Do napisania 16 części cyklu „Ocena jakości klasyfikacji” zainspirował mnie Kolega i dawny współpracownik! Michał – dzięki za „hint” 🙂 Dziś wskażę pewien sympatyczny punkt przecięcia, którego znajomość jest przydatna, a już z pewnością można „zaszpanować” 🙂 Wpis stanowi zdecydowane wzbogacenie serii „Tips & Tricks na krzywych”.
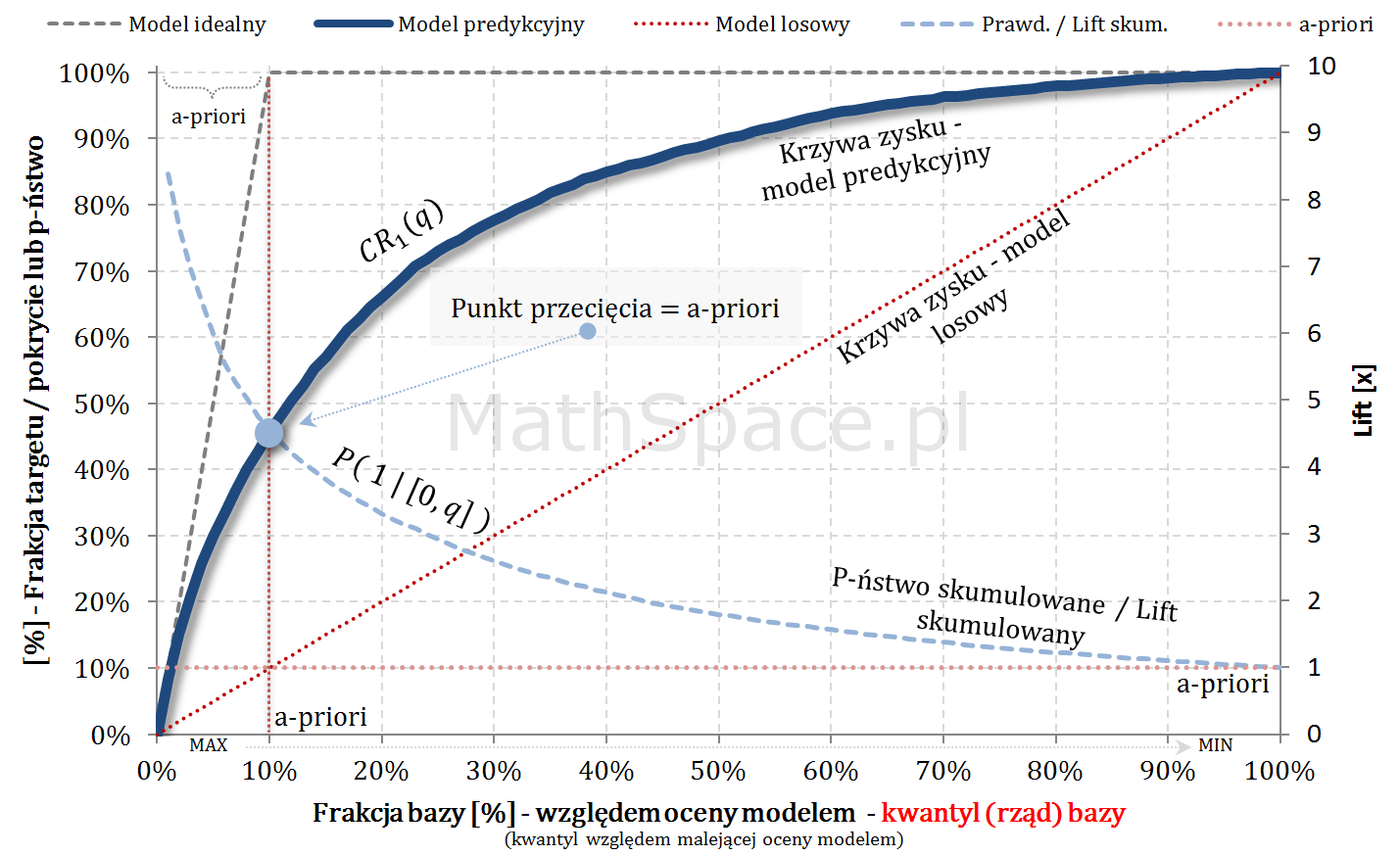
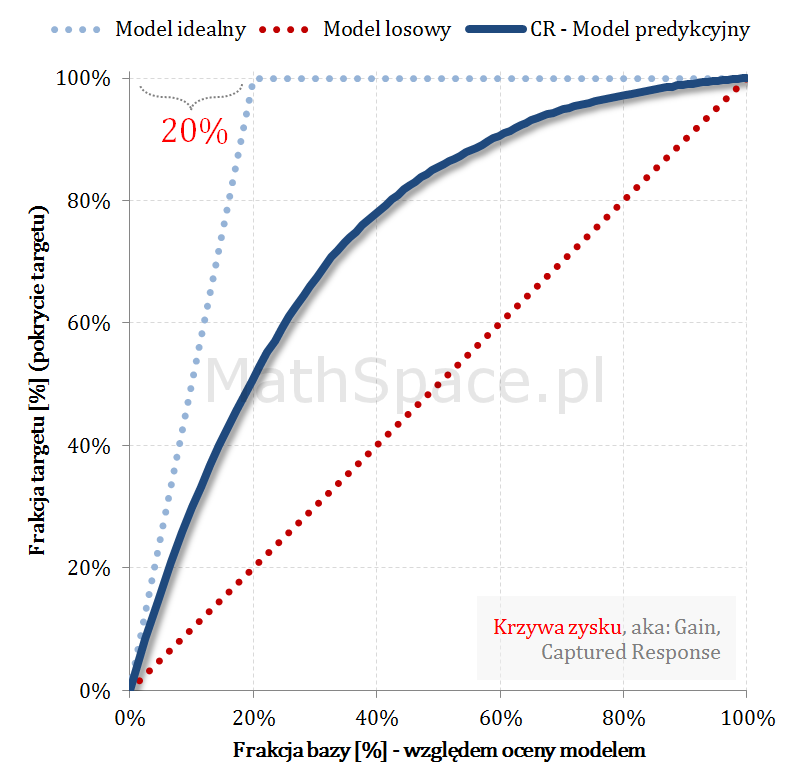
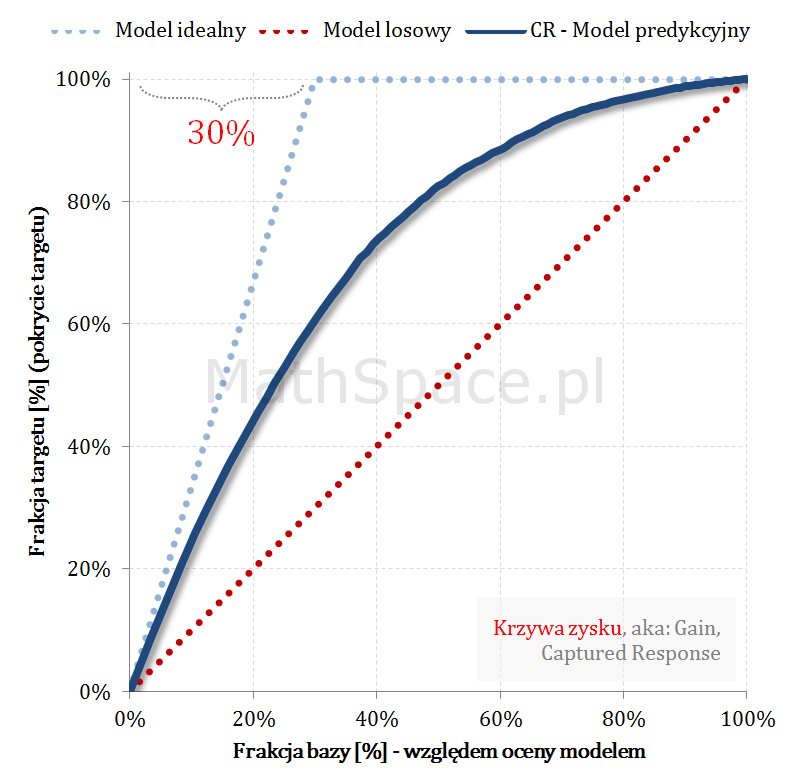
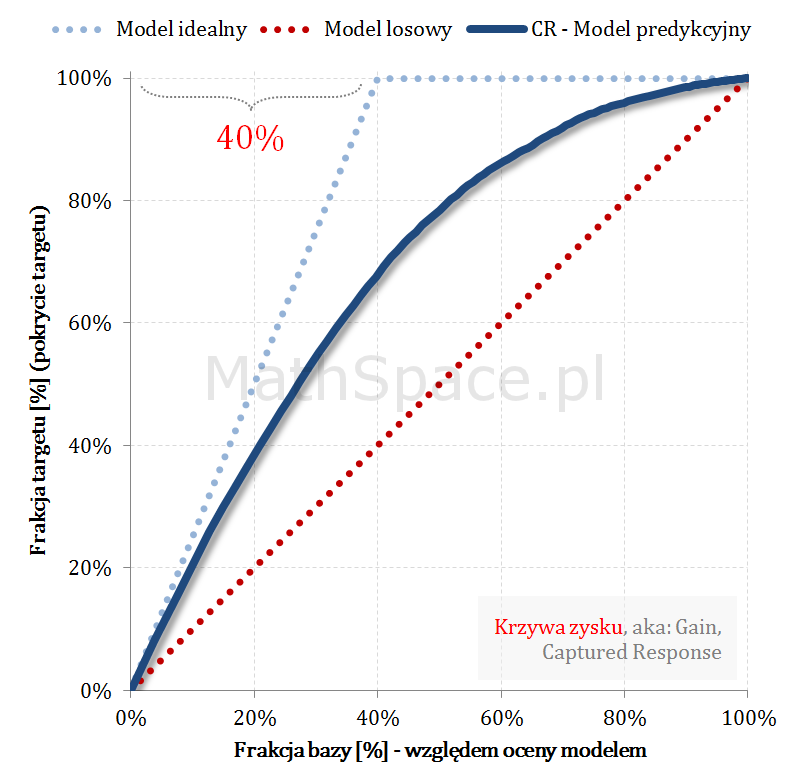
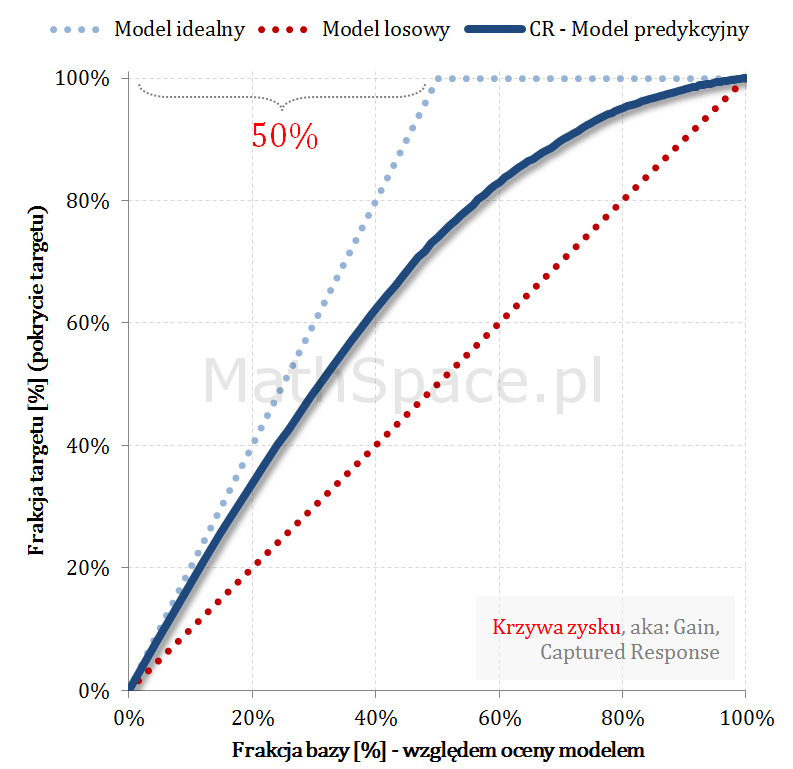
Krzywe Captured Response (TPR) i prawdopodobieństwo skumulowane (PPV, Precision) przecinają się w punkcie a-priori 🙂
Dowód: zaczynamy od oznaczeń:
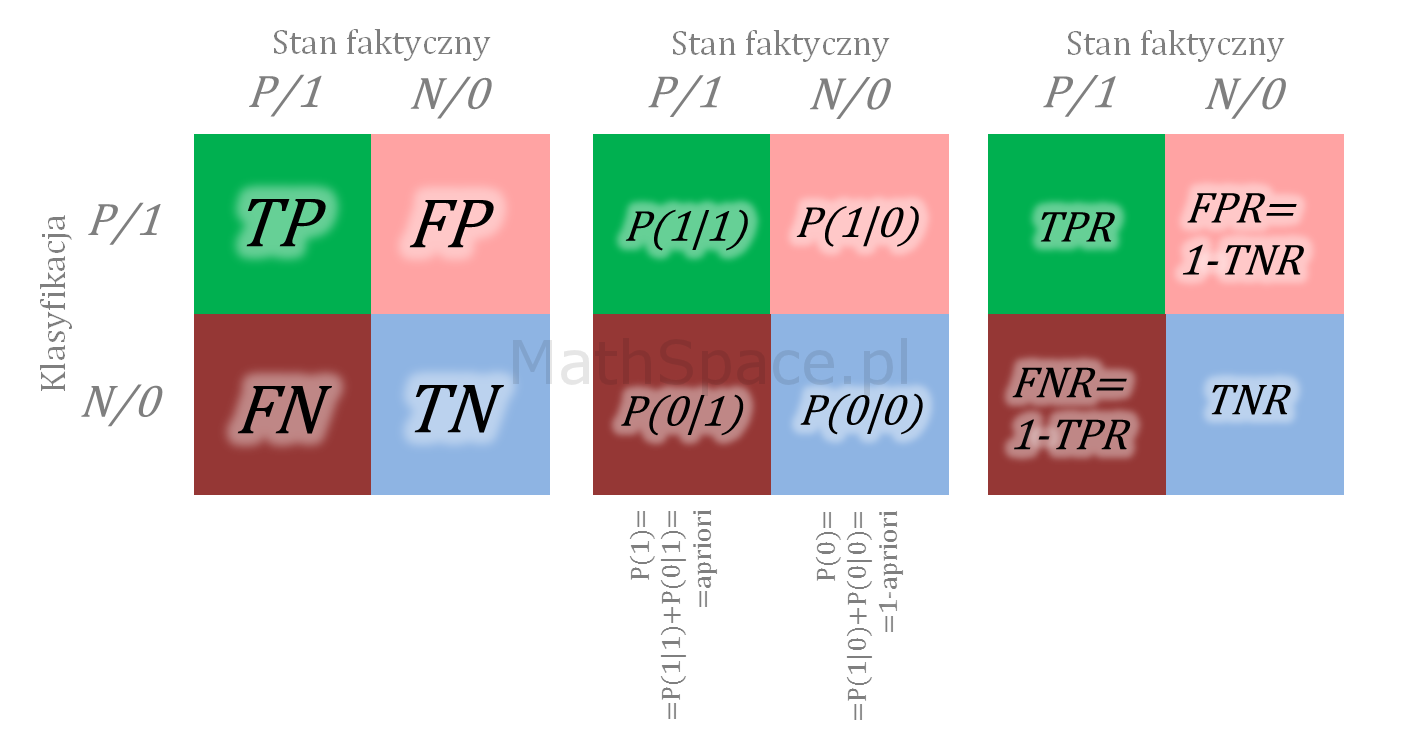
$N=N_1+N_0$ – liczba obiektów w populacji: total, z klasy pozytywnej „1”, z klasy negatywnej „0”;
$q$ – cut-off (jako kwantyl – a dokładnie jego rząd – względem malejącej oceny modelem);
Do czego „sympatyczny” punkt przecięcia może się przydać?
Znajomość punktu przecięcia może się przydać do weryfikacji poprawności analizowanych wykresów i ich spójności z założeniami. Przykładowo – jeśli analityk na jednym wykresie naniesie Captured Response wraz z modelem idealnym, następnie do wykresu doda p-ństwo skumulowane (czyli PPV), i jeśli te krzywe przetną się w innym punkcie niż „aprirori”, to gdzieś mamy błąd! Być może prezentowane wykresy przedstawiają różne modele?
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Wskaźnik Giniego, który opisałem w części #7 poświęconej krzywej ROC, jest jednym z najważniejszych narzędzi wykorzystywanych w procesie oceny jakości klasyfikacji. Choć krzywa ROC jest ważna i bardzo przydatna, to z mojego doświadczenia wynika, że większość analityków woli wykreślać krzywą Captured Response. Sądzę, że wszyscy intuicyjnie czujemy, że „Gini z ROC” i „Gini z Captured Response” to to samo 🙂 Ale dlaczego tak jest? 🙂 Dziś odpowiem na to pytanie, jednocześnie wzbogacając serię „Tips & Tricks na krzywych”!
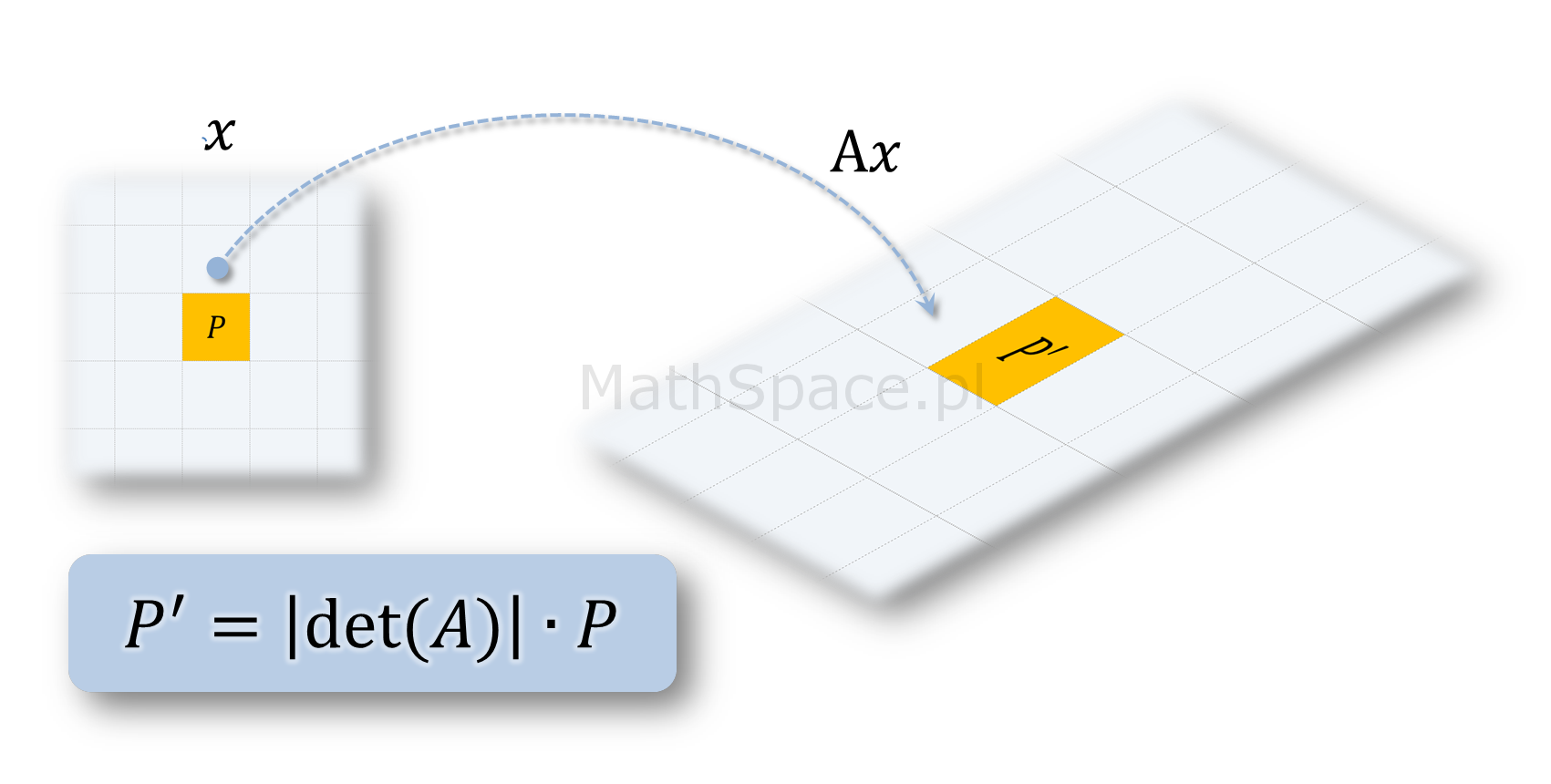
Wyznacznik macierzy przekształcenia liniowego i współczynnik zmiany pola powierzchni
Jeśli analizujemy przekształcenie liniowe
$$Ax$$
gdzie $A$ jest macierzą przekształcenia liniowego, a $x$ wektorem, to wyznacznik
$$\text{det}(A)$$
jest współczynnikiem o jaki zmienia się pole powierzchni / objętość / miara figury / obiektu transformowanego poprzez przekształcenie liniowe $Ax$. Polecam poniższy film.
