W „matematyce w obrazkach” ponownie grafika wykonana na bazie Atraktora Lorenza – to bardzo wdzięczny motyw! Oto Sowa Lorenzowa 🙂

Chcesz zobaczyć poprzednie grafiki? Kliknij tutaj.
Pozdrowienia,
Mariusz Gromada
W „matematyce w obrazkach” ponownie grafika wykonana na bazie Atraktora Lorenza – to bardzo wdzięczny motyw! Oto Sowa Lorenzowa 🙂
Chcesz zobaczyć poprzednie grafiki? Kliknij tutaj.
Pozdrowienia,
Mariusz Gromada

„Plaża, piękna pogoda, sielanka i relaks! Różne funkcje wypoczywają. Nagle … popłoch, panika! Funkcje uciekają. Tylko jedna nadal się opala.
– Co robisz? Uciekaj! Nadchodzi operator różniczkowy!
– Nie boję się, jestem $e^x$.
I tak spokojna $e^x$ została. Wpada operator.
– Wrrr! Teraz Cię zróżniczkuję! Wrrr!
– A proszę bardzo – jestem $e^x$ – nic mi nie grozi.
– Kochana, ja różniczkuję po $dy$”
Ten iście „nerdowski” dowcip całkiem dobrze rozpoczyna kolejną część serii „o liczbie e”. Na bazie pochodnej przedstawię dodatkowe argumenty „dlaczego?” liczba e jest tak naturalna. Zaczynamy od powtórki podstaw w zakresie potęgowania. Prawdopodobnie zaskoczę Cię już samą definicją funkcji wykładniczej $a^x$ 🙂

Funkcja wykładnicza i logarytm wprowadzane są w szkole średniej (przynajmniej tak było w moim przypadku). Zazwyczaj wtedy poznajemy liczbę $e$, którą magicznie nazywa się podstawą logarytmu naturalnego.
$$e\approx 2.718\ldots$$
Nazwa dobrana jest świetnie, niestety nikt nie tłumaczy dlaczego tak właściwie jest. Cała sprawa jest niezwykle ciekawa, jej wyjaśnienie to temat nowej serii artykułów „o liczbie e”. Tym samym wzbogacam cykl „dlaczego?”. Dowody przeprowadzę „metodą elementarną” – wszak chodzi o „pierwotność / naturalność” $e$. Będzie kilka dużych „odcinków” – zapraszam 🙂
Liczba e pojawia się w wielu dziedzinach. W matematyce jest wszechobecna! Z powodzeniem dorównuje liczbie $\pi$. Analiza matematyczna (w szczególności rachunek różniczkowy i całkowy, równania różniczkowe), funkcje specjalne, analiza zespolona, rachunek prawdopodobieństwa, statystyka matematyczna – to najbardziej wyraziste przykłady. W innych naukach ścisłych (np.: ekonomia, fizyka, biologia) liczba e pojawia się w wielu ważnych równaniach, w tym: równanie przewodnictwa cieplnego, wzór barometryczny, rozpady promieniotwórcze, fazory, funkcja falowa w mechanice kwantowej, wzrost populacji, procent składany.
Pierwsze informacje na temat liczby e pojawiły się w 1618 roku. Opublikował je John Napier, przygotowując tabele logarytmów. Praca nie zawierała samej stałej, prezentowała niektóre wartości logarytmów na bazie e. Liczbę e w jej dzisiejszej postaci odkrył Jacob Bernoulli. Dokonał tego w 1683 roku analizując własności procentu składanego. Pierwsze udokumentowane wykorzystanie liczby e, wtedy oznaczanej przez b, pojawiło się w latach 1690-1691 (Gottfried Leibniz, Christiaan Huygens). Wykorzystanie stałej znacząco rozwinął Leonhard Euler oznaczając ją w 1727 roku do dziś wykorzystywanym symbolem $e$.
Grafika wykonana na bazie Atraktora Lorenza – świetne wzbogacenie cyklu „Matematyka w obrazkach” 🙂

Polecam poniższą animację – 500 tysięcy ciasno upakowanych cząstek rozchodzi się w chaos. Cząstki to punkty z rozkładu Gaussa z odchyleniem standardowym 0.01. W miarę upływu czasu cząstki podążają za dynamiką Lorenza.

