
Kilka kolejnych części cyklu „Ocena jakości klasyfikacji” skupi się na poradach i pewnych trickach (czyli seria „Tips & Tricks na krzywych”), które zastosowane do krzywych: Lift, Captured Response, ROC, znacząco pogłębiają ich interpretację.
!!! Uwaga: dla uproszczenia – wszędzie tam, gdzie piszę kwantyl, mam na myśli jego rząd !!!
Model teoretycznie idealny a prawdopodobieństwo a-priori
Model teoretycznie idealny to taki model, który daje najlepsze możliwe uporządkowanie – inaczej mówiąc najlepszą możliwą separację klas. Taki model nie myli się przy założeniu, że punkt odcięcia odpowiada prawdopodobieństwu a-priori. Wtedy faktycznie cała klasa pozytywna jest po jednej stronie, a cała klasa negatywna po drugiej stronie punktu cut-off.

Przy każdym innym cut-off model teoretycznie idealny popełnia mniejszy lub większy błąd.
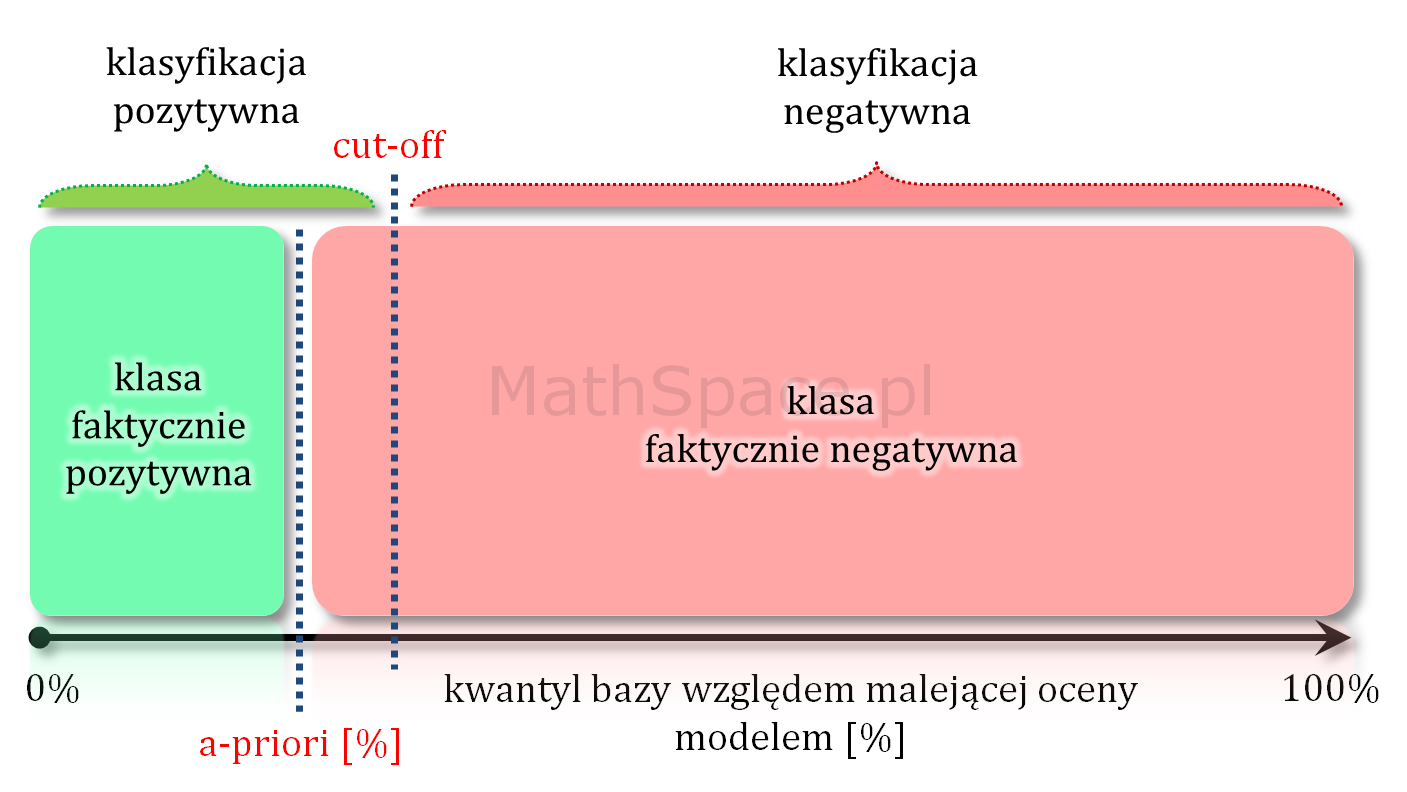
Ile istnieje różnych modeli teoretycznie idealnych?