Wyznacznik macierzy przekształcenia liniowego krzywej ROC w krzywą Captured Response
Z powyższego wynika, że pole powierzchni pomiędzy przestrzenią, w której „osadzona” jest krzywa ROC, a przestrzenią „zawierającą” krzywą Captured Response, powinno się skalować poprzez współczynniki $1-apriori$. Sprawdźmy 🙂
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
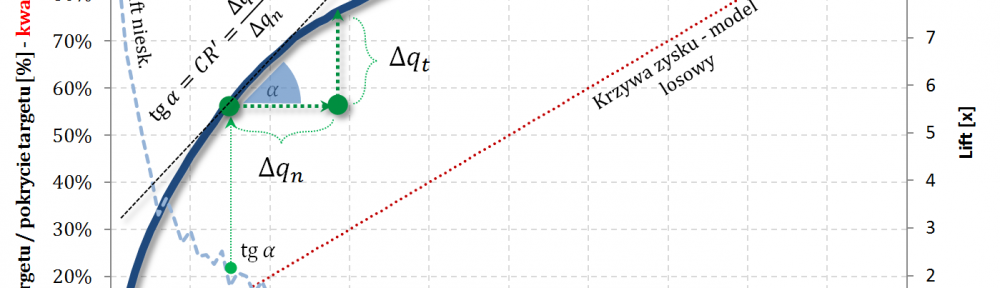
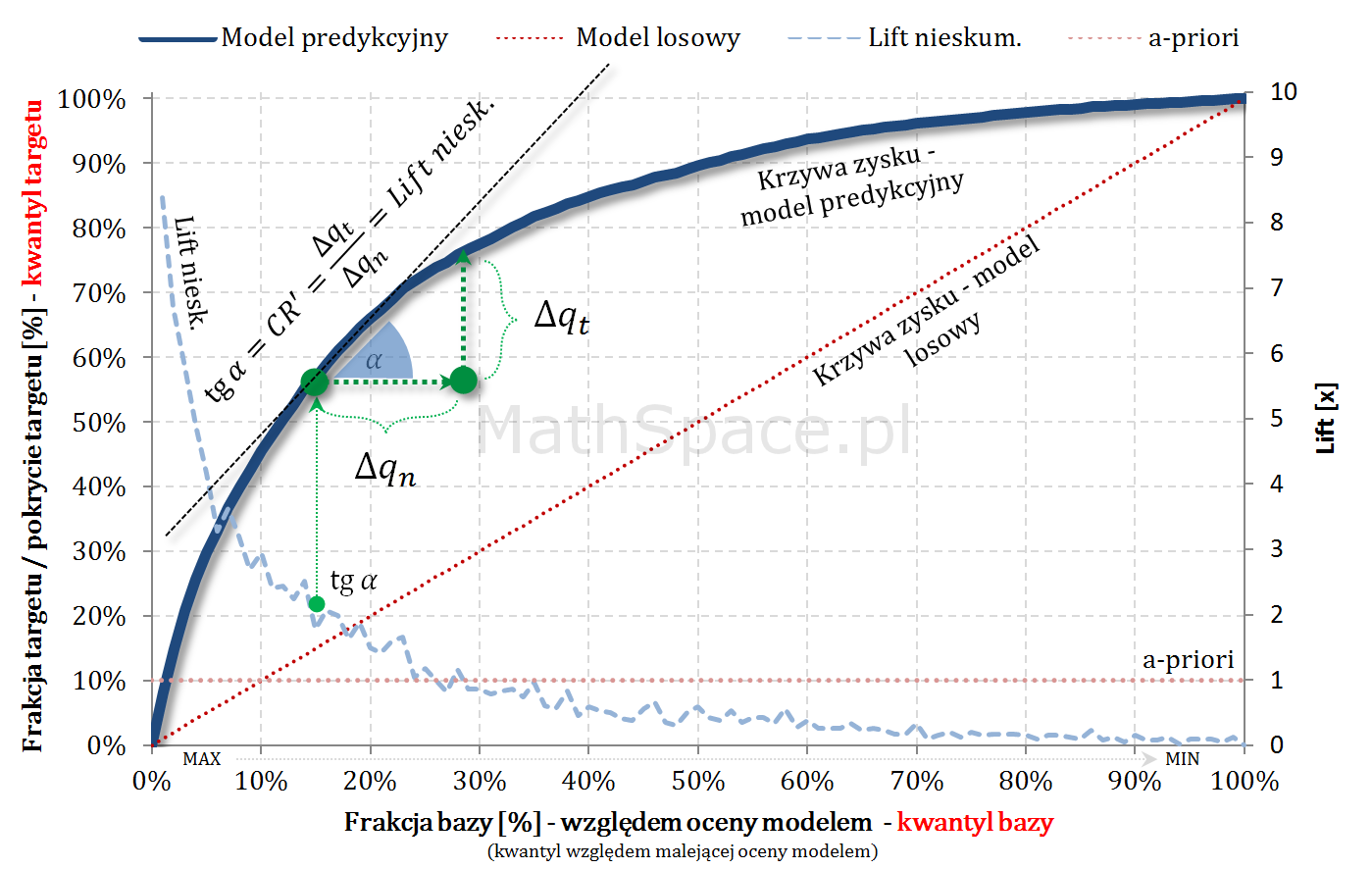
Fajne 🙂 prawda? Lift nieskumulowany można jednoznacznie wyprowadzić z krzywej Captured Response poprzez analizę „lokalnych” przyrostów frakcji bazy $\Delta q_n$ i frakcji targetu $\Delta q_t$.
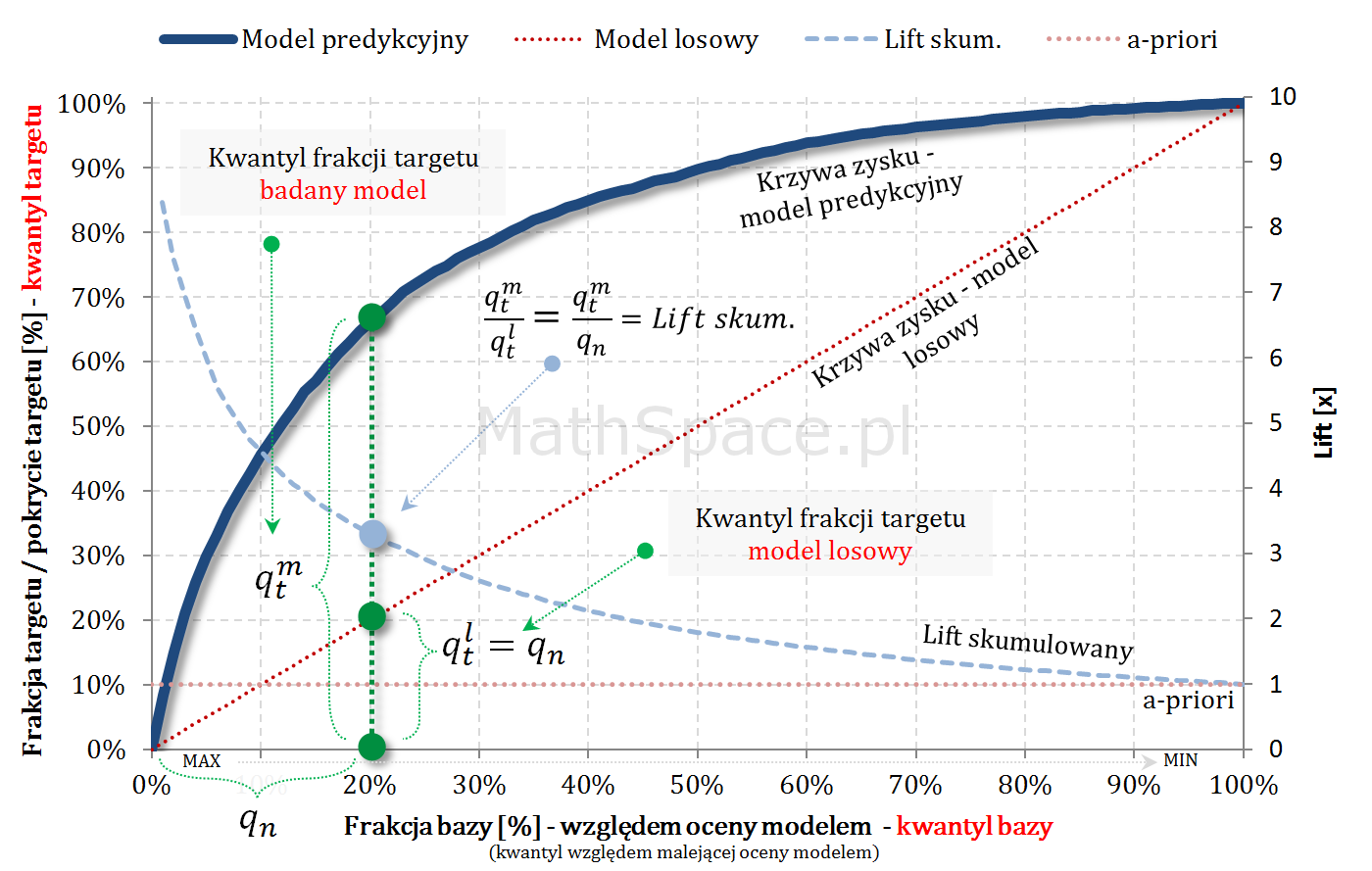
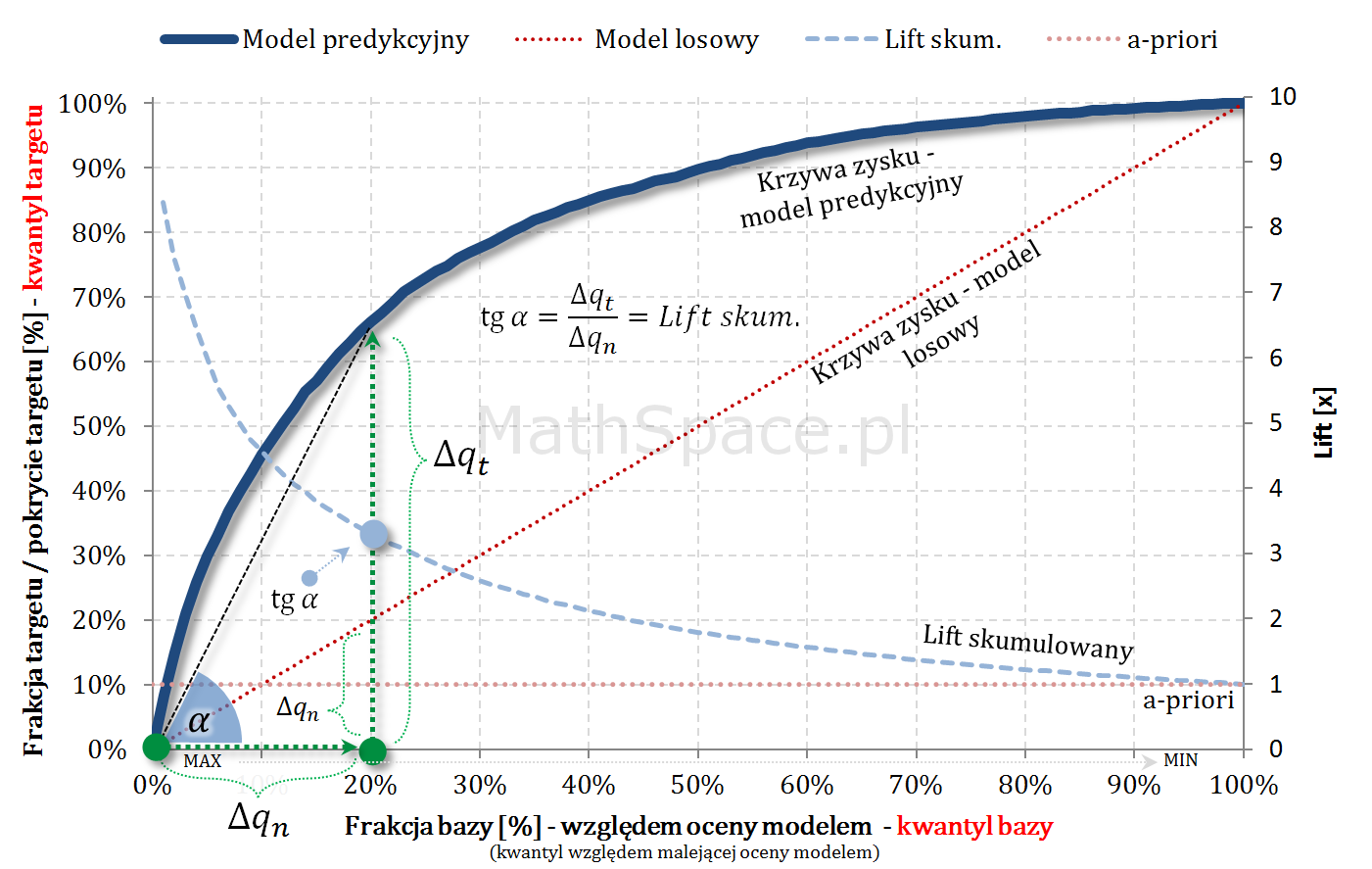
Captured Response – stosunek wartości dla badanego modelu oraz wartości dla modelu losowego to Lift skumulowany
Oznaczamy:
$N=N_1+N_0$ – liczba obiektów (np. klientów): total, z klasy „1”, z klasy”0″;
$q_n$ – kwantyl bazy, czyli argument na osi poziomej;
$n=n_1+n_0$ – liczba obiektów składających się na kwantyl $q_n$: total, z klasy „1”, z klasy”0″;
$q_t^m$ – kwantyl targetu, czyli wartość Captured Response dla badanego modelu;
$q_t^l$ – kwantyl targetu, czyli wartość Captured Response dla modelu losowego;
Kolejny fajny wniosek 🙂 , który można również łatwo uzasadnić na bazie wyżej opisanej zależności pomiędzy Captured Response i Liftem nieskumulowanym. Mianowicie wystarczy „delty liczyć” od punktu $(0,0)$ i zauważyć, że dla modelu losowego $q_t = q_n$. Pokazałem to na rysunku poniżej.
Lift skumulowany można jednoznacznie wyprowadzić z krzywej Captured Response poprzez analizę „globalnych” przyrostów frakcji bazy $\Delta q_n$ i frakcji targetu $\Delta q_t$.
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
!!! Uwaga: dla uproszczenia – wszędzie tam, gdzie piszę kwantyl, mam na myśli jego rząd !!!
Model teoretycznie idealny a prawdopodobieństwo a-priori
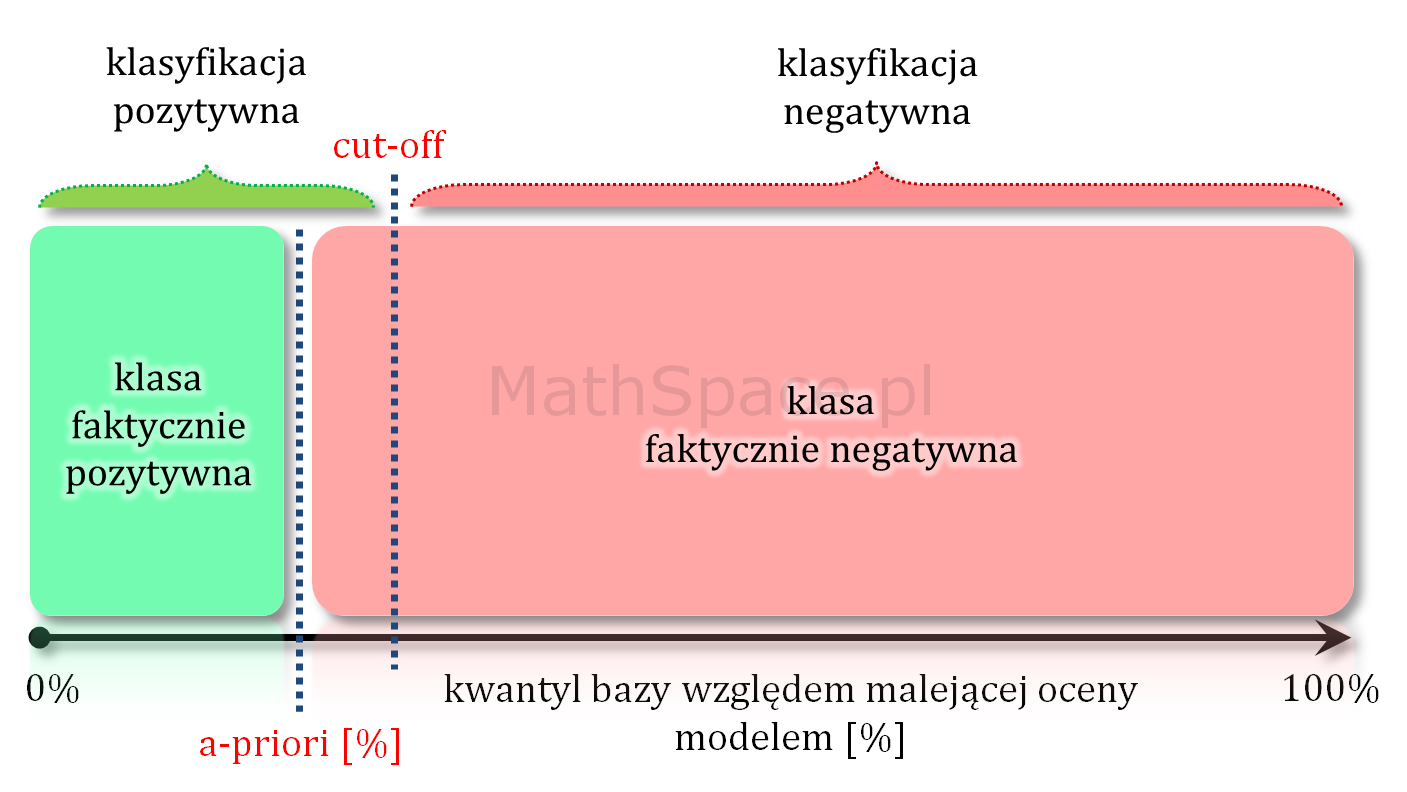
Model teoretycznie idealny to taki model, który daje najlepsze możliwe uporządkowanie – inaczej mówiąc najlepszą możliwą separację klas. Taki model nie myli się przy założeniu, że punkt odcięcia odpowiada prawdopodobieństwu a-priori. Wtedy faktycznie cała klasa pozytywna jest po jednej stronie, a cała klasa negatywna po drugiej stronie punktu cut-off.
Przy każdym innym cut-off model teoretycznie idealny popełnia mniejszy lub większy błąd.
