jednym z najważniejszych narzędzi wykorzystywanych w procesie oceny jakości klasyfikacji. Choć krzywa ROC jest ważna i bardzo przydatna, to z mojego doświadczenia wynika, że większość analityków woli wykreślać krzywą Captured Response. Sądzę, że wszyscy intuicyjnie czujemy, że „Gini z ROC” i „Gini z Captured Response” to to samo 🙂 Ale dlaczego tak jest? 🙂 Dziś odpowiem na to pytanie, jednocześnie wzbogacając serię „Tips & Tricks na krzywych”!
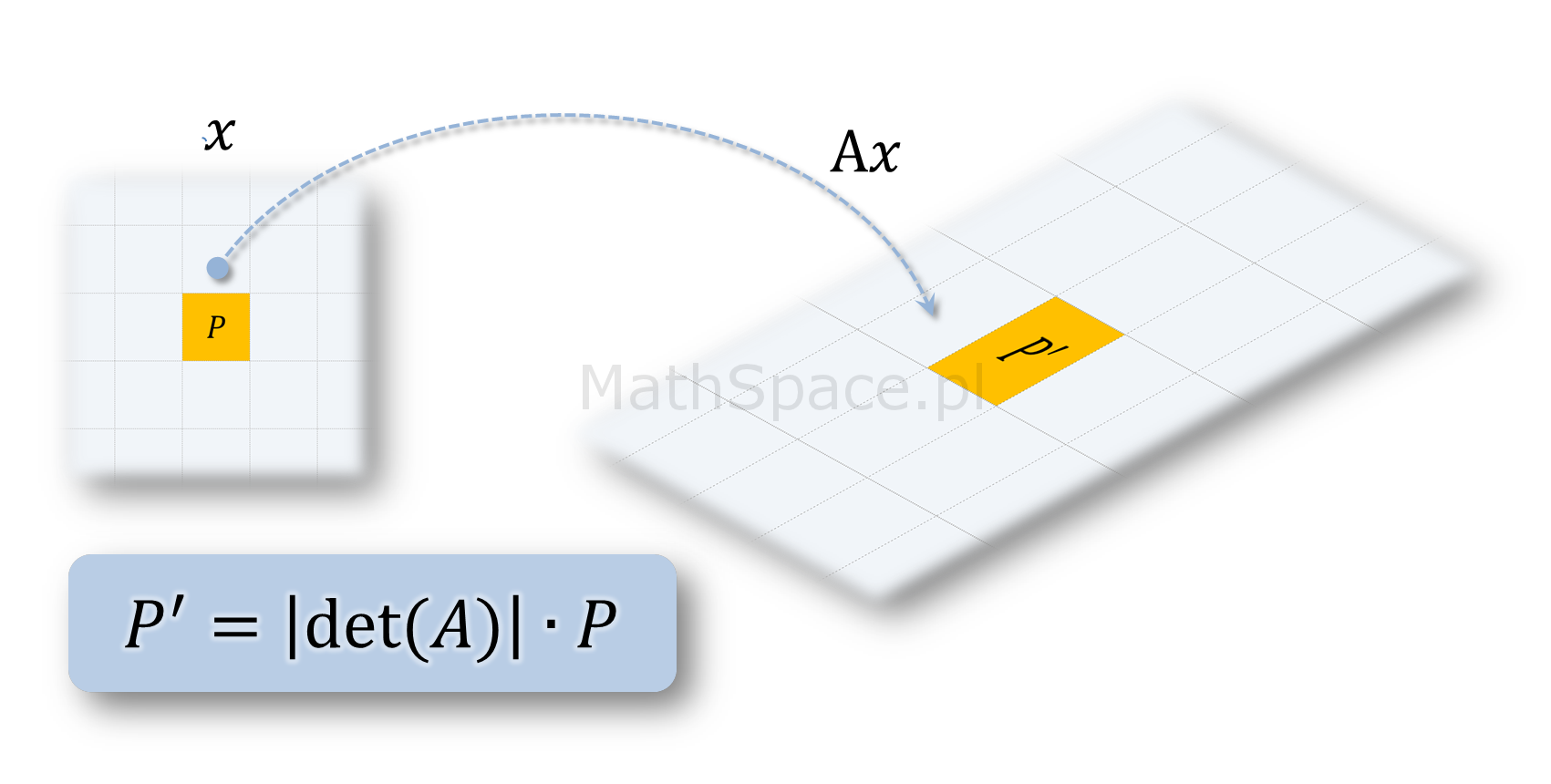
Wyznacznik macierzy przekształcenia liniowego i współczynnik zmiany pola powierzchni
Jeśli analizujemy przekształcenie liniowe
$$Ax$$
gdzie $A$ jest macierzą przekształcenia liniowego, a $x$ wektorem, to wyznacznik
$$\text{det}(A)$$
jest współczynnikiem o jaki zmienia się pole powierzchni / objętość / miara figury / obiektu transformowanego poprzez przekształcenie liniowe $Ax$. Polecam poniższy film.