Pole powierzchni figur płaskich podobnych zmienia się z kwadratem skali podobieństwa – fakt nauczany już w szkole podstawowej. Dziś zadajemy pytanie „dlaczego” tak jest? O ile uzasadnienie dla najprostszych typów figur jest banalne (wynika bezpośrednio ze wzorów na pole), to w przypadku powierzchni ograniczonej dowolną krzywą (no może nie do końca dowolną) potrzeba już nieco więcej gimnastyki. Pokażę kilka podjeść, w tym osobno „pokryciowe”, osobno oparte na całce Riemanna, oraz osobno na bazie przekształcenia liniowego. Na koniec podam bardziej ogólne wnioski co do zmiany pola powierzchni względem znacznie szerszej niż podobieństwo klasy transformacji. Zapraszam 🙂
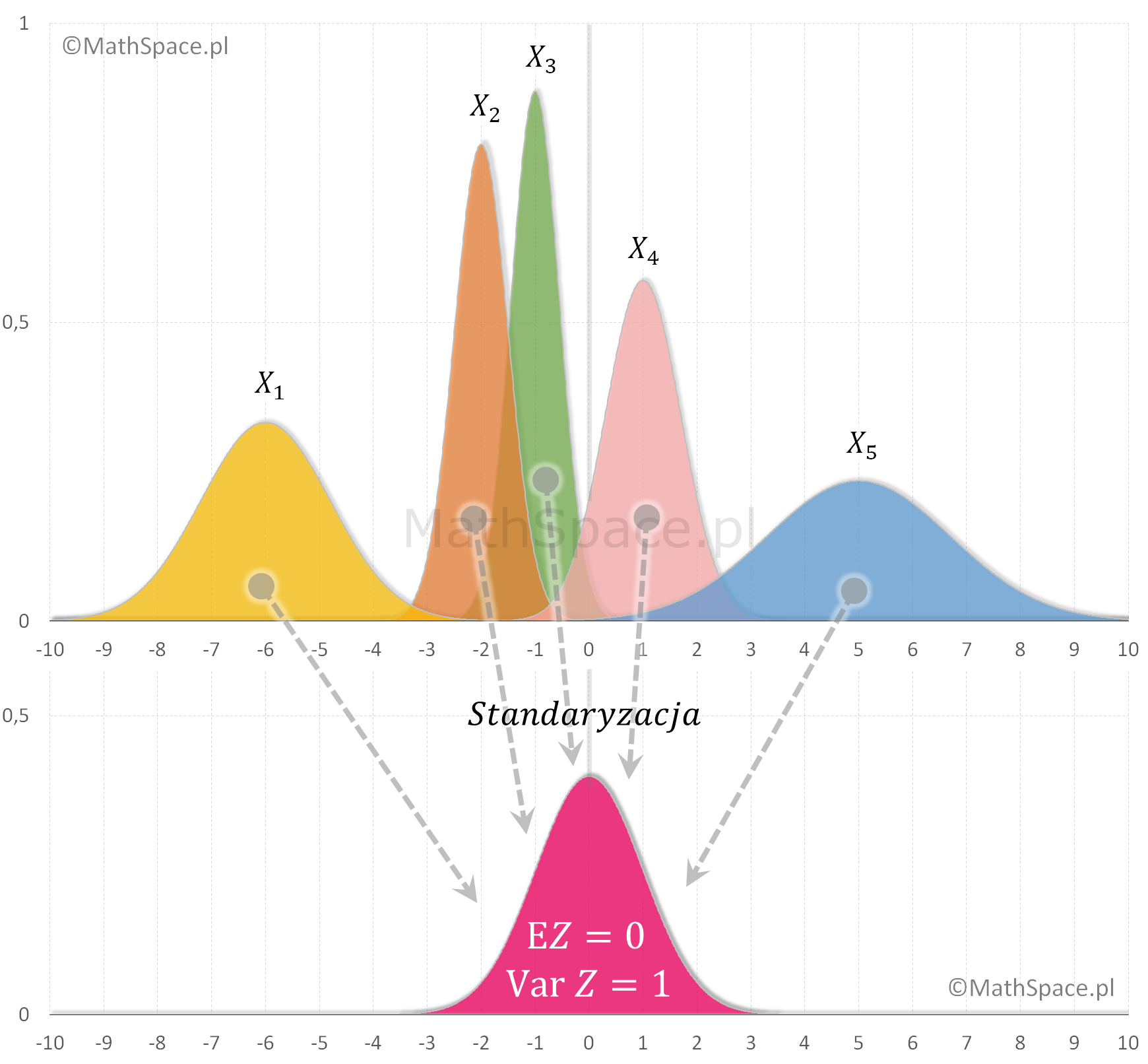
Standaryzacja zmiennej losowej $X$ to proces jej „normalizacji”, którego wynikiem jest taka zmienna losowa $Z$, że
$$\text{E}Z=0$$
$$\text{Var}(Z)=1$$
Standaryzację łatwo wyobrazić sobie jako działanie, które obywa się w dwóch krokach:
Standaryzacja Z: jeśli X jest taką zmienną losową, że
Prelekcja wygłoszona w dniu 25.04.2017 podczas Konferencji Big Data – Bigger opportunities – zapraszam.
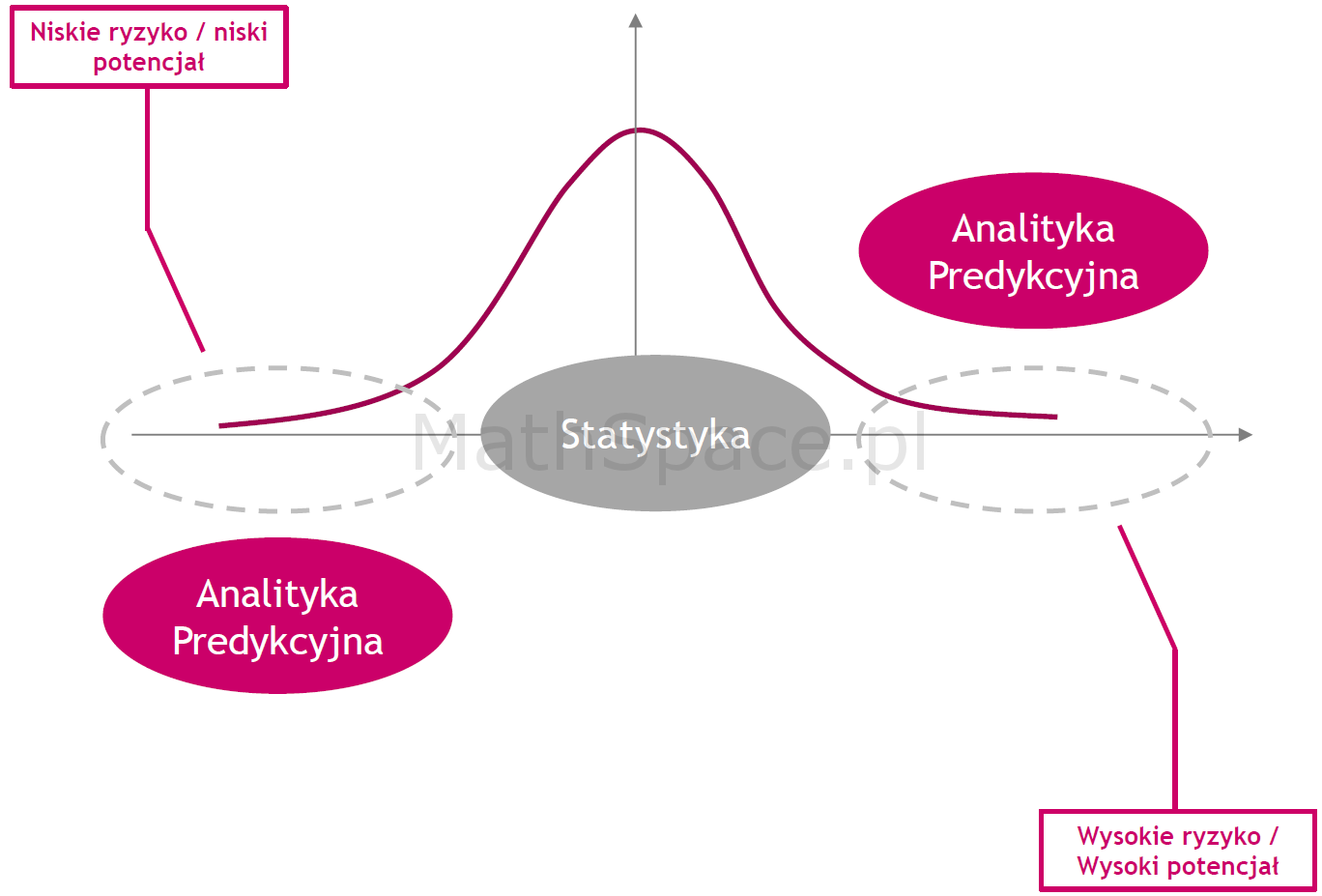
Omówione zagadnienia:
![]()
Pozdrowienia,
Mariusz Gromada
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Agnostycyzm – bliska mi postawa.