Ile istnieje różnych modeli teoretycznie idealnych?
Liczba różnych modeli teoretycznie idealnych to funkcja liczności klasy faktycznie pozytywnej i liczności klasy faktycznie negatywnej. Liczba ta będzie iloczynem możliwych permutacji w klasie pozytywnej i możliwych permutacji w klasie negatywnej. Takie modele, z punktu widzenia klasycznej oceny jakości klasyfikacji, są nierozróżnialne (dlatego na wykresach oznaczamy tylko jeden). Sytuacja może się zmienić, jeśli, w celu lepszego uporządkowania, rozważymy dodatkowe cechy (oprócz samej przynależności do badanej klasy), takie jak: wartość klienta, oczekiwany life-time, etc…
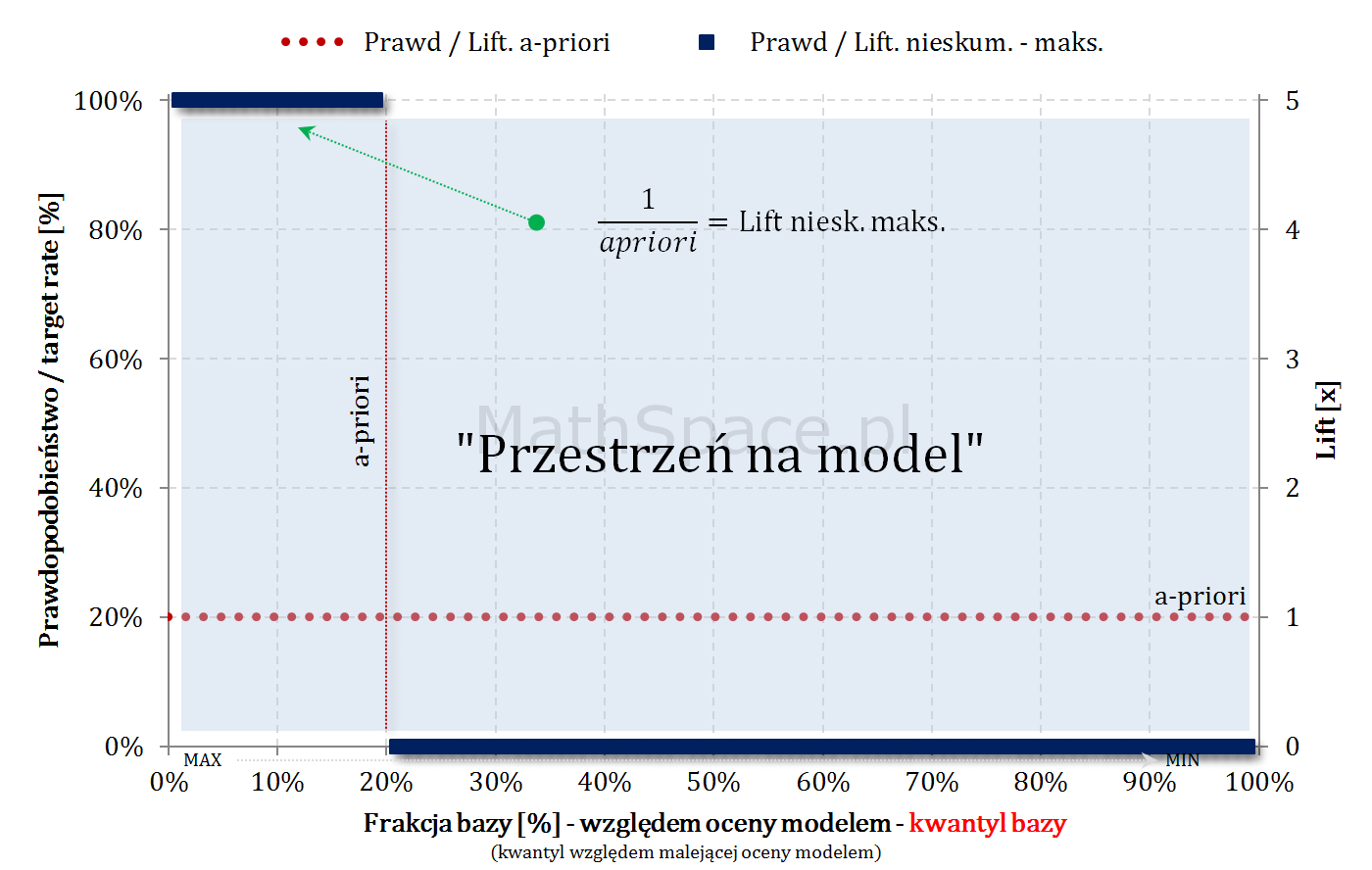
Model teoretycznie idealny i maksymalny Lift nieskumulowany
Lift nieskumulowany to stosunek prawdopodobieństwa w przedziale bazy $\Delta q_n$ i prawdopodobieństwa a-priori (w całej bazie).
$$Lift.Nieskum=\frac{p(1|\Delta n)}{p(1)}$$
Jeśli baza jest uszeregowana malejąco względem oceny modelem, maksymalny możliwy lift nieskumulowany będzie funkcją dwuwartościową.
$q$ – kwantyl bazy (malejąco względem oceny modelem)
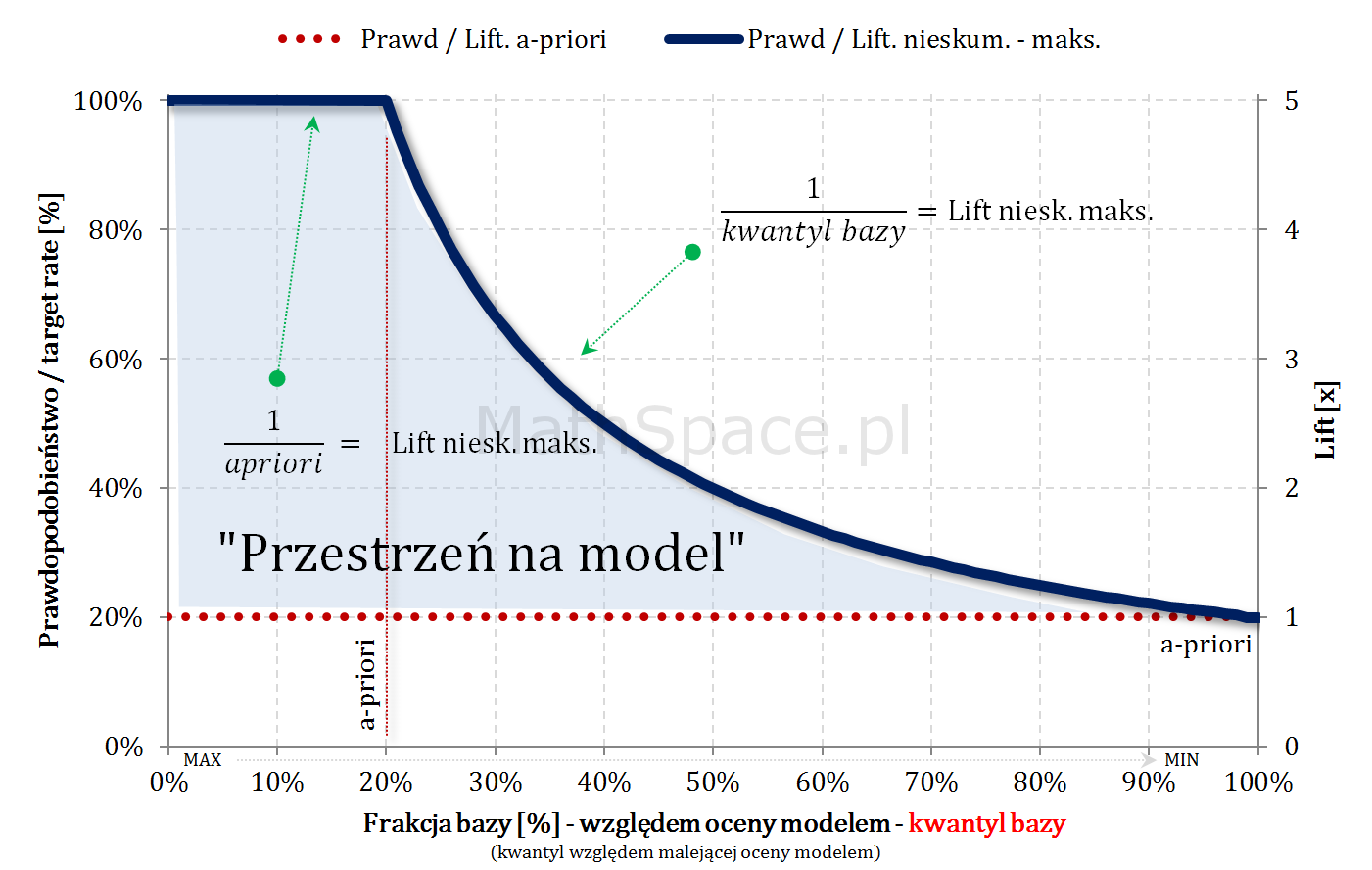
Model teoretycznie idealny i maksymalny Lift skumulowany
Również w przypadku skumulowanym, będąc „na lewo od a-priori”, maksymalny możliwy lift skumulowany wynosi $\frac{1}{apriori}$ (cały czas mamy do dyspozycji „1-dynki”). Jeśli „cut-off przekroczy kwantyl a-priori”, klasyfikacja pozytywna zaczyna być „zaśmiecana” frakcją False-Positive, gdyż nie ma już „1-dynek” – co wynika z najlepszego możliwego porządku (model teoretycznie idealny) – tzn. wszystkie obiekty z klasy faktycznie pozytywnej znajdują się w kwantylach z przedziału $[0,apriori$$.
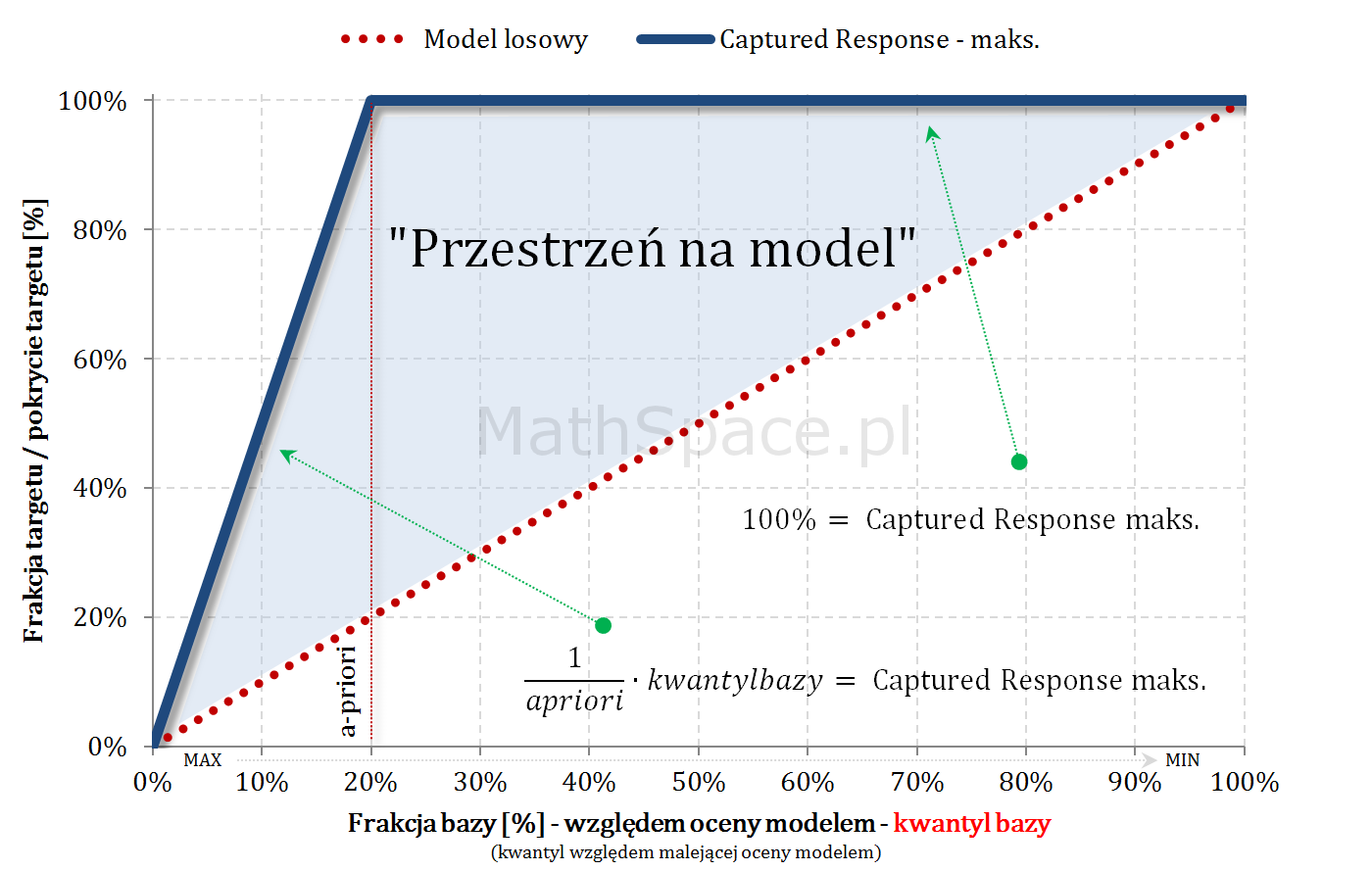
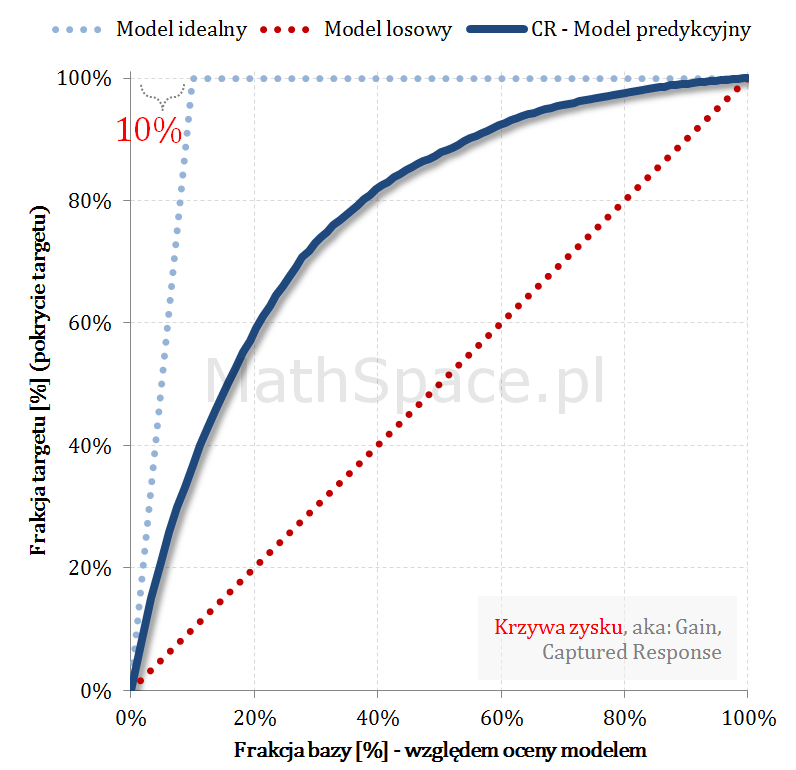
Model teoretycznie idealny i maksymalny Captured Response
Dysponując najlepszym możliwym uporządkowaniem krzywa Captured Response liniowo rośnie dla argumentów „na lewo” od apriori – każdy dodany obiekt, to klasa faktycznie pozytywna. W punkcie „apriori” całość targetu jest już pokryta – zatem wartość krzywej to 100%.
$q$ – kwantyl bazy (malejąco względem oceny modelem)
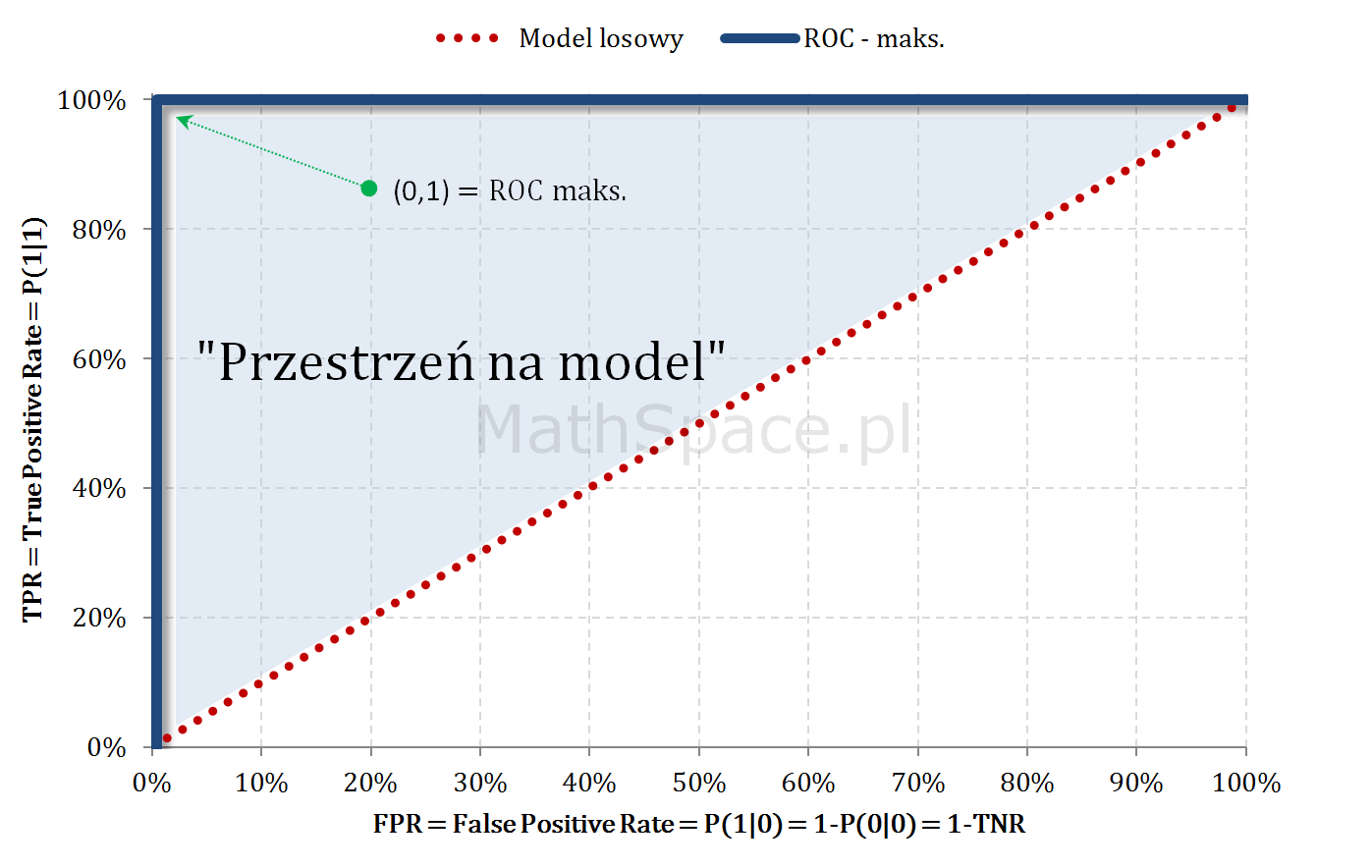
Model teoretycznie idealny i ROC
Jeśli cut-off jest „na lewo” od a-priori: pokrywamy wyłącznie elementy klasy faktycznie pozytywnej, zatem rośnie wyłącznie TPR, przy zerowym FPR.
Dla cut-off odpowiadającego a-priori: pokryto 100% klasy faktycznie pozytywnej (TPR = 100%), jednocześnie nie popełniając żadnego błędu (FPR = 0%).