Wyznacznik macierzy przekształcenia liniowego krzywej ROC w krzywą Captured Response
Z powyższego wynika, że pole powierzchni pomiędzy przestrzenią, w której „osadzona” jest krzywa ROC, a przestrzenią „zawierającą” krzywą Captured Response, powinno się skalować poprzez współczynniki $1-apriori$. Sprawdźmy 🙂
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Zarządzaj zgodą
Aby zapewnić jak najlepsze wrażenia, korzystamy z technologii, takich jak pliki cookie, do przechowywania i/lub uzyskiwania dostępu do informacji o urządzeniu. Zgoda na te technologie pozwoli nam przetwarzać dane, takie jak zachowanie podczas przeglądania lub unikalne identyfikatory na tej stronie. Brak wyrażenia zgody lub wycofanie zgody może niekorzystnie wpłynąć na niektóre cechy i funkcje.
Funkcjonalne
Zawsze aktywne
Przechowywanie lub dostęp do danych technicznych jest ściśle konieczny do uzasadnionego celu umożliwienia korzystania z konkretnej usługi wyraźnie żądanej przez subskrybenta lub użytkownika, lub wyłącznie w celu przeprowadzenia transmisji komunikatu przez sieć łączności elektronicznej.
Preferencje
Przechowywanie lub dostęp techniczny jest niezbędny do uzasadnionego celu przechowywania preferencji, o które nie prosi subskrybent lub użytkownik.
Statystyka
Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do celów statystycznych.Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do anonimowych celów statystycznych. Bez wezwania do sądu, dobrowolnego podporządkowania się dostawcy usług internetowych lub dodatkowych zapisów od strony trzeciej, informacje przechowywane lub pobierane wyłącznie w tym celu zwykle nie mogą być wykorzystywane do identyfikacji użytkownika.
Marketing
Przechowywanie lub dostęp techniczny jest wymagany do tworzenia profili użytkowników w celu wysyłania reklam lub śledzenia użytkownika na stronie internetowej lub na kilku stronach internetowych w podobnych celach marketingowych.
Cześć, z tej strony Mariusz Gromada, autor bloga MathSpace.pl.
Znacie mnie z tekstów o nauce i matematyce. Równolegle – od ponad 20 lat – zajmuję się projektowaniem, wdrażaniem oraz wykorzystywaniem wielkoskalowych systemów personalizacji w organizacjach B2C. Tę podwójną perspektywę – analityczno-inżynierską i biznesową – zebrałem w mojej najnowszej książce:
„Customer First, Value Next: The Executive Playbook for AI-Driven Omnichannel Personalization and Customer-Centric Growth.”
Jeśli jesteś liderem biznesowym, liderem technologicznym, inżynierem, analitykiem lub po prostu fascynuje Cię budowa skalowalnych systemów AI, które potrafią zrozumieć klienta – odchodząc od tradycyjnego modelu produktowego – to ta pozycja jest dla Ciebie.
„Technologia to nie tylko narzędzie do automatyzacji. To megafon dla empatii.”