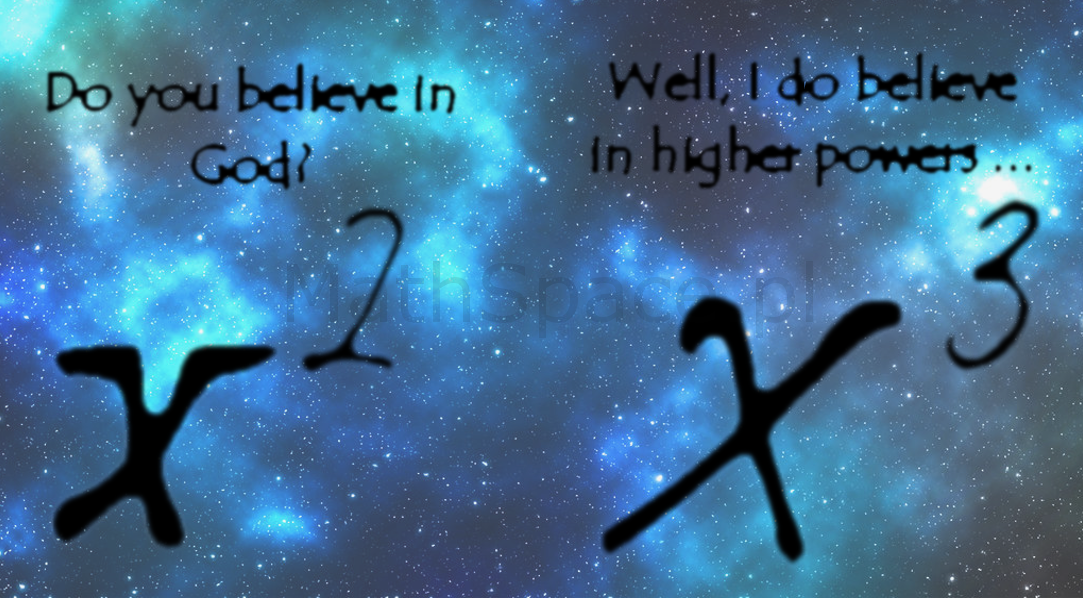
Świetnie to wyjaśnia genialny fizyk – Leonard Susskind.
Inne posty w cyklu „Matematyka w obrazkach”.
Pozdrowienia,
Mariusz Gromada
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Znacie mnie z tekstów o nauce i matematyce. Równolegle – od ponad 20 lat – zajmuję się projektowaniem, wdrażaniem oraz wykorzystywaniem wielkoskalowych systemów personalizacji w organizacjach B2C. Tę podwójną perspektywę – analityczno-inżynierską i biznesową – zebrałem w mojej najnowszej książce:

Jeśli jesteś liderem biznesowym, liderem technologicznym, inżynierem, analitykiem lub po prostu fascynuje Cię budowa skalowalnych systemów AI, które potrafią zrozumieć klienta – odchodząc od tradycyjnego modelu produktowego – to ta pozycja jest dla Ciebie.