Dla cut-off większego od a-priori: TPR już wcześniej osiągnęło 100%, teraz klasyfikując pozytywnie popełniamy coraz większy błąd – tzn. FPR zaczyna rosnąć.
Dla cut-off = 1: pokryliśmy całość klasy faktycznie pozytywnej (TPR=100%), jednak w tym samym kroku wszelkie obiekty faktycznie negatywne zaliczyliśmy do klasy pozytywnej (FPR=100%).
„Przestrzeń na model” – czyli sens budowy modelu
Dla dużych a-priori (np. 50-60%) przestrzeń na model (tzn. możliwy do osiągnięcia lift) jest bardzo mała. W takich sytuacjach należy najpierw zadać sobie pytanie co chcemy osiągnąć, czym jest target, czy nie istnieją proste reguły biznesowe odpowiadające naszym potrzebom? Duże a-priori nie jest przypadkiem abstrakcyjnym – szereg pytań dotyczy cech / zdarzeń bardzo częstych w bazach / populacjach, np: czy rodzina ma dziecko?, czy ktoś posiada samochód?, etc..
Małe a-priori (np. kilka promili) daje bardzo dużą przestrzeń na model (typowo duży osiągany lift), ale należy pamiętać, że 5 razy 0 daje 0!! Przykładowa kalkulacja:
a-priori = 0.5%
lift (na którymś niskim centylu) = 10
wtedy prawdopodobieństwo targetu na bazie klasyfikowanej pozytywnie = 0.5% * 10 = 5%
wtedy w 95% przypadkach mylimy się – owszem możemy pokryć sporą część targetu, ale sami sobie odpowiedzcie czy nieprawidłowy komunikat do 95% grupy ma sens?
Pośrednie a-priori (kilka – kilkanaście procent) – sytuacja optymalna 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Właśnie czytasz część #9 cyklu „Ocena jakości klasyfikacji” – a to oznacza, że posiadasz już sporą wiedzę – i masz ochotę na więcej – gratuluję! 🙂
Korelacja rangowa … czy to wystarczy?
W częściach 1-8 skupiałem się na analizie korelacji rangowej. W tym przypadku korelacja rangowa odpowiada na pytanie „jak dobrze uporządkowany jest target w zależności od oceny modelem” – tzn. jak silnie monotoniczna jest zależności pomiędzy score i targetem? Innymi słowy – czy wraz ze wzrostem score, rośnie frakcja True-Positive, i jak silny jest to wzrost? Krzywa lift, czy Captured Response, doskonale to obrazują. Jednak to nie wszystko … W wielu przypadkach niezbędne jest prawidłowe oszacowanie prawdopodobieństwa z jakim zaobserwujemy klasę pozytywną.
Ocena estymacji prawdopodobieństwa – co to?
Załóżmy, że określoną grupę klientów podzieliśmy na dane trenujące i uczące oraz, że na próbie uczącej przygotowaliśmy model predykcyjny szacujący prawdopodobieństwo „bycia klasą pozytywną”. Przyjmijmy, że dla pewnego klienta x model zwrócił prawdopodobieństwo 0.3. W tym przypadku wskaźnik 0.3 oznacza, że np. dla 100 klientów, o tych samych cechach, spodziewamy się około 30 z „klasy pozytywnej” oraz około 70 z „klasy negatywnej”. Ocena estymacji prawdopodobieństwa to weryfikacja na ile możemy ufać oszacowaniu, tutaj 30 vs 70.
W ogólności – chodzi o stwierdzenie czy estymator (czyli nasz model) jest nieobciążony(czyli wolny od błędu systematycznego), a jeżeli jest obciążony, to na ile i w jakich przypadkach. Statystyka matematyczna dostarcza szeregu różnych wskaźników wyznaczających błąd oszacowania dla zmiennej ciągłej – np. błąd średnio-kwadratowy – w tym tekście nie będę się na nich skupiał. Nasz przypadek jest mniej ogólny, a i samej weryfikacji najwygodniej dokonać „organoleptycznie” – tzn. metodą wizualną w wielu krokach 🙂
Kiedy oceniać jakość estymacji prawdopodobieństwa?
Generalnie zawsze! Często same techniki modelowania optymalizują prawdopodobieństwo – np. regresja logistyczna wykorzystująca metodę największej wiarygodności – tu konieczność badania jest oczywista. Inne metody, takie jak drzewa decyzyjne, wraz ze wzrostem drzewa, starają się zmniejszyć zmienność klas w węzłach potomkach / liściach – tu nadal możemy ocenić finalne prawdopodobieństwo – np. na bazie rozkładu klas (o ile liczności są odpowiednio duże). Zasada jest taka – ocena prawdopodobieństwa daje zawsze dodatkową cenną informację w procesie weryfikacji jakości modelu! Jest jednak kilka szczególnych przypadków, kiedy ocena poprawności prawdopodobieństwa jest absolutnie konieczna:
Model będzie stosowany w wyznaczaniu wartości oczekiwanych (np. oczekiwany przychód).
Modele up-lift (np. efekt inkrementalny na bazie różnicy dwóch modeli) – o tym opowiemy kiedyś w szczegółach.
Rekomendatory na bazie „głosowania” modelami propensity (modelami skłonności do skorzystania z produktu / usługi).
I wiele innych …
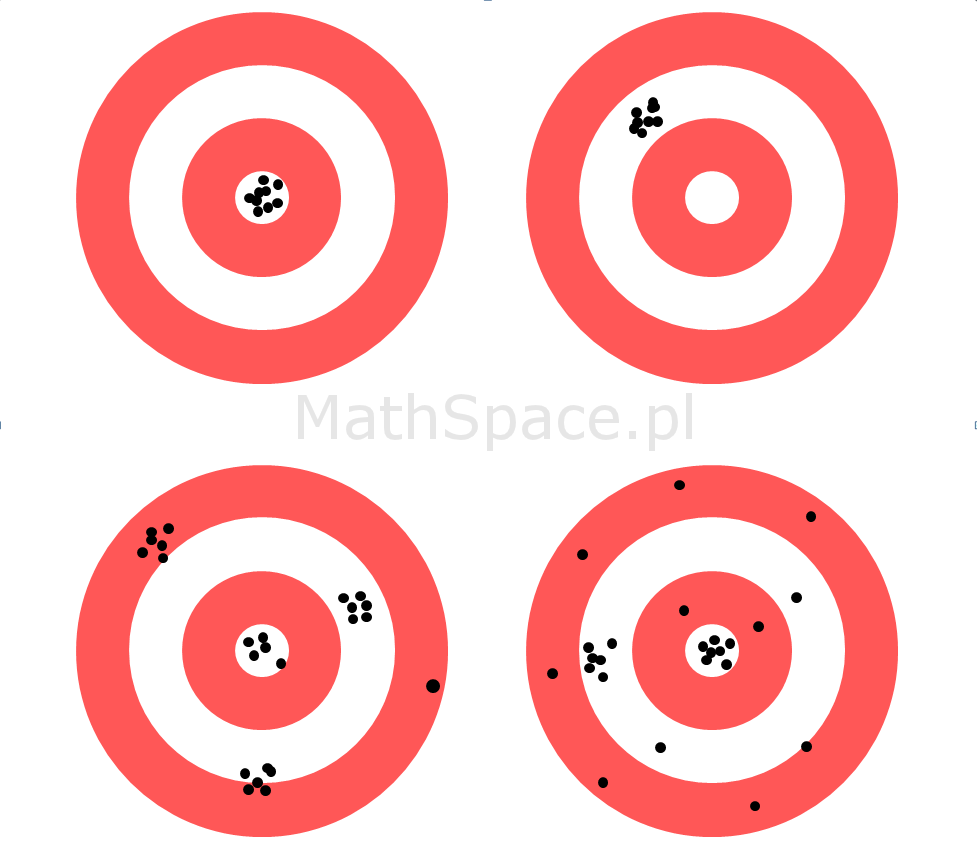
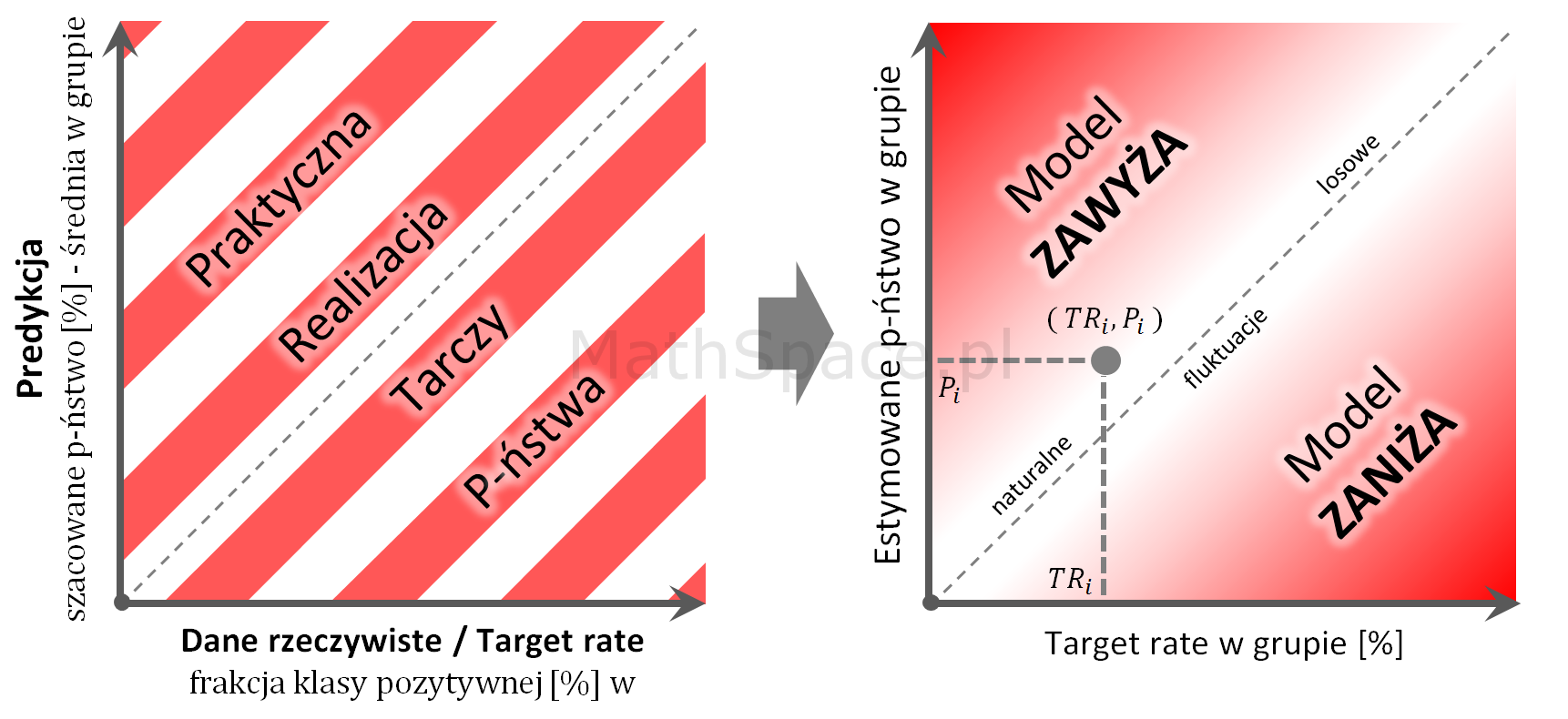
Tarcza prawdopodobieństwa – typowe sytuacje w praktyce
Tarcza prawdopodobieństwa – nazwa moja, nie szukajcie po Wikipedii 🙂 – to ciekawe i proste narzędzie obrazujące schematycznie (w dalszej części również praktycznie) typowe przypadki, na jakie z pewnością natkniecie się w pracy z rzeczywistymi modelami. Czasami jeden obraz wart jest znacznie więcej niż potok słów – zatem zaczynamy.
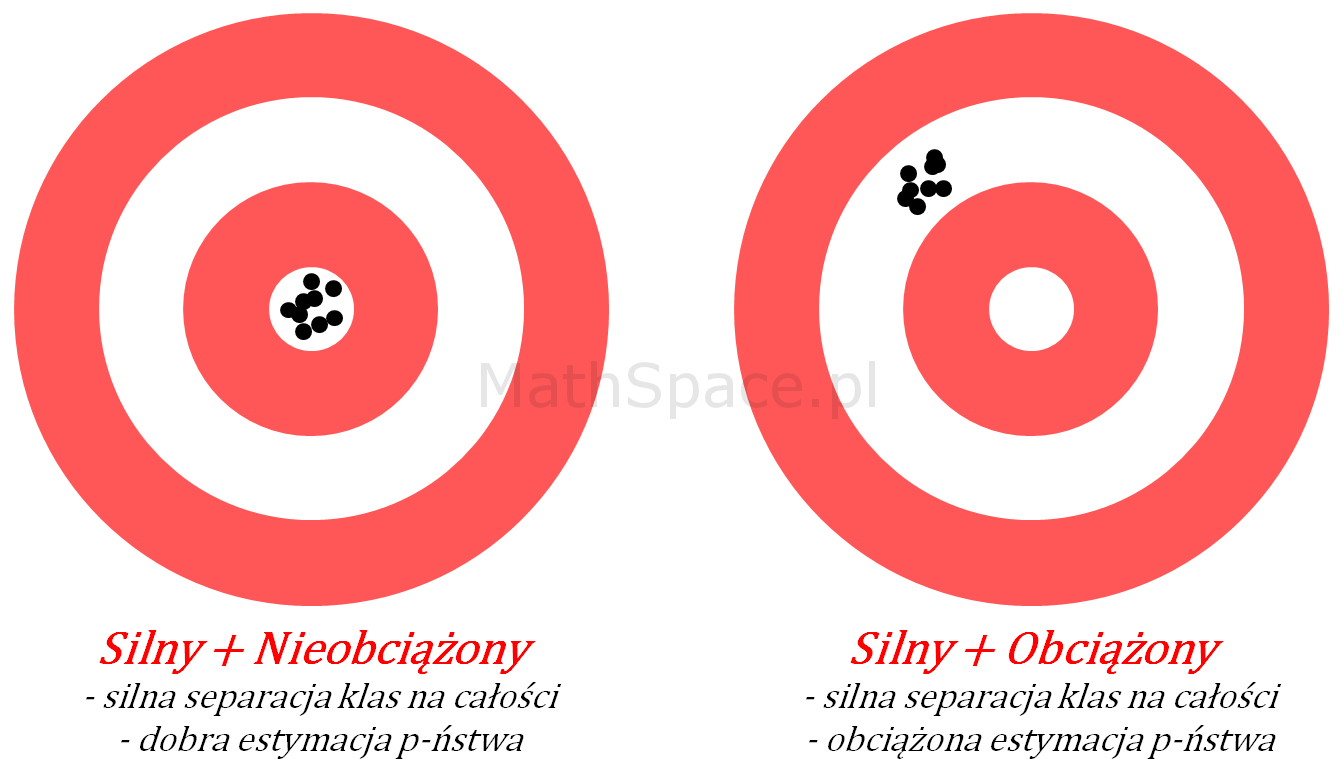
Silny model – schemat
Przypadek 1: Silny model z dobrą estymacją prawdopodobieństwa
Schemat obrazuje sytuację, kiedy model trafia „w punkt” – czyli powtarzalnie i precyzyjnie odróżniany jest „cel” od reszty „tarczy”. Świadczy to o wysokiej separacji klas (klasa pozytywna vs klasa negatywna), spodziewany wysoki indeks Giniego, jak też oczekiwana dobra jakość estymacji prawdopodobieństwa. Na schemacie „centrum” jest tym miejscem, w które trafia model.
Akcja:Model gotowy do wykorzystania.
Przypadek 2: Silny model z obciążoną estymacją prawdopodobieństwa
Tym razem schemat przedstawia model o wysokim skupieniu – czyli mamy dużą powtarzalność wyników wraz z ich skupieniem, natomiast samo skupienie jest przesunięte w stosunku do punktu środkowego. Interpretacja – mamy do czynienia z silną separacją klas (wysoki indeks Giniego), natomiast szacowanie prawdopodobieństwa obarczone jest systematycznym błędem (obciążeniem).
Akcja:Model wymaga kalibracji, może być warunkowo stosowany w sytuacjach, kiedy opieramy się wyłącznie na korelacji rangowej.
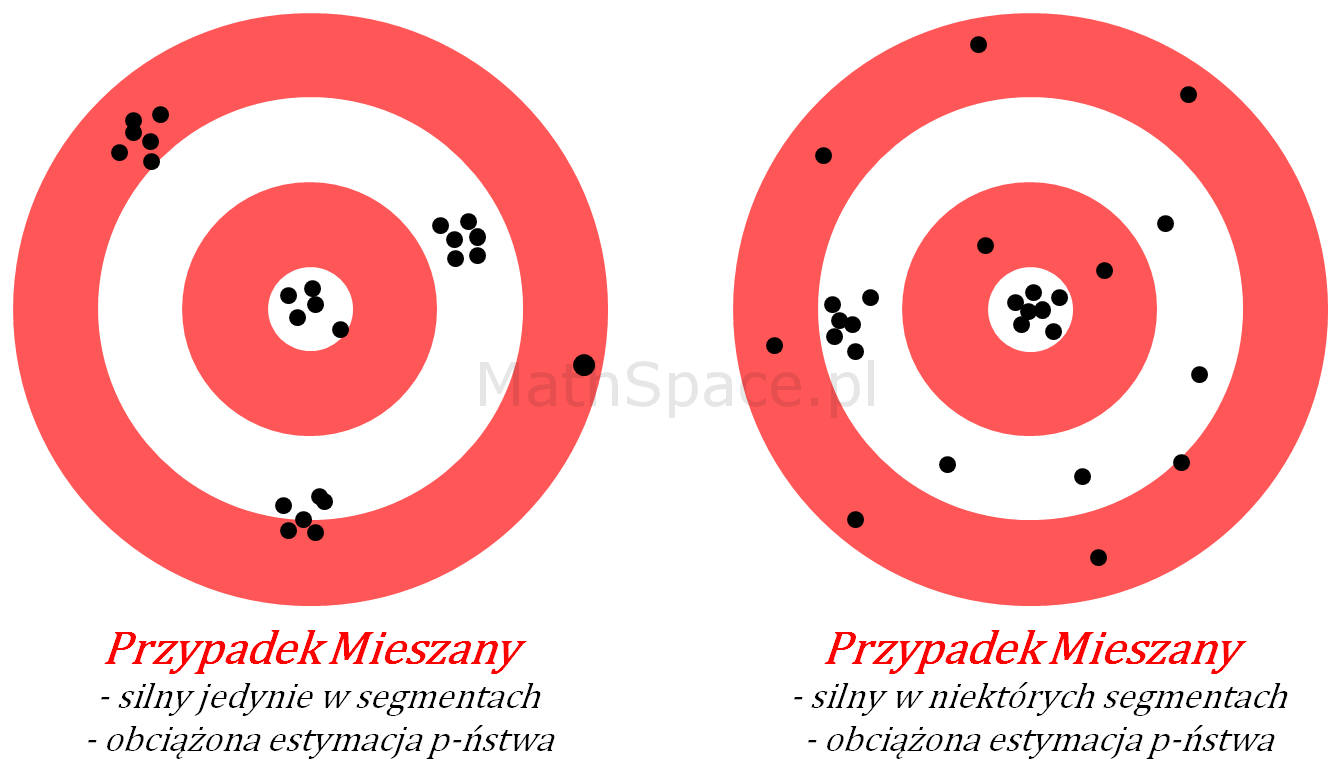
Model z siłą predykcyjną w ograniczeniu do podgrup – schemat
Przypadek 1: Silny model w ograniczeniu do podgrup
Sytuacja nieco bardziej złożona. Model, jako całość, nie jest zbyt dobry, natomiast w ograniczeniu do pewnych segmentów (np. klient „młody”, klient „zamożny”, etc…) separacja klas jest wysoka. Niestety, w tych segmentach, estymacja prawdopodobieństwa jest obarczona błędem systematycznym, co skutkuje niską siłą modelu dla całej populacji.