Liczba różnych modeli teoretycznie idealnych to funkcja liczności klasy faktycznie pozytywnej i liczności klasy faktycznie negatywnej. Liczba ta będzie iloczynem możliwych permutacji w klasie pozytywnej i możliwych permutacji w klasie negatywnej. Takie modele, z punktu widzenia klasycznej oceny jakości klasyfikacji, są nierozróżnialne (dlatego na wykresach oznaczamy tylko jeden). Sytuacja może się zmienić, jeśli, w celu lepszego uporządkowania, rozważymy dodatkowe cechy (oprócz samej przynależności do badanej klasy), takie jak: wartość klienta, oczekiwany life-time, etc…
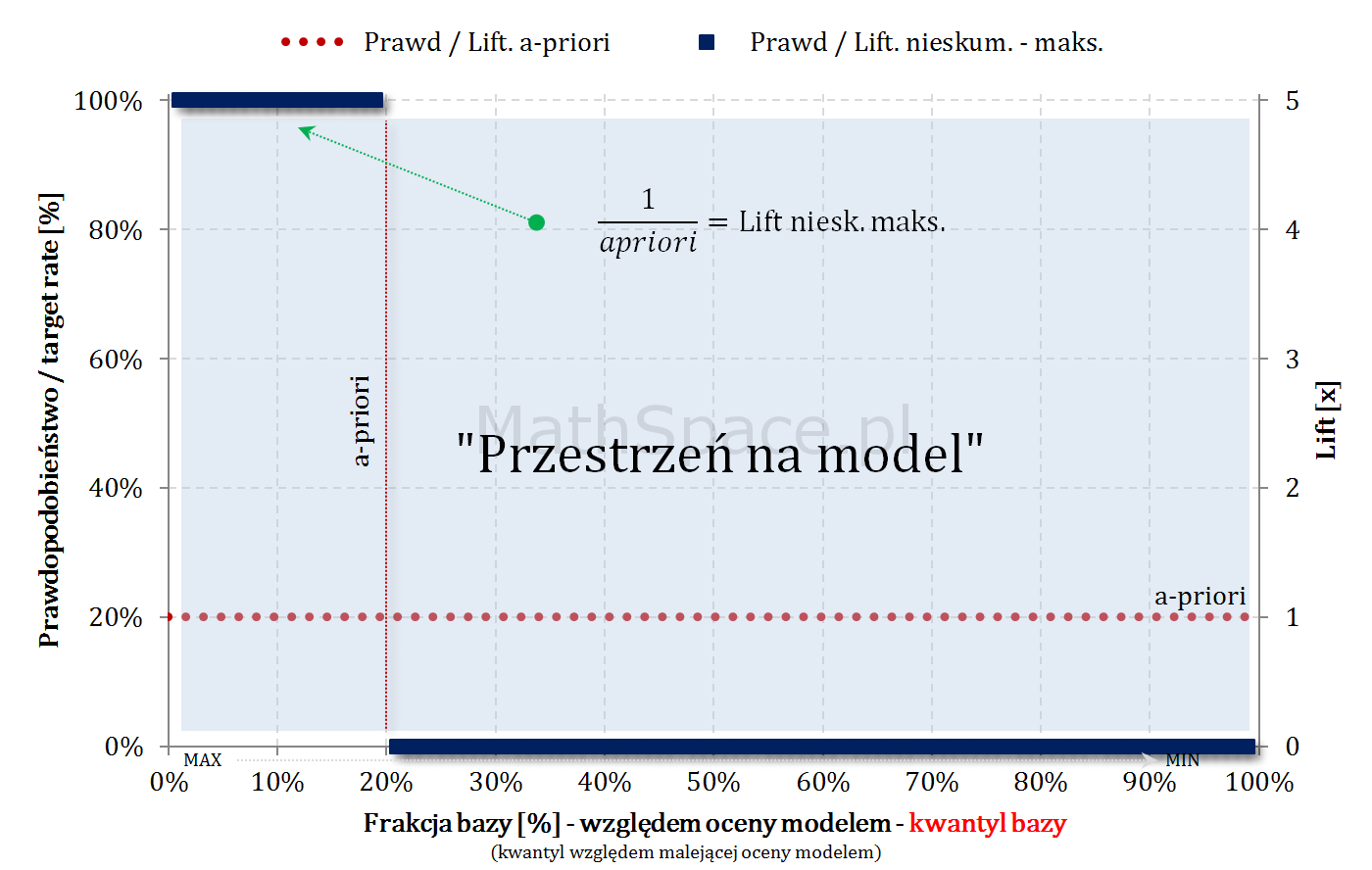
Model teoretycznie idealny i maksymalny Lift nieskumulowany
Lift nieskumulowany to stosunek prawdopodobieństwa w przedziale bazy $\Delta q_n$ i prawdopodobieństwa a-priori (w całej bazie).