Akcja: Model wymaga dalszych prac, typowo niezbędne jest przygotowanie osobnych modeli dla wskazanych segmentów, następnie połączenie ich w całość.
Przypadek 2: Silny model wyłącznie dla wybranych segmentów
Podobnie jak wyżej, z tą różnicą, że istnieją podgrupy, w których model traci siłę separacji klas.
Akcja: Model wymaga dalszych prac, być może został popełniony błąd w kodzie i/lub w przetwarzaniu danych. Sprawdź cały eksperyment.
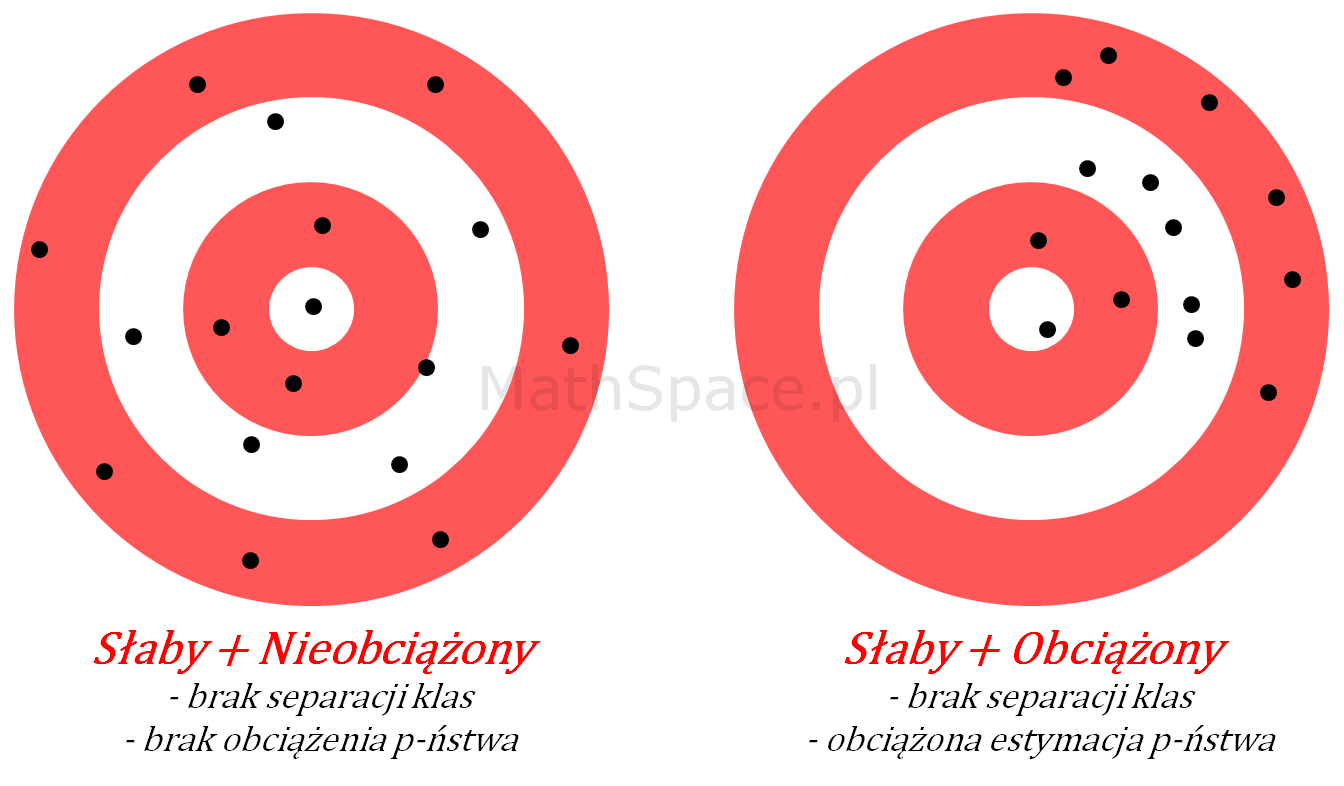
Słaby model – schemat
„Model strzela na oślep”, trafienia są nieprzewidywalne, nie ma skupienia. Interpretacja – brak separacji klas, indeks Giniego bardzo niski. Samo prawdopodobieństwo może być nieobciążone, tzn. średnia może zgadzać się z oczekiwanym a-priori.
Akcja: Zdecydowanie sytuacja negatywna, należy powtórzyć całość eksperymentu – prawdopodobnie błąd w kodzie, błąd w danych, błąd w założeniach, ewentualnie (choć mniej prawdopodobne) zmienne nie posiadają siły predykcyjnej.
Tarcza prawdopodobieństwa – praktyczna realizacja
Wizualizacja tarczy, aby ocena mogła być dokonana wiarygodnie, wymaga odpowiedniej liczby „strzałów”. Proponuję stosować wykres zawierający 100 punktów, każdy dla osobnego centyla score (przy założeniu, że mamy odpowiednio dużo danych wejściowych).
Kroki:
Dane testowe (osobno uczące) dzielimy na 100 grup, gdzie każda grupa to centyl względem rosnącej wartości szacowanego prawdopodobieństwa (score).
W każdej grupie wyznaczamy frakcję klasy pozytywnej.
W każdej grupie wyznaczamy średnie estymowane prawdopodobieństwo (średni score).
Wykres:
oś pozioma „X”: frakcja klasy pozytywnej
oś pionowa „Y” średni score.
$TR_i$ – target rate w grupie „i”
$P_i$ – estymowane prawdopodobieństwo w grupie „i”
Interpretacja:
Model idealny znajduje się na prostej y = x (tzn. brak błędu estymacji prawdopodobieństwa).
Model praktycznie dobry powinien dawać wyniki „w pobliżu” prostej y = x, przy czym „wahania pod / nad prostą” powinny charakteryzować się losowością, co świadczy o braku obciążenia.
Przestrzeń nad prostą y = x to obszar, gdzie model zawyża prawdopodobieństwo.
Przestrzeń pod prostą y = x to obszar, gdzie model zaniża prawdopodobieństwo.
Typowe proces oceny jakości estymacji prawdopodobieństwa
Ocena dla całej populacji: średni score vs a-priori / target rate całej populacji.
Ocena dla głównych segmentów: jeśli pracujemy na rzeczywistych obiektach (np. zbiór klientów) typowo dysponujemy szeregiem łatwych w interpretacji cech, które generują naturalne segmenty – będą to np.: wiek, płeć, miejsce zamieszkania (populacja), posiadane produkty, klient zamożny, klient indywidualny, i wiele innych. Często model szacuje prawidłowe prawdopodobieństwo dla całej populacji, niestety myląc się w podgrupach.
Ocena na bazie „tarczy prawdopodobieństwa”: tym razem zadajemy pytanie czy błąd estymacji zależy od wartości score? Idealna sytuacja jest tak, że nie zależy, tzn. że błąd pojawia się losowo. Score jest wypadkową szeregu zmiennych, więc pośrednio pokazujemy, że błąd zależy / nie zależy od każdej ze zmiennych osobno.
Przykłady
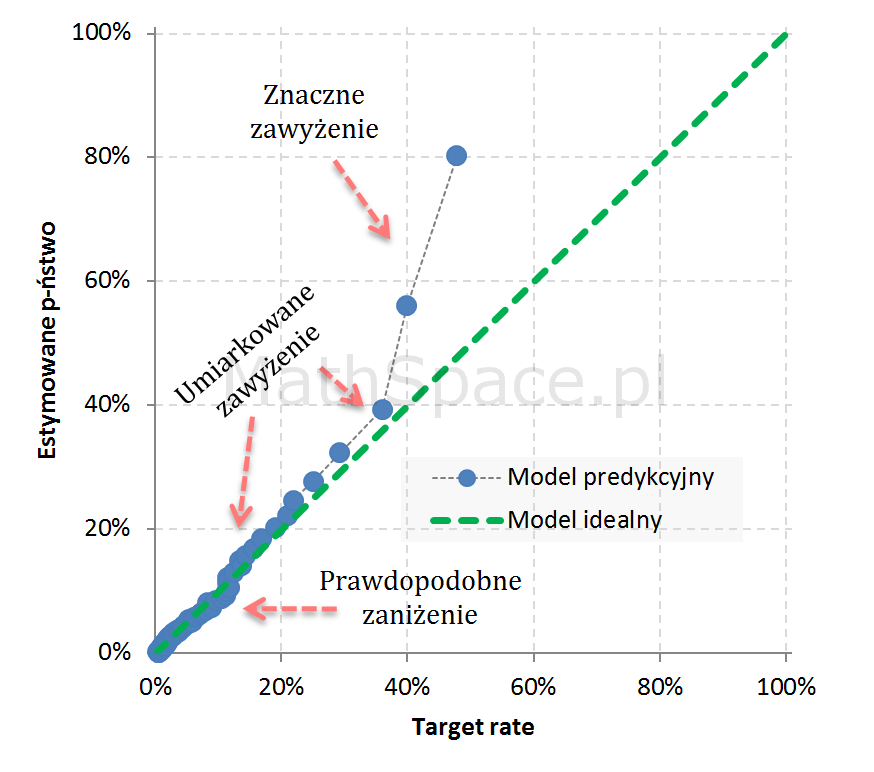
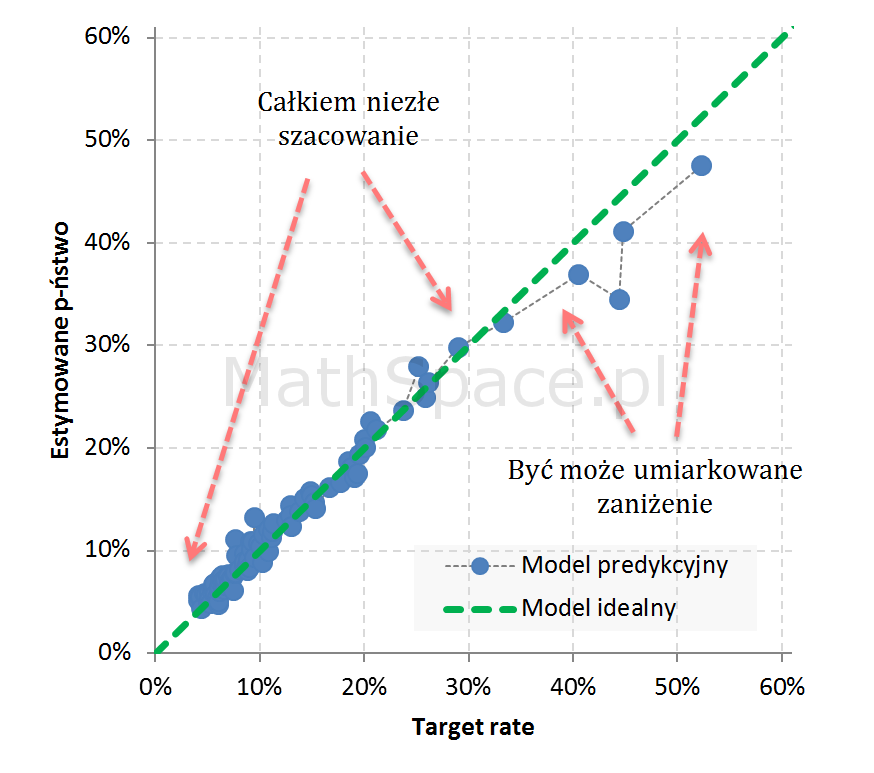
Przykład 1: Estymacja silnie zawyżona w segmentach wysokiego prawdopodobieństwa (wysokiej skłonności)
Przykład 2: Umiarkowane zawyżenie w segmentach niskiego prawdopodobieństwa
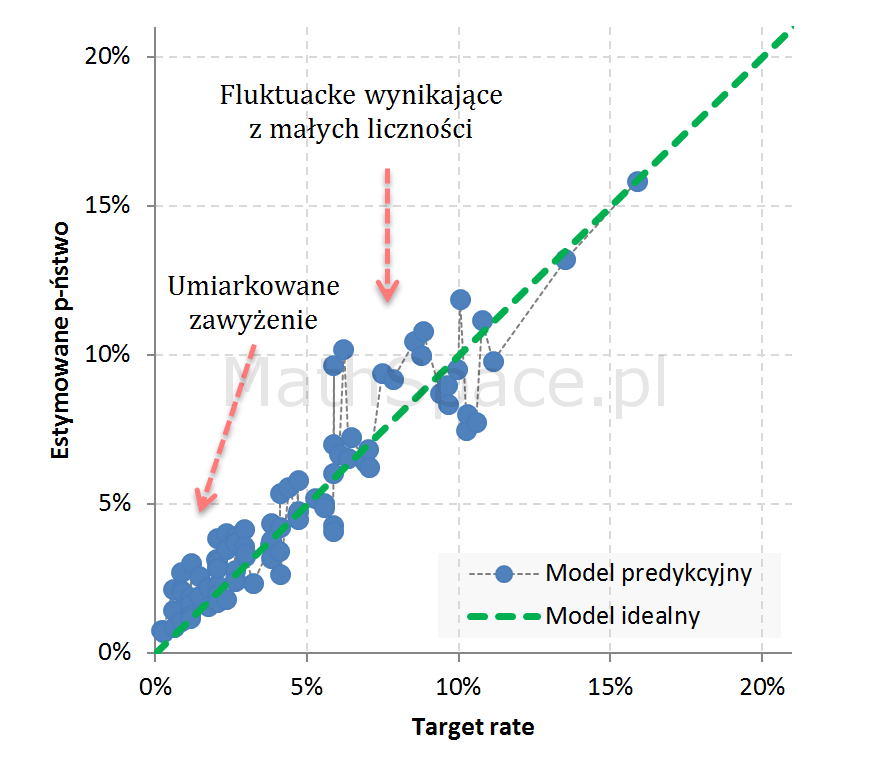
Przykład 3: Widoczne 3 segmenty z obciążeniem: 1. dość istotne zawyżenie, 2. umiarkowane zawyżenie, 3. umiarkowane zaniżenie
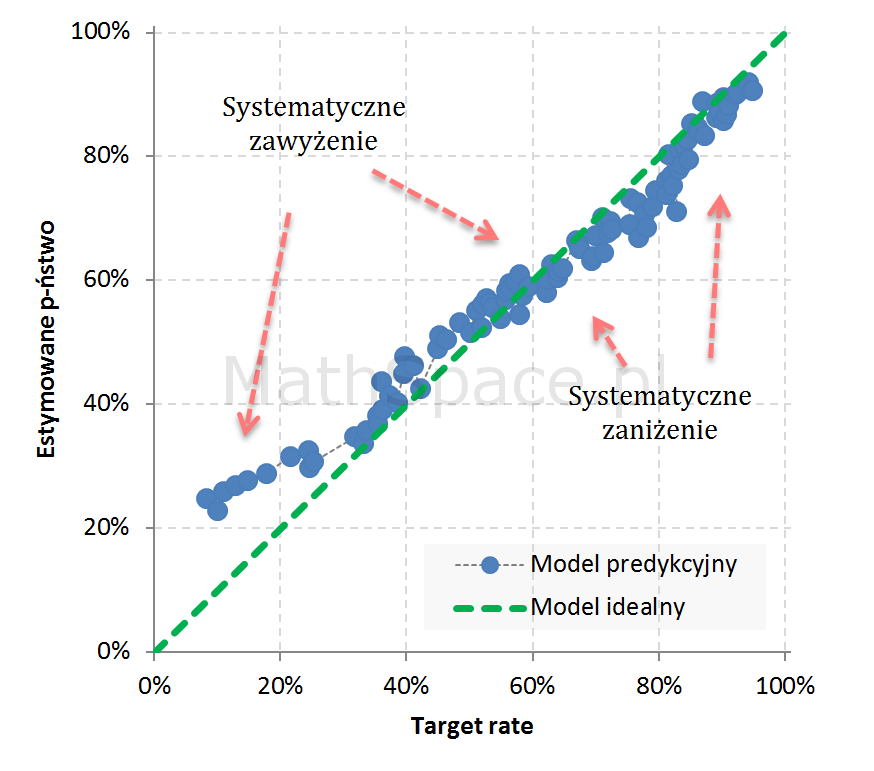
Przykład 4: Całkiem niezły model
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
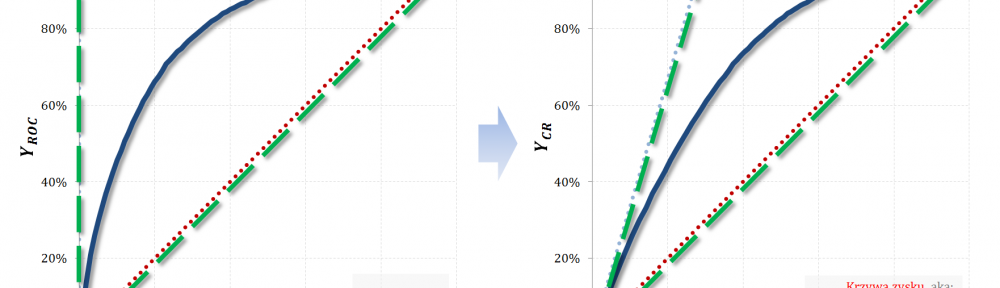
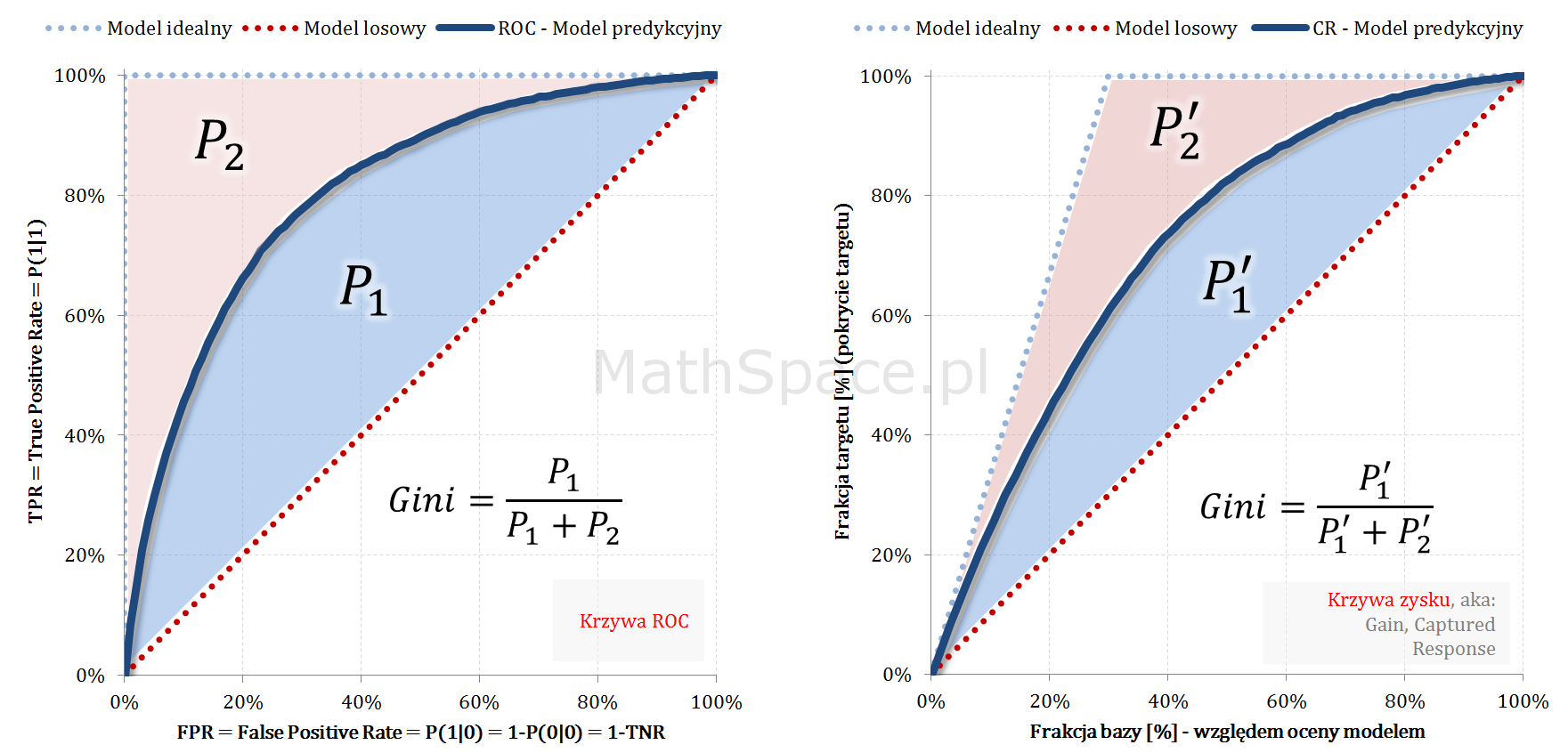
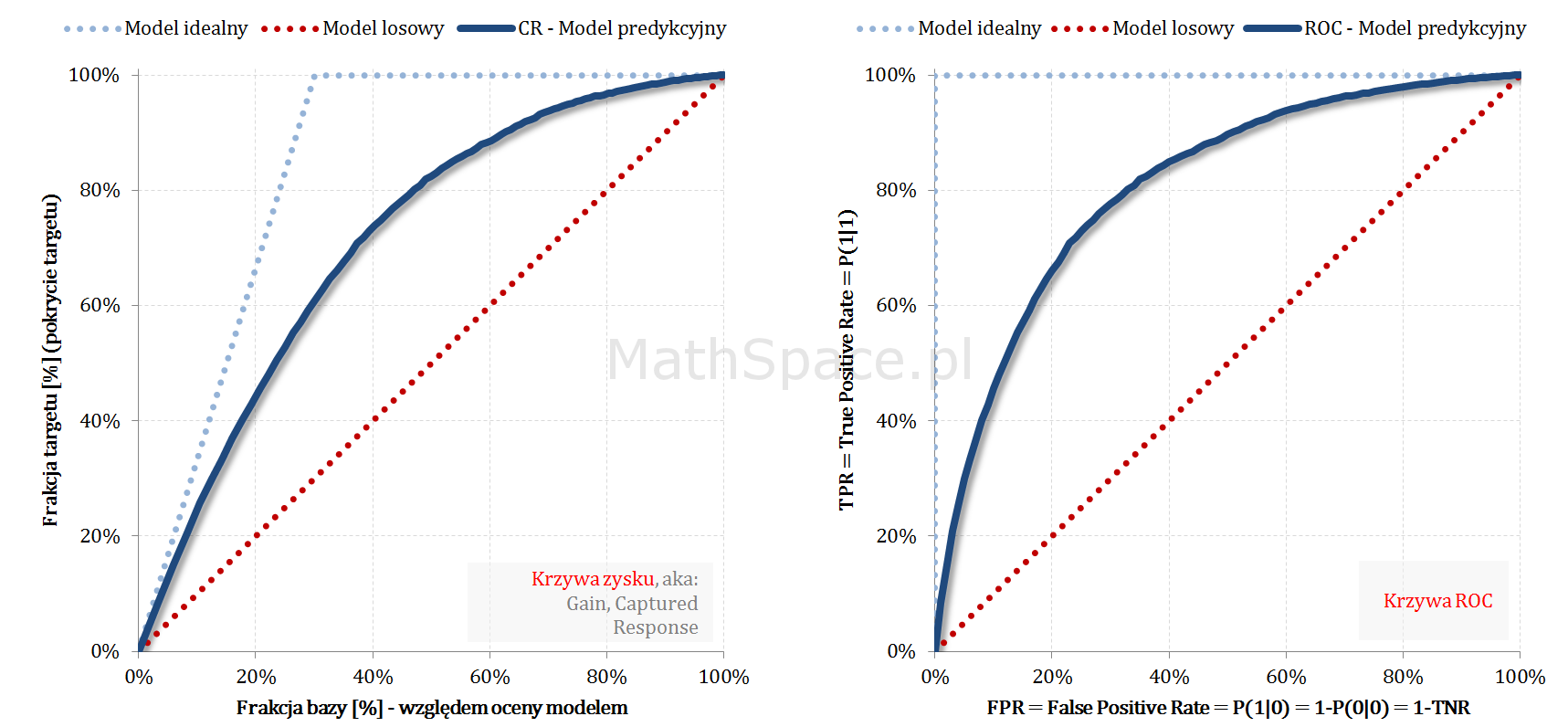
W części #6 oraz części #7 cyklu „Ocena jakości klasyfikacji” przedstawiłem krzywą zysku (aka: Gain, Captured Response) oraz krzywą ROC. Dzisiaj skupię się na mało znanej, acz bardzo prostej i przydatnej, relacji pomiędzy tymi krzywymi – okazuje się bowiem, że wykresy są „niemal identyczne” 🙂
Odpowiednio spoglądając na umieszczone obok siebie wykresy ciężko odeprzeć wrażenie, że krzywe są bardzo podobne. Intuicja podpowiada, że mamy tu do czynienia z tymi samymi funkcjami, jedynie naszkicowanymi w nieco różnych układach współrzędnych.
W obu przypadkach to „przestrzeń” pomiędzy modelem losowym i modelem idealnym definiuje odpowiedni układ współrzędnych, a różnica obecna w Captured Response powiązana jest z a-priori (CR jest zależna od a-priori, ROC nie zależy od a-priori). Idąc za kolejnym przeczuciem powiemy, że najprawdopodobniej dla tej samej wartości „Y” różnić się będą wartości „X” (ze względu na „ściśniecie” obecne w Captured Response).
Wzór na bazie macierzy przekształcenia liniowego – jedynie poglądowo
Uwaga: poniższe wyprowadzenie jest jedynie pomocnicze, nie stanowi wystarczającej argumentacji uzasadniającej „identyczność” krzywych Captured Response i ROC!!! Formalna argumentacja znajduje się w kolejnej sekcji.
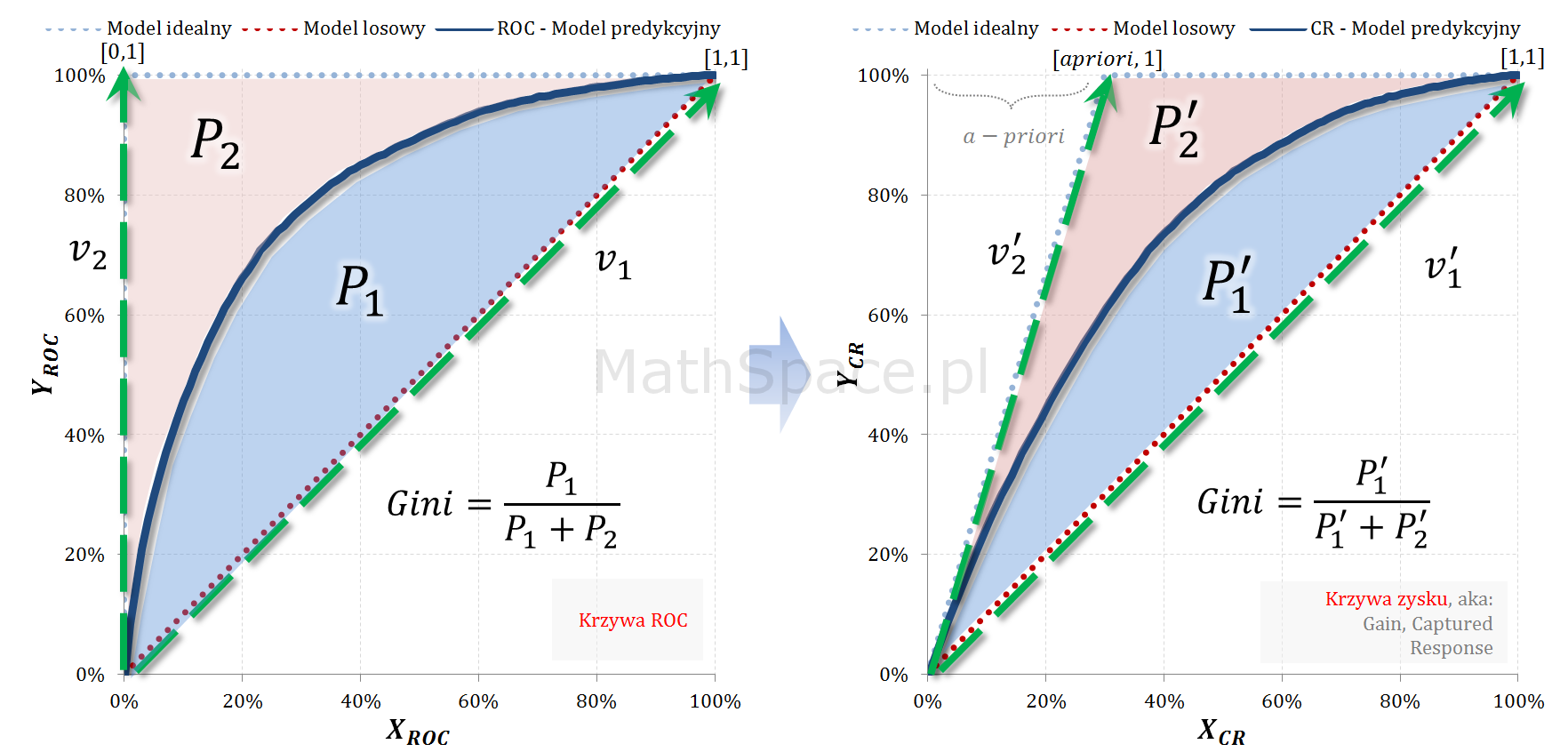
Zauważmy, że wektor
$\begin{bmatrix}X_{ROC}=0\\Y_{ROC}=1\end{bmatrix}$ przechodzi w $\begin{bmatrix}X_{CR}=apriori\\Y_{CR}=1\end{bmatrix}$
oraz wektor
$\begin{bmatrix}X_{ROC}=1\\Y_{ROC}=1\end{bmatrix}$ przechodzi w $\begin{bmatrix}X_{CR}=1\\Y_{CR}=1\end{bmatrix}$
Zatem macierz przekształcenia liniowego przyjmuje postać (potrzeba rozwiązać prościutki układ równań):
Wynik bardzo ciekawy – faktycznie wystarczy a-priori 🙂 Jednak to nie jest dowód, wyprowadzenie bazowało na intuicji …
Wzór na bazie proporcji – jedynie poglądowo
Uwaga: Ponownie – poniższe wyprowadzenie jest jedynie pomocnicze, nie stanowi wystarczającej argumentacji uzasadniającej „identyczność” krzywych Captured Response i ROC!!! Formalna argumentacja znajduje się w kolejnej sekcji.
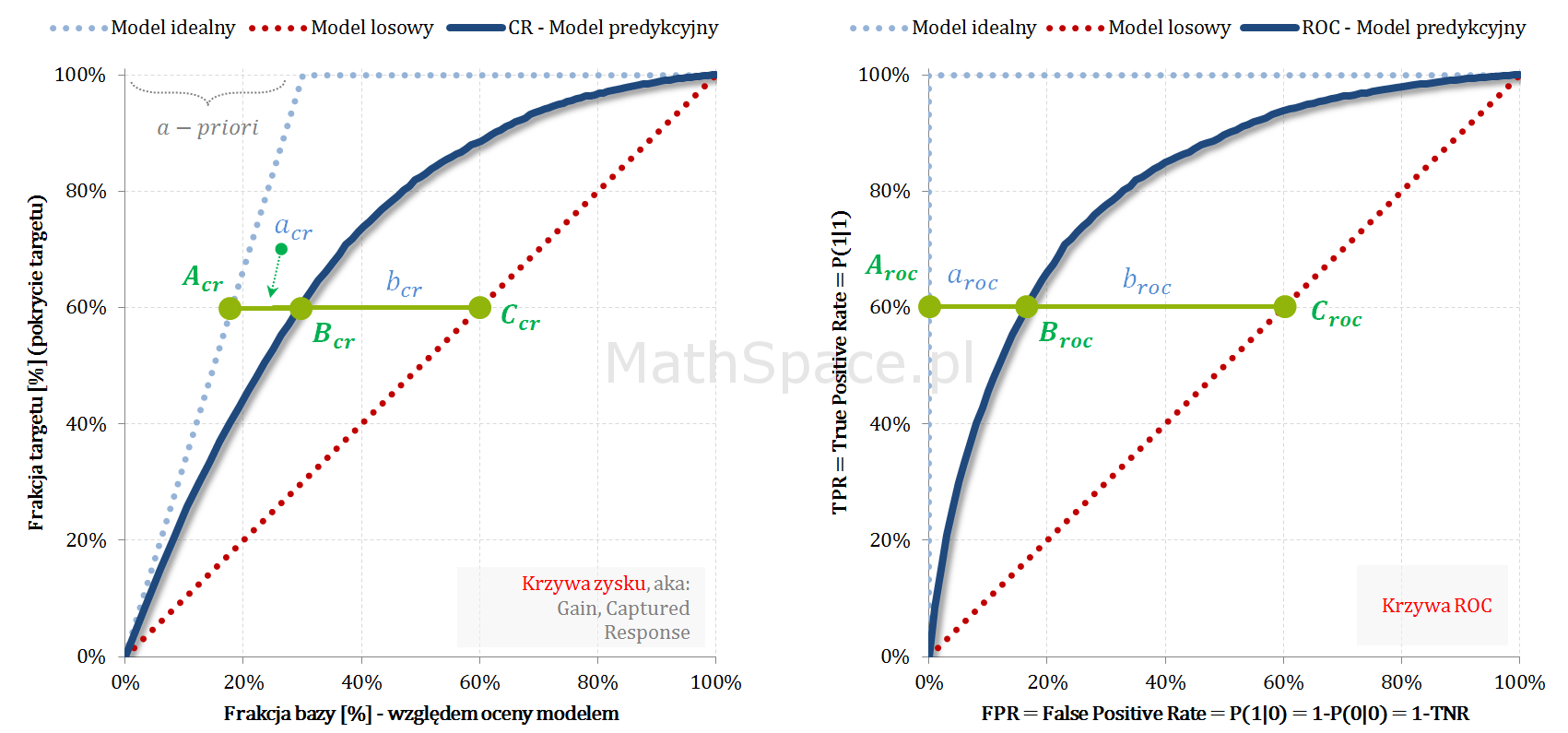
Oznaczmy punkty (wykres powyżej):
$B_{cr}=\Big(X_{cr}, Y_{cr}\Big)$ – punkt na krzywej Captured Response
$B_{roc}=\Big(X_{roc}, Y_{roc}\Big)$ – punkt na krzywej ROC
Podążając za „głosem wewnętrznym” 🙂 napiszemy równość
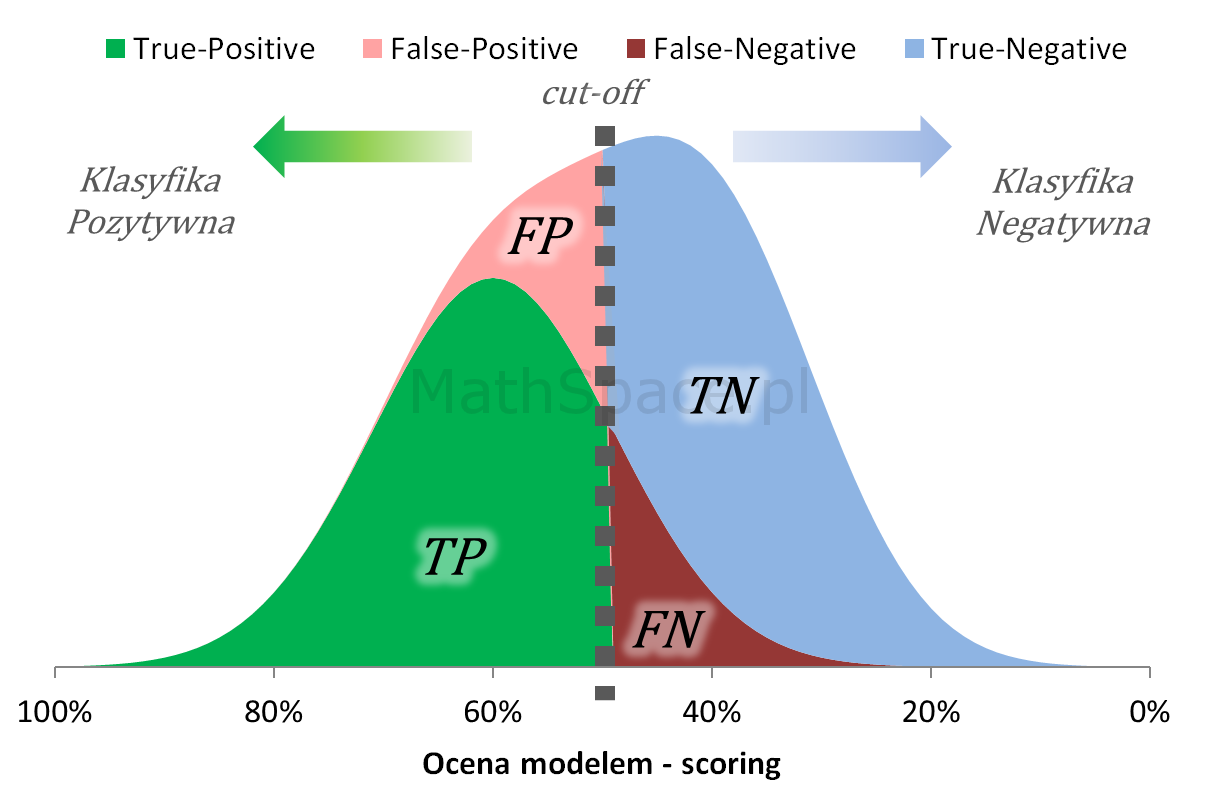
Współrzędna „X” krzywej Captured Response to kwantyl bazy, tzn. gdyby założyć, że X% bazy klasyfikujemy pozytywnie, to dotrzemy do Y% frakcji targetu – zatem $X_{cr}$ jest rozmiarem frakcji przewidywania pozytywnego. Rozważmy poniższy rozkład oceny modelem.
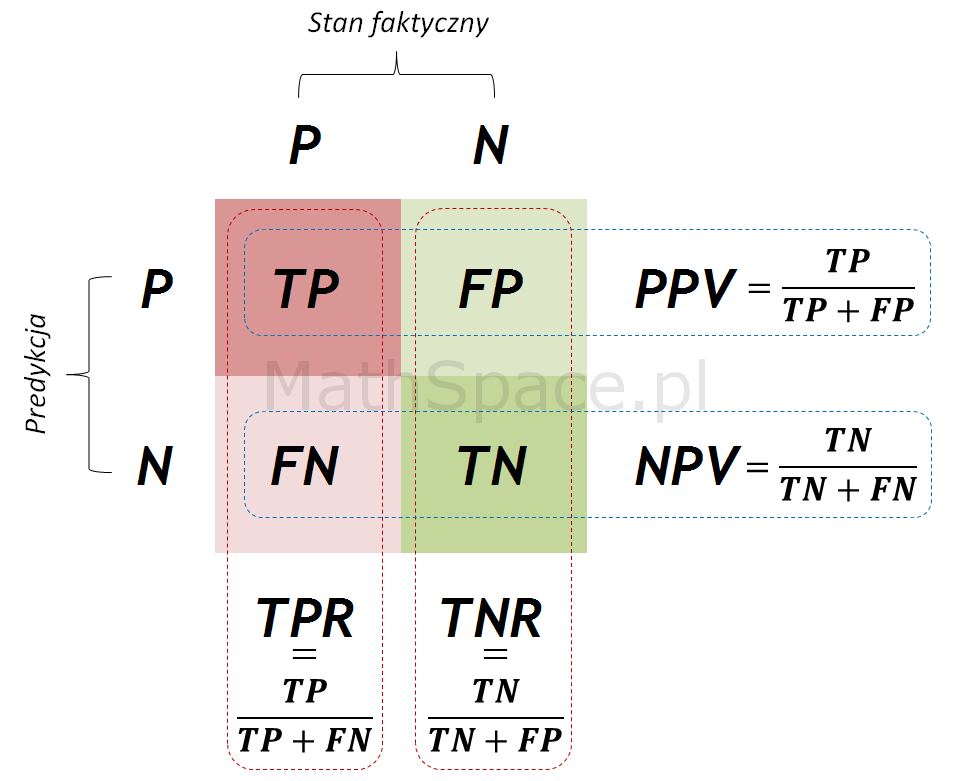
Przewidywanie pozytywne składa się z frakcji TP+FP, ale
Rozumiejąc relację pomiędzy krzywą ROC a krzywą Captured Response analiza modelu jest znacznie prostsza, szczególnie jeśli korzystamy z narzędzia, które prezentuje tylko jeden wariant krzywej (często ROC). Przy małych apriori oś „X” krzywej ROC można praktycznie uznać za oś „X” krzywej Captured Response.Przy większych apriori należy intuicyjnie przesuwać „X” w prawo aby z ROC uzyskać Captured Response.