$$Lift.Nieskum=\frac{p(1|\Delta n)}{p(1)}$$
Jeśli baza jest uszeregowana malejąco względem oceny modelem, maksymalny możliwy lift nieskumulowany będzie funkcją dwuwartościową.
$$Lift.Nieskum(q)=\begin{cases}\frac{1}{apriori}&\text{dla}\quad q\leq apriori\\0&\text{dla}\quad q>apriori\end{cases}$$
$q$ – kwantyl bazy (malejąco względem oceny modelem)
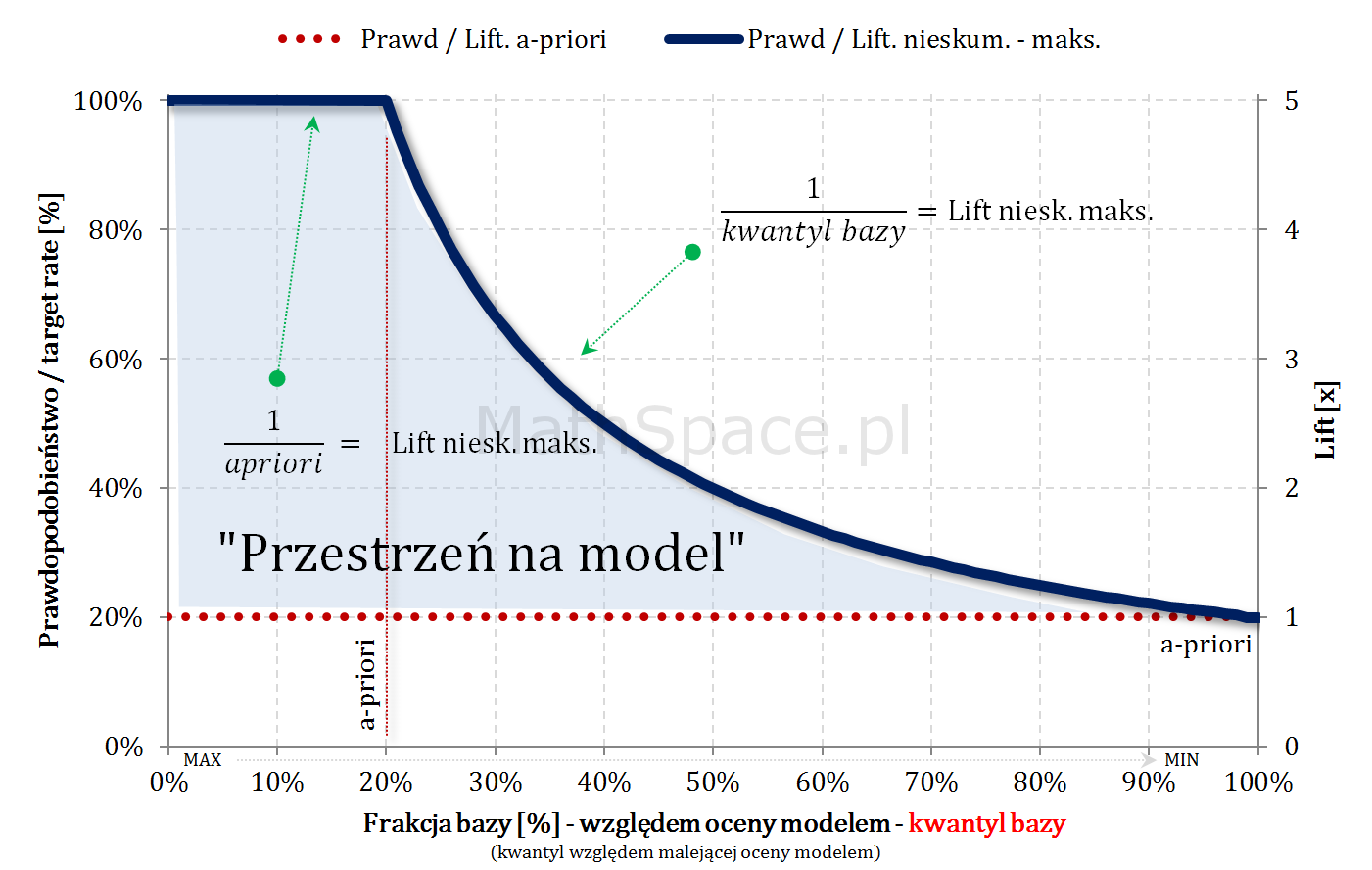
Model teoretycznie idealny i maksymalny Lift skumulowany
Również w przypadku skumulowanym, będąc „na lewo od a-priori”, maksymalny możliwy lift skumulowany wynosi $\frac{1}{apriori}$ (cały czas mamy do dyspozycji „1-dynki”). Jeśli „cut-off przekroczy kwantyl a-priori”, klasyfikacja pozytywna zaczyna być „zaśmiecana” frakcją False-Positive, gdyż nie ma już „1-dynek” – co wynika z najlepszego możliwego porządku (model teoretycznie idealny) – tzn. wszystkie obiekty z klasy faktycznie pozytywnej znajdują się w kwantylach z przedziału $[0,apriori$$.