Gini policzone na ROC oraz na CR (pamiętając o przestrzeni pomiędzy modelem losowym i modelem idealnym) bedą sobie równe.
Przykład działania wzoru
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Receiver Operating Characteristic – Krzywa ROC – geneza nazwy
Termin „Krzywa ROC” wywodzi się z teorii detekcji sygnałów, której zadaniem jest odróżnienie sygnału będącego informacją (np. sygnały z maszyn / urządzeń elektronicznych, bodźce pochodzące z organizmów żywych) od wzorców przypadkowych nie zawierających informacji (szum, tło, aktywność losowa). Pierwsze wykorzystanie krzywej ROC datuję się na okres II Wojny Światowej. Po ataku na Pearl Harbor w 1941, USA zaczęły poszukiwać lepszej metody analizy sygnałów radarowych w celu zwiększenia wykrywalności Japońskich samolotów.
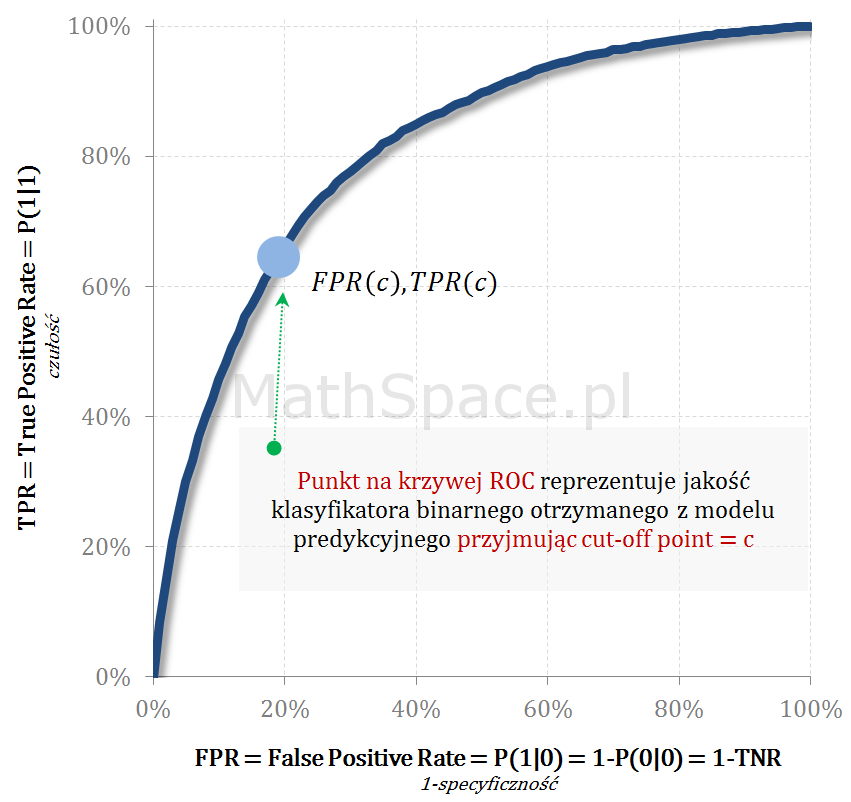
W statystyce matematycznej krzywa ROC jest graficzną reprezentacją efektywności modelu predykcyjnegopoprzez wykreślenie charakterystyki jakościowej klasyfikatorów binarnych powstałych z modelu przy zastosowaniu wielu różnych punktów odcięcia. Mówiąc inaczej – każdy punkt krzywej ROC odpowiada innej macierzy błędu (zobacz tutaj) uzyskanej przez modyfikowanie „cut-off point” (zobacz tu). Im więcej różnych punktów odcięcia zbadamy, tym więcej uzyskamy punktów na krzywej ROC. Finalnie na wykres nanosimy TPR (True-Positive Rate – oś pionowa) oraz FPR (False-Positive Rate – oś pozioma).
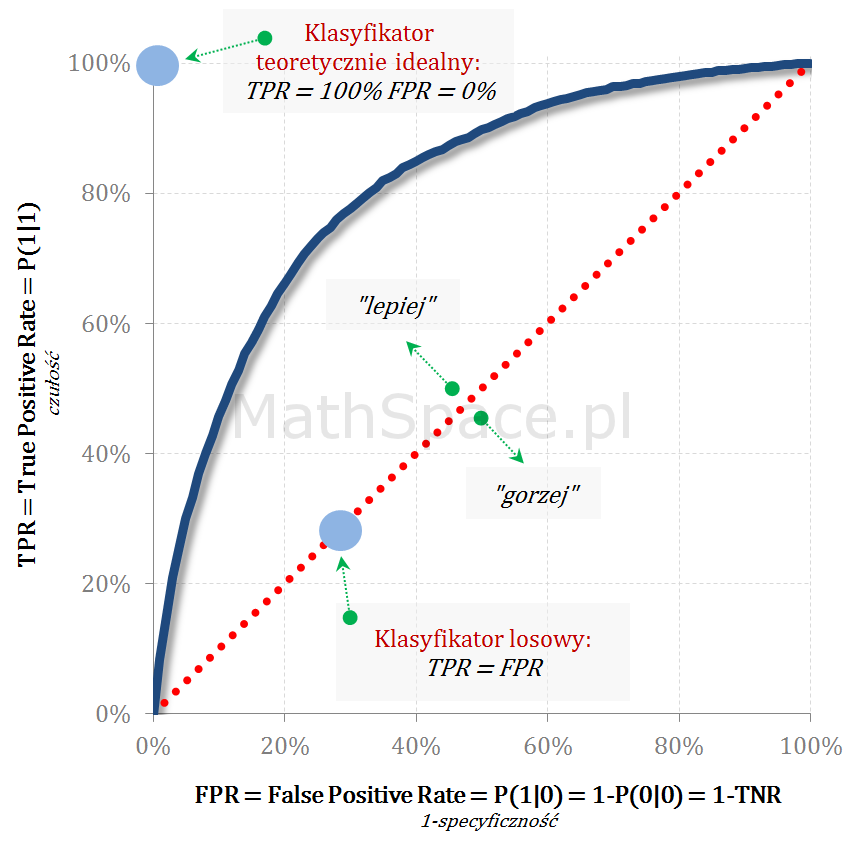
Krzywa ROC, będąc funkcją punktu odcięcia, przedstawia zmienność TPR (miary pokrycia / wychwycenia klasy faktycznie pozytywnej) w zależności od FPR (poziomu błędu popełnianego na klasie faktycznie negatywnej). Jak zawsze chodzi o pewien kompromis, tzn. dobierając „cut-off” chcemy maksymalizować TPR „trzymając w ryzach” błąd FPR. Analiza relacji TPR(FPR) jest niezwykle przydatna, ale najpierw przypomnijmy kilka podstawowych definicji.
Klasyfikator teoretycznie idealny reprezentowany jest przez punkt (0,1), natomiast klasyfikatory powstałe z modelu losowego „leżą” na prostej TPR=FPR.
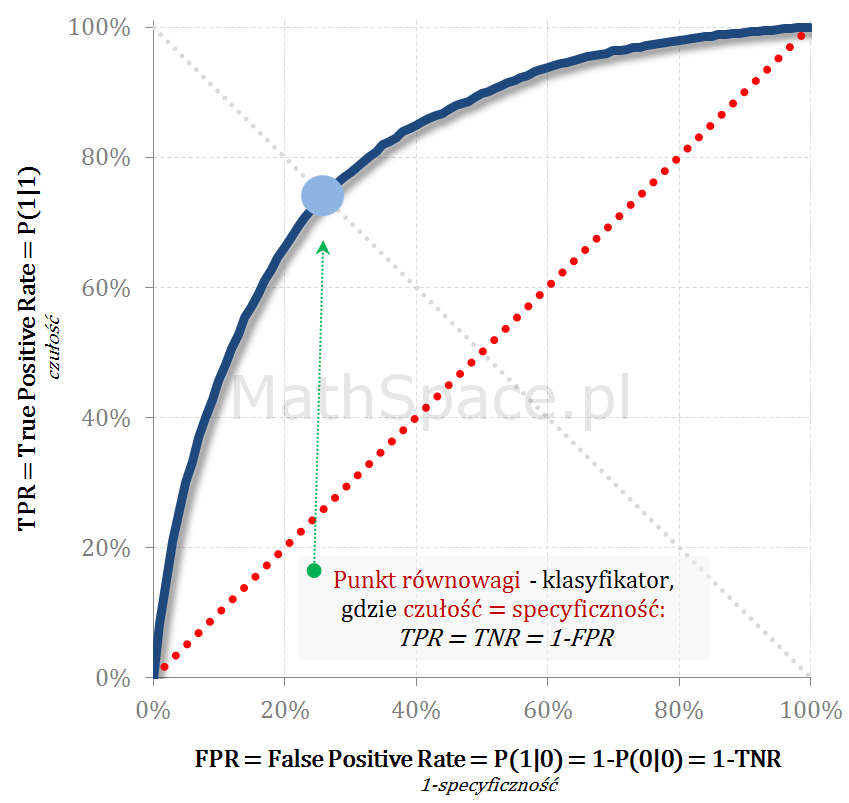
ROC – Punkt równowagi (czułość = specyficzność)
Punkt równowagi leży na przecięciu ROC z prostą TPR = 1-FPR = TNR i reprezentuje „cut-off” point, dla którego klasyfikator osiąga równowagę czułość = specyficzność.
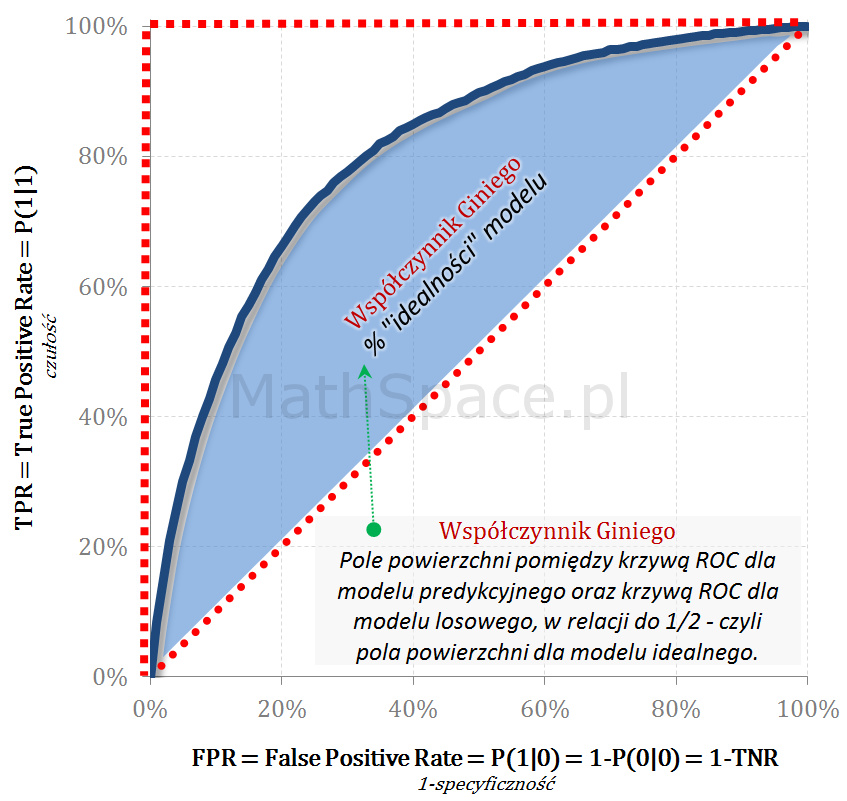
ROC – Współczynnik Giniego
Współczynnik Giniego to pole powierzani pomiędzy krzywą ROC dla badanego modelu oraz krzywą ROC dla modelu losowego w interpretacji procentowej do wartości 1/2 – czyli pola powierzchni dla klasyfikatora teoretycznie idealnego. Współczynnik Giniego jest doskonałą miarą jakości modelu i może być interpretowany jako % „idealności” danego modelu predykcyjnego.
Im większy wskaźnik Giniego tym lepiej
Wartość wskaźnika Giniego nie zależy od apriori (teoretycznie), w praktyce trudniej o silny model jeśli apriori jest duże
Gini = 100% dla modelu teoretycznie idealnego
Gini = 0% dla modelu losowego
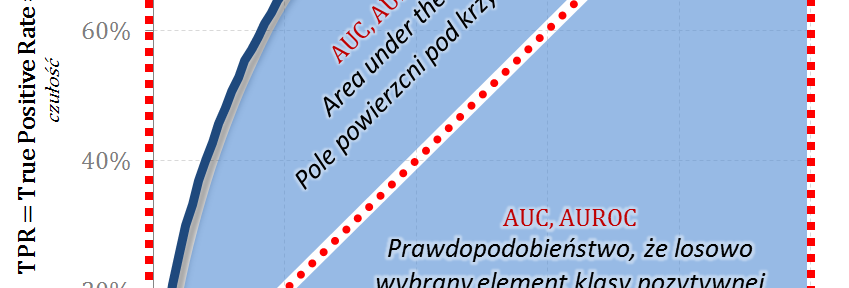
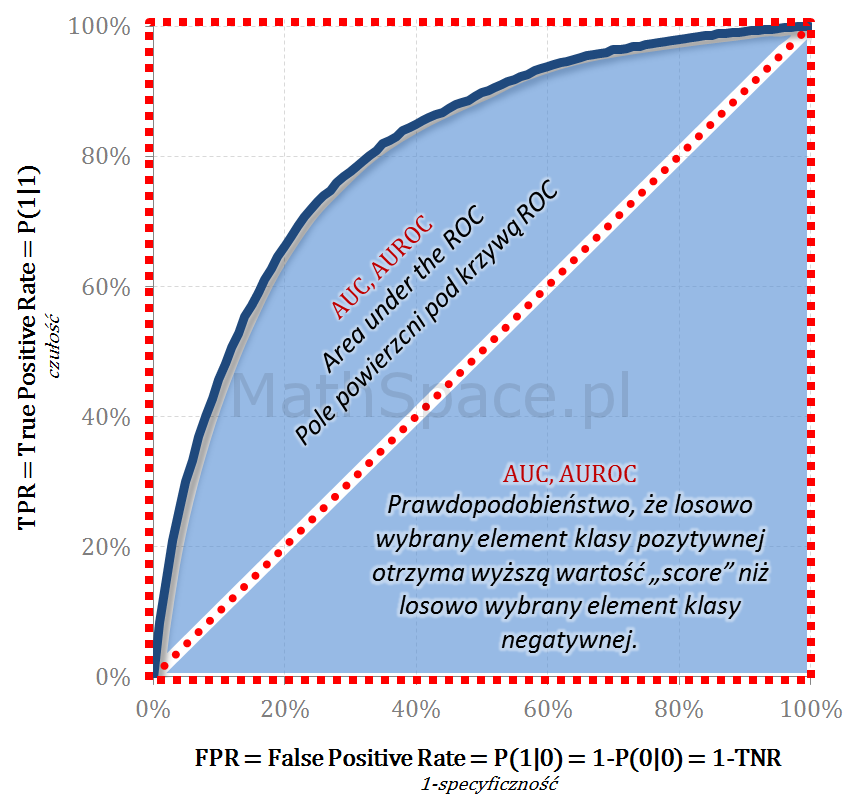
Pole powierzani pod krzywą ROC – AUC, AUROC
Tym razem wyznaczamy całość pola powierzchni pod wykresem ROC odnosząc wartość do analogicznego pola dla modelu idealnego – w tym przypadku pola kwadratu o boku 1. Interpretacja AUROC (Area Under the ROC) to prawdopodobieństwo, że badany model predykcyjny oceni wyżej (wartość score) losowy element klasy pozytywnej od losowego elementu klasy negatywnej.
Im większy wskaźnik AUROC tym lepiej
Wartość AUROC nie zależy od apriori (teoretycznie), w praktyce trudniej o silny model jeśli apriori jest duże
AUROC = 100% dla modelu teoretycznie idealnego
AUROC = 50% dla modelu losowego
AUROC = 0% dla modelu idealnego klasy przeciwnej do pozytywnej
Ciąg dalszy nastąpi …
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
W części 4 cyklu „ocena jakości klasyfikacji” opisałem podstawowe statystyki w wariancie nieskumulowanym służące inspekcji modelu predykcyjnego. Nieskumulowane prawdopodobieństwo i nieskumulowany lift, choć bardzo przydatne na etapie budowy modelu (praca analityka), sprawdzają się nieco gorzej w kontaktach analityk – odbiorca biznesowy. Odbiorcę biznesowego zazwyczaj interesują informacje takie jak „do jakiej części zainteresowanych produktem dotrę?” lub „o ile skuteczniejsze jest targetowanie na bazie modelu?” (tu uwaga dla bardziej zaawansowanego czytelnika – celowo pomijam kwestie wpływu inkrementalnego – tzw. uplift będzie tematem przyszłych wpisów).
Założenia – przypomnienie
Podobnie do poprzednich część cyklu załóżmy, że rozważamy przypadek klasyfikacjibinarnej (dwie klasy: „Pozytywna – 1” nazywana targetem oraz „Negatywna – 0”). Załóżmy ponadto, że dysponujemy modelem predykcyjnym $p$ zwracającym prawdopodobieństwo $p(1|x)$ przynależności obserwacji $x$ do klasy „Pozytywnej – 1” (inaczej „P od 1 pod warunkiem, że x”). I jeszcze ostatnie założenie, wyłącznie dla uproszczenia wizualizacji – dotyczy rozmiaru klasy pozytywnej – tym razem ustalmy, że jest to 5%, inaczej, że prawdopodobieństwo a-prioriP(1)=0.05.