$$Lift.Skum(q)=\begin{cases}\frac{1}{apriori}&\text{dla}\quad q\leq apriori\\\frac{1}{q}&\text{dla}\quad q>apriori\end{cases}$$
$q$ – kwantyl bazy (malejąco względem oceny modelem)
Dlaczego $\frac{1}{q}$? Przyjmijmy $q>apriori$, wtedy
- $q$ to rozmiar „bazy”
- $apriori$ to rozmiar klasy faktycznie pozytywnej w rozważanej „bazie”
$$p\big(1\big|~[0,q]~\big)=\frac{apriori}{q}$$
$$Lift.Skum(q)=\frac{p\big(1\big|~[0,q]~\big)}{p(1)}=\frac{apriori}{q\times apriori}=\frac{1}{q}$$
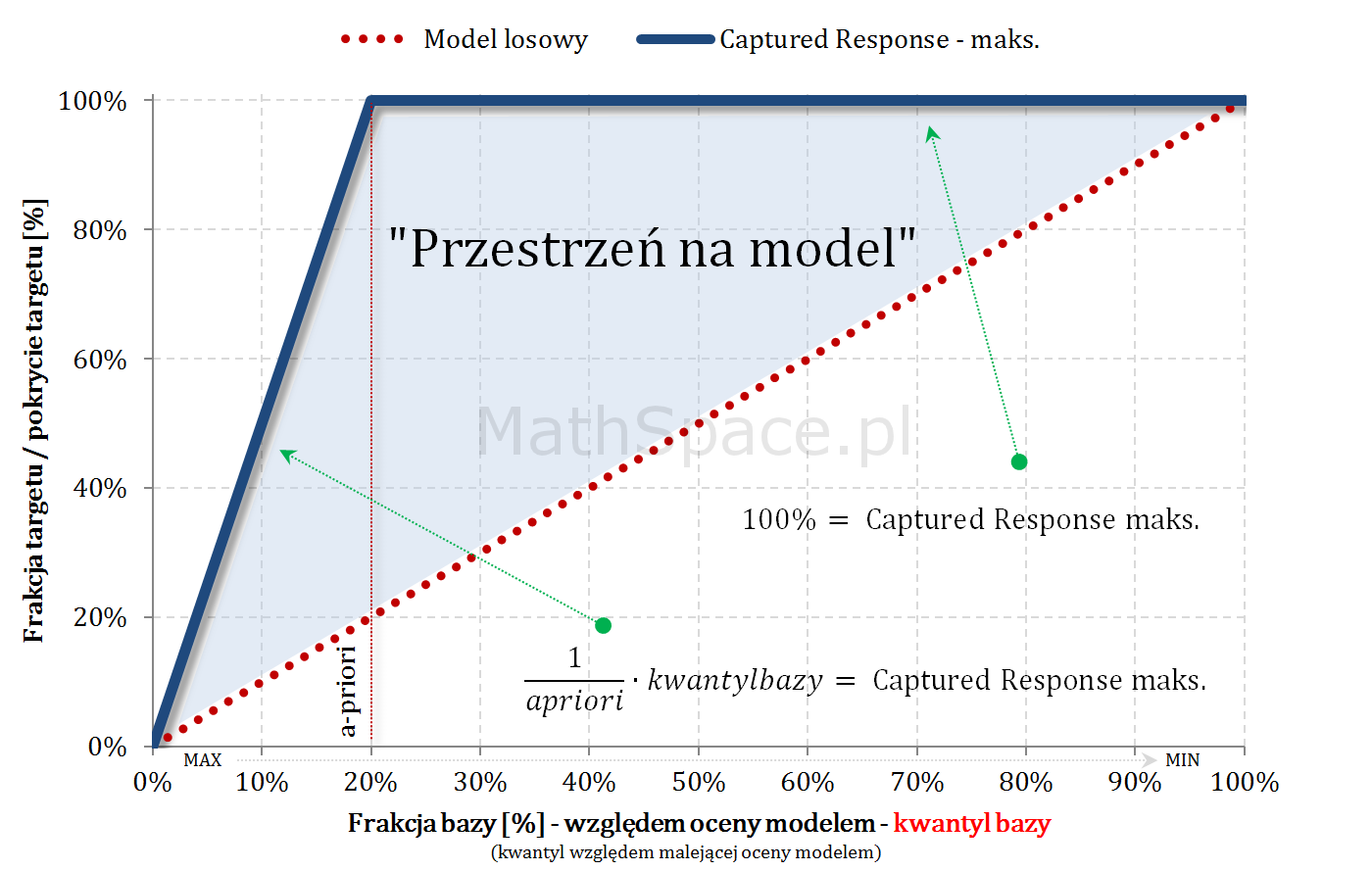
Model teoretycznie idealny i maksymalny Captured Response
Dysponując najlepszym możliwym uporządkowaniem krzywa Captured Response liniowo rośnie dla argumentów „na lewo” od apriori – każdy dodany obiekt, to klasa faktycznie pozytywna. W punkcie „apriori” całość targetu jest już pokryta – zatem wartość krzywej to 100%.
$$Capt.Resp(q)=\begin{cases}\frac{q}{apriori}&\text{dla}\quad q\leq apriori\\1&\text{dla}\quad q>apriori\end{cases}$$
$q$ – kwantyl bazy (malejąco względem oceny modelem)
Model teoretycznie idealny i ROC
- Jeśli cut-off jest „na lewo” od a-priori: pokrywamy wyłącznie elementy klasy faktycznie pozytywnej, zatem rośnie wyłącznie TPR, przy zerowym FPR.
- Dla cut-off odpowiadającego a-priori: pokryto 100% klasy faktycznie pozytywnej (TPR = 100%), jednocześnie nie popełniając żadnego błędu (FPR = 0%).
- Dla cut-off większego od a-priori: TPR już wcześniej osiągnęło 100%, teraz klasyfikując pozytywnie popełniamy coraz większy błąd – tzn. FPR zaczyna rosnąć.
- Dla cut-off = 1: pokryliśmy całość klasy faktycznie pozytywnej (TPR=100%), jednak w tym samym kroku wszelkie obiekty faktycznie negatywne zaliczyliśmy do klasy pozytywnej (FPR=100%).