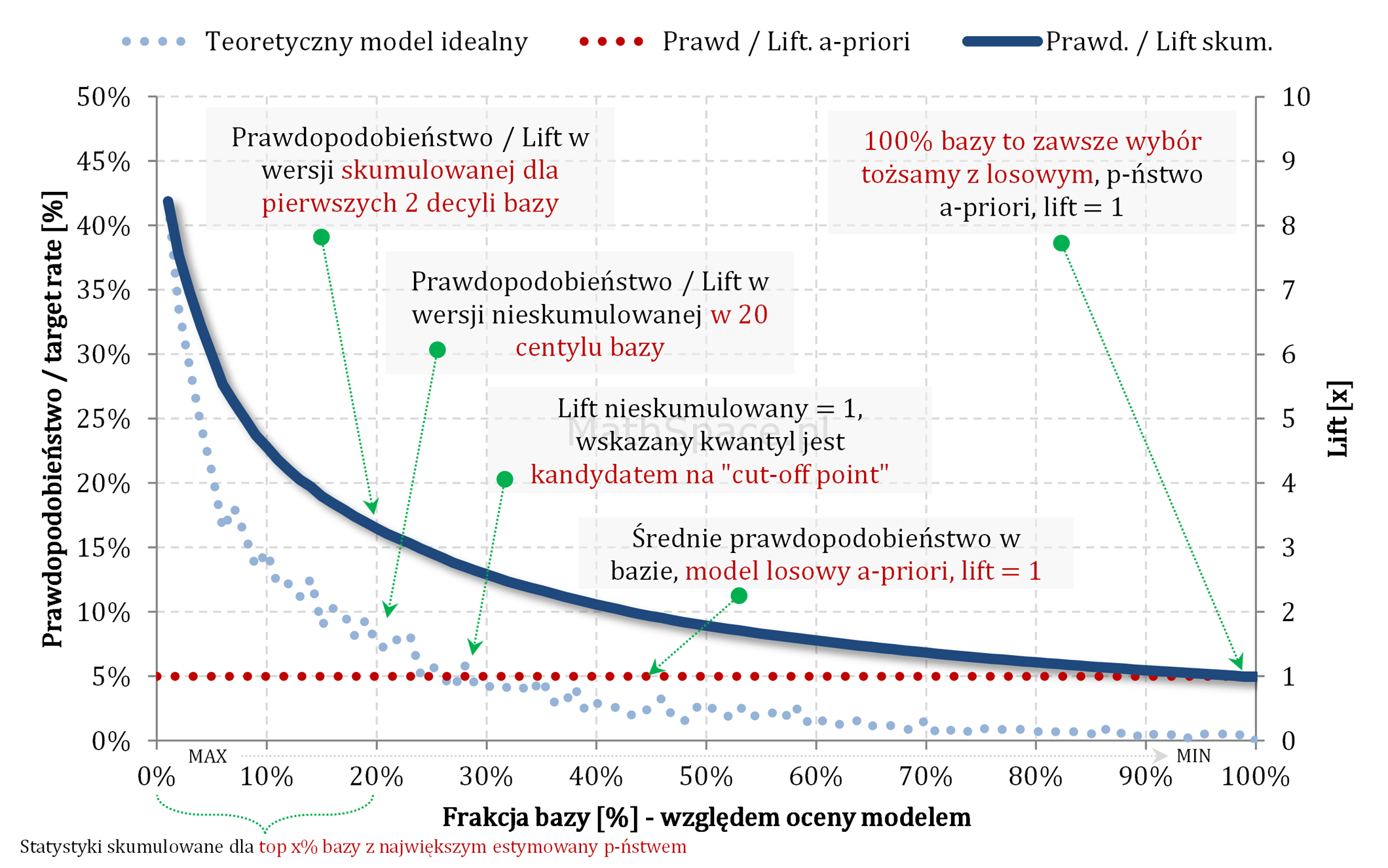
Skumulowane prawdopodobieństwo i skumulowany lift – czyli o ile skuteczniejsze jest targetowanie na bazie modelu?
Pojęcie liftu dobrze jest utożsamiać z krotnością rozumianą jako „o ile razy częściej zaobserwuję target w grupie wybranej modelem w stosunku do wyboru losowego”. Interpretacja „krotnościowa” ma zastosowaniu zarówno do liftu skumulowanego i nieskumulowanego. Lift nieskumulowany powstaje na bazie obserwacji targetu w określonym przedziale estymowanego prawdopodobieństwa (np. pojedynczy centyl, pojedynczy decyl), natomiast lift skumulowany odnosi się do targetu analizowanego we wszystkich przedziałach estymowanego prawdopodobieństwa, które leżą „na lewo” od ustalonego puntu (czyli np. 20 pierwszych centyli, 2 pierwsze decyle).
Ideę liftu najlepiej obrazuje wykres prawdopodobieństwa i liftu:
Oś pozioma – frakcja bazy względem oceny modelem – czyli baza posortowana względem estymowanego prawdopodobieństwa (czasami mówimy również względem score) w porządku od wartości największej do najmniejszej.
Prawa oś pionowa – lift – normalizacja do średniego target rate (dzielenie przez a-priori).
I tak – dla powyższego przykładu – mamy lift ponad 3 przy decyzji, że „cut-off point” umieszczamy dokładnie w 20 centylu. Ale zaraz – przecież na 10 centylu mamy lift ponad 4 – czyli lepiej? …
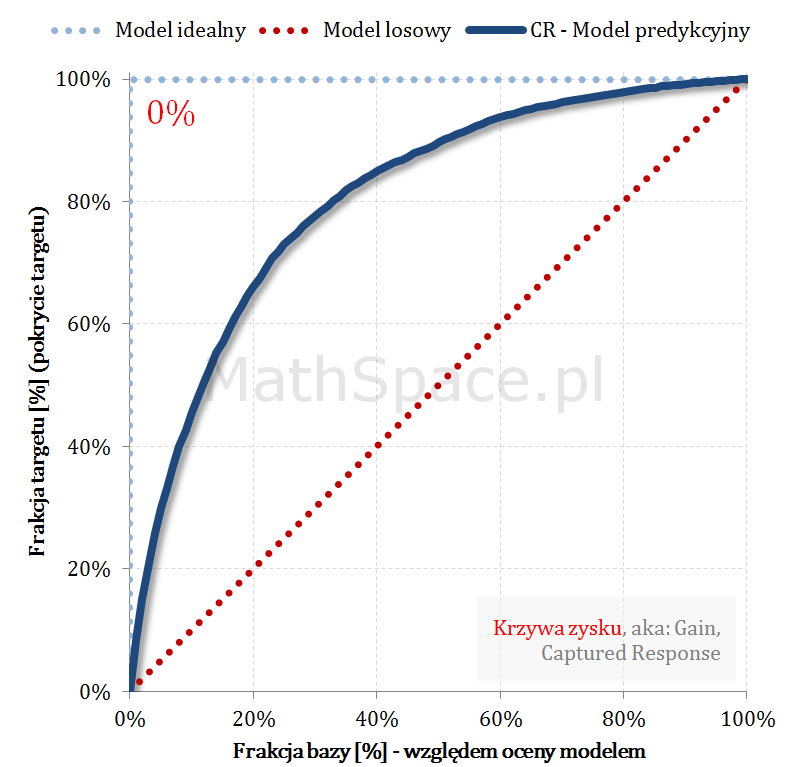
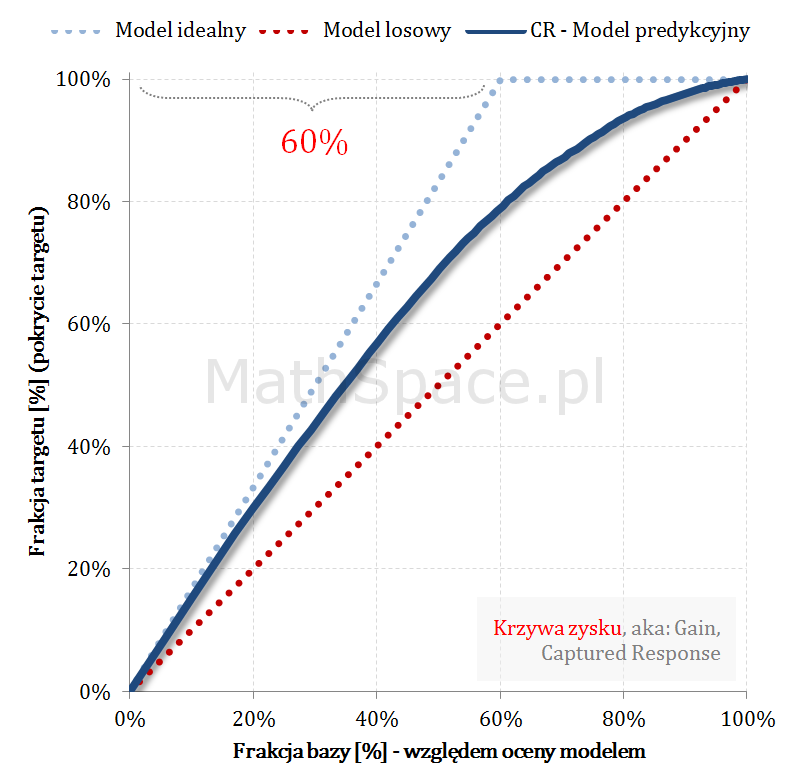
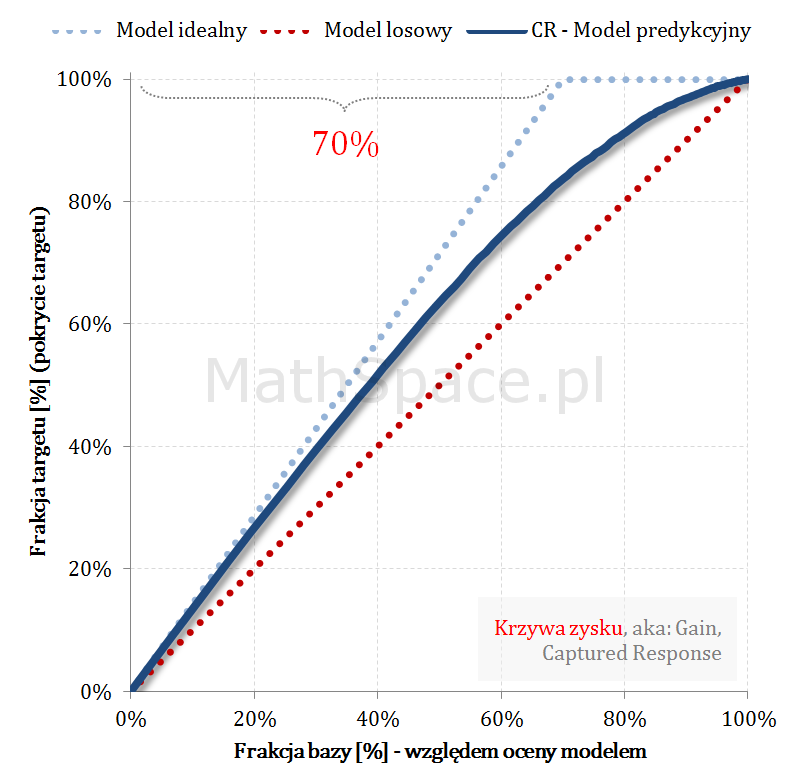
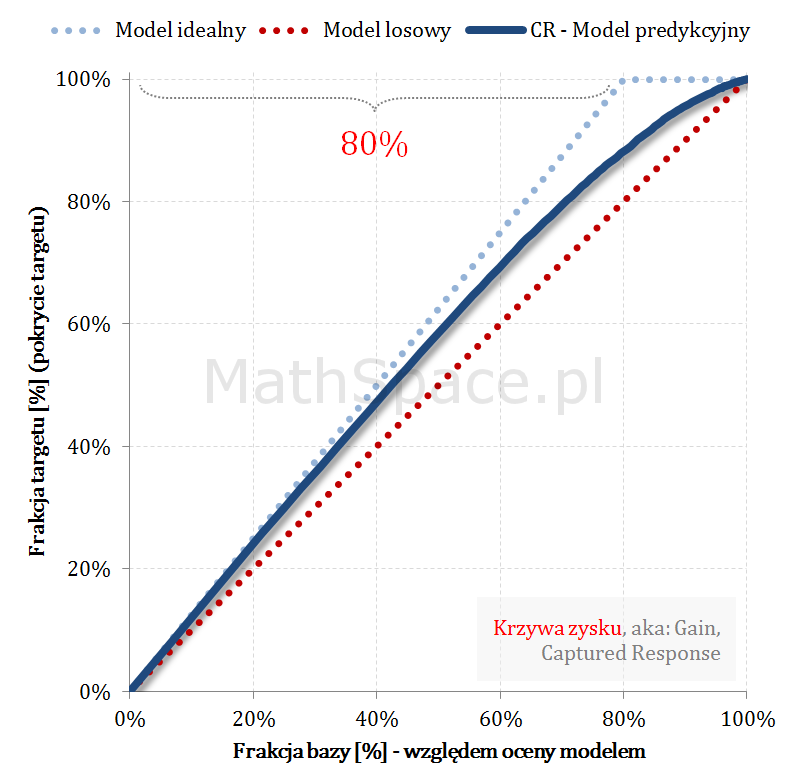
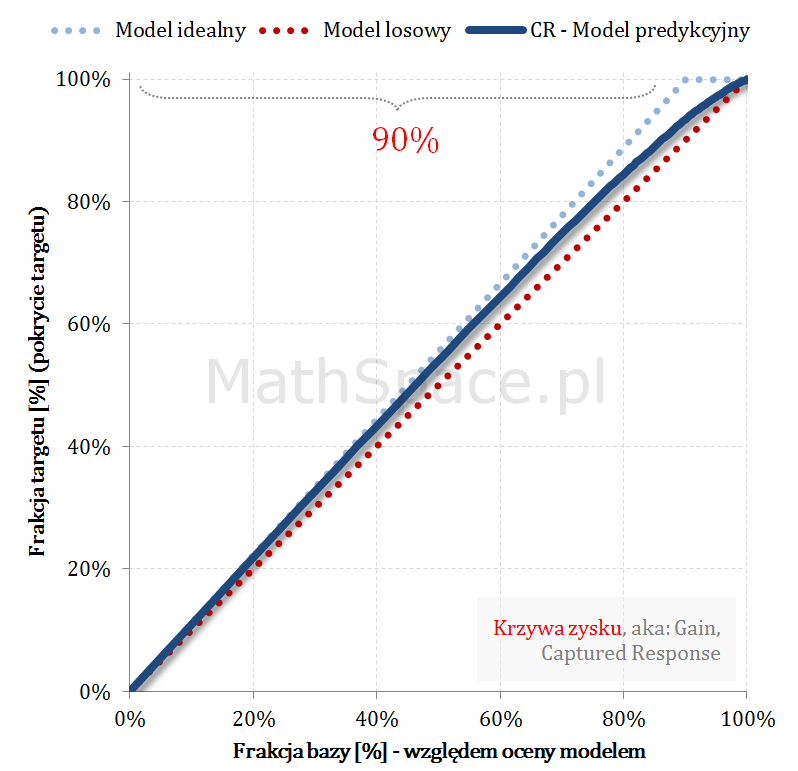
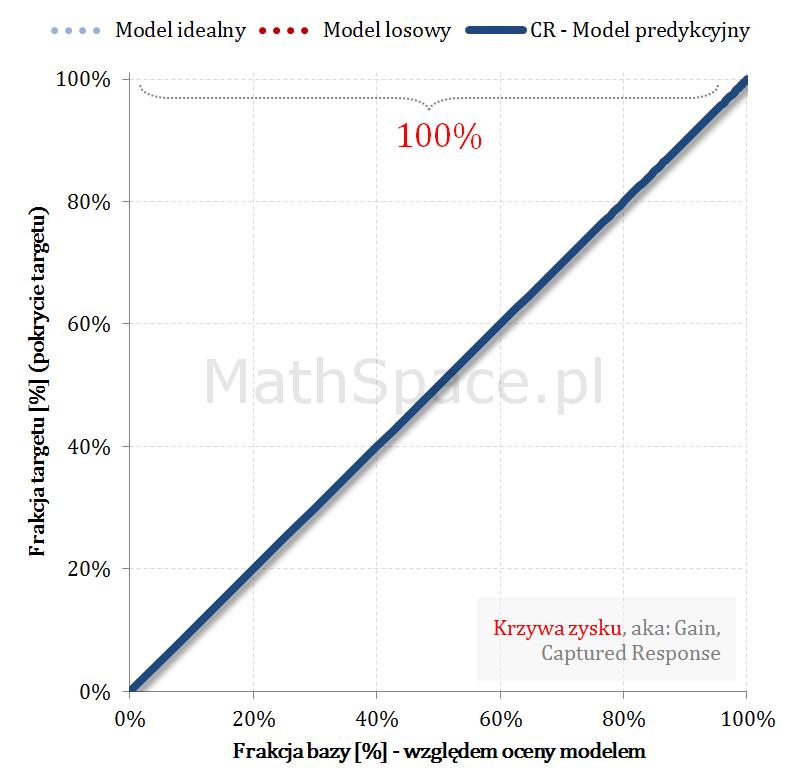
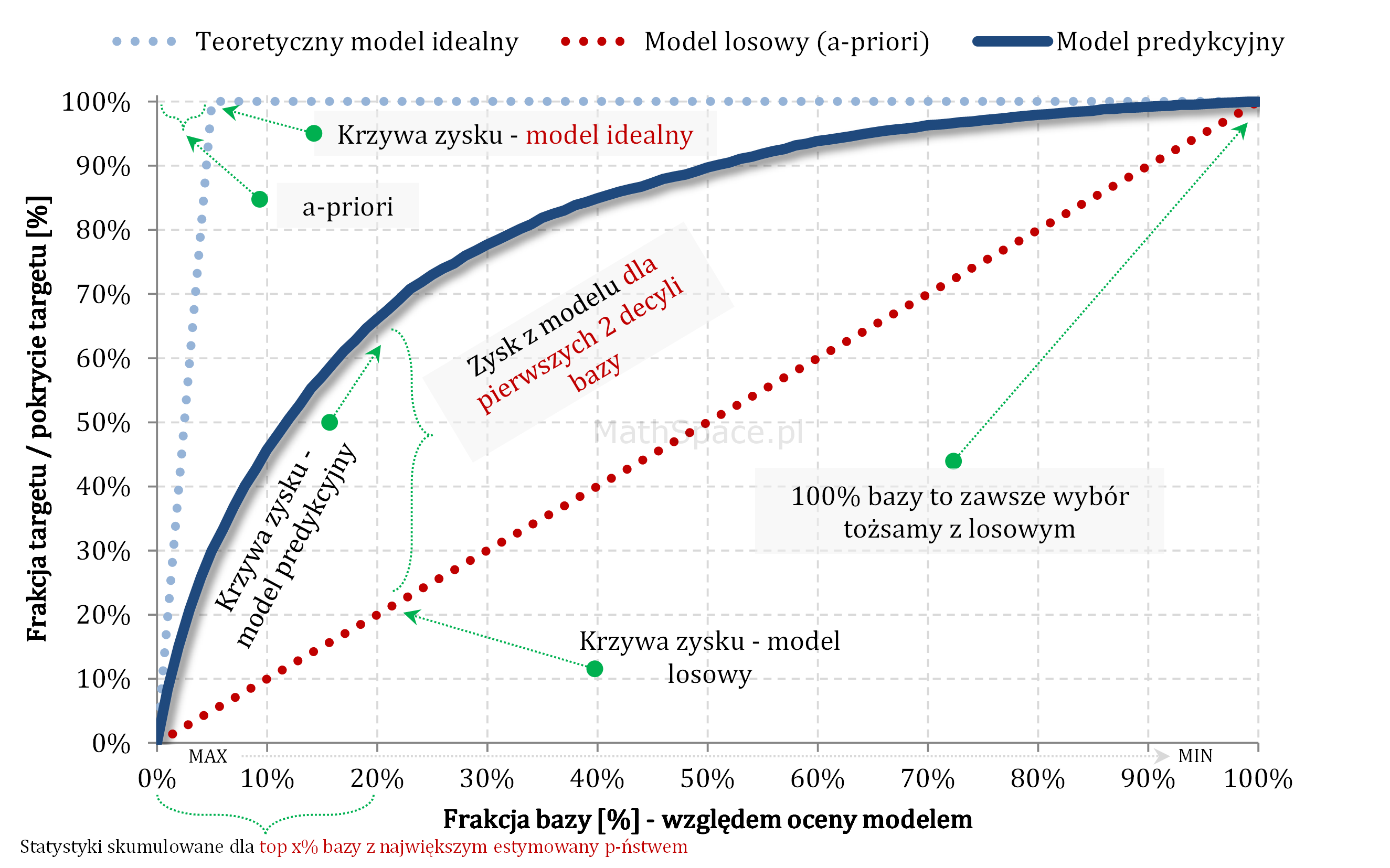
Krzywa zysku aka Gain Curve lub Captured Response – czyli do jakiej części zainteresowanych produktem dotrę?
… Rozwiązaniem powyższego dylematu jest analiza krzywej zysku. Krzywa zysku łączy w sobie ideę liftu wraz z „zasięgiem„ grupy. Przykładowo: z bazy