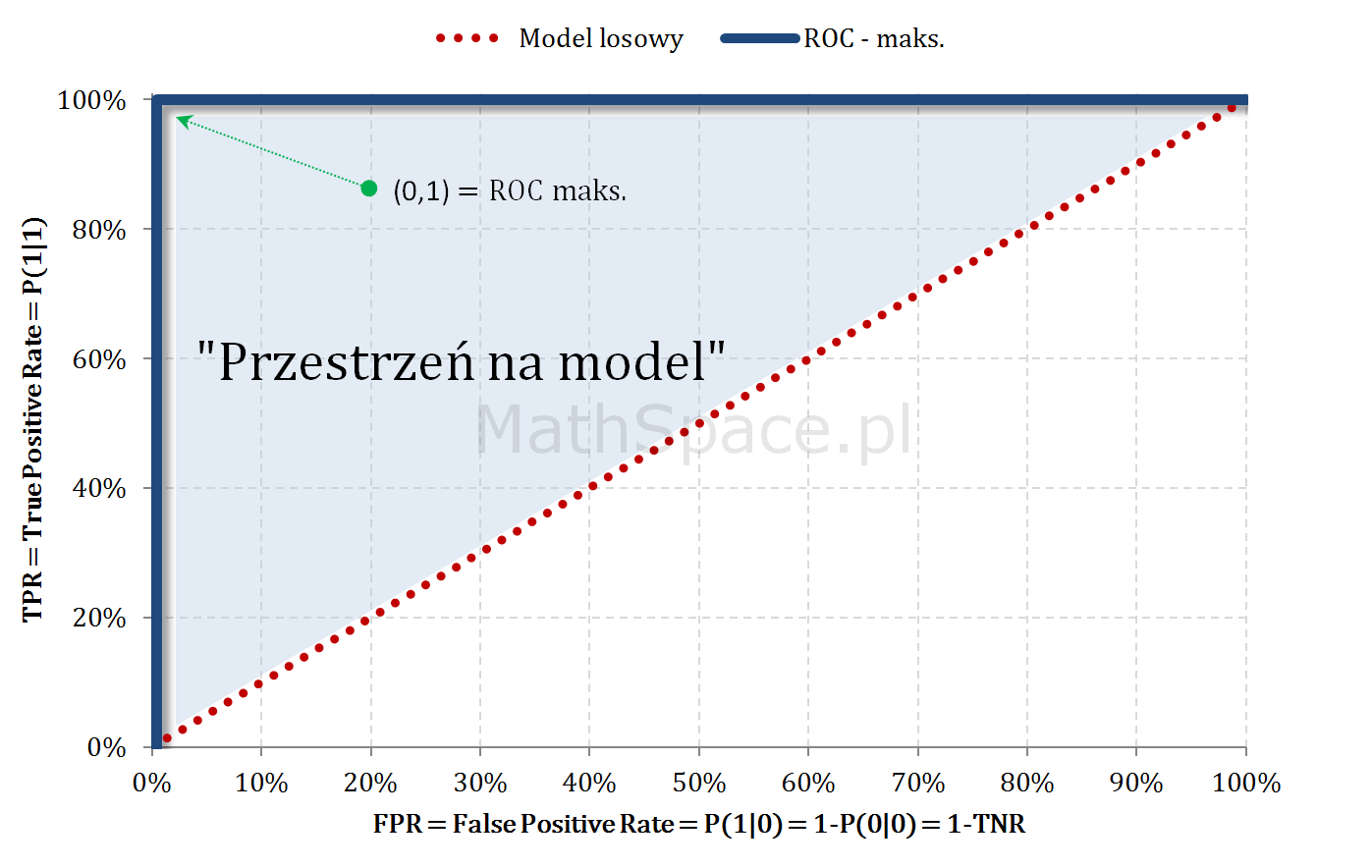
„Przestrzeń na model” – czyli sens budowy modelu
- Dla dużych a-priori (np. 50-60%) przestrzeń na model (tzn. możliwy do osiągnięcia lift) jest bardzo mała. W takich sytuacjach należy najpierw zadać sobie pytanie co chcemy osiągnąć, czym jest target, czy nie istnieją proste reguły biznesowe odpowiadające naszym potrzebom? Duże a-priori nie jest przypadkiem abstrakcyjnym – szereg pytań dotyczy cech / zdarzeń bardzo częstych w bazach / populacjach, np: czy rodzina ma dziecko?, czy ktoś posiada samochód?, etc..
- Małe a-priori (np. kilka promili) daje bardzo dużą przestrzeń na model (typowo duży osiągany lift), ale należy pamiętać, że 5 razy 0 daje 0!! Przykładowa kalkulacja:
- a-priori = 0.5%
- lift (na którymś niskim centylu) = 10
- wtedy prawdopodobieństwo targetu na bazie klasyfikowanej pozytywnie = 0.5% * 10 = 5%
- wtedy w 95% przypadkach mylimy się – owszem możemy pokryć sporą część targetu, ale sami sobie odpowiedzcie czy nieprawidłowy komunikat do 95% grupy ma sens?
- Pośrednie a-priori (kilka – kilkanaście procent) – sytuacja optymalna 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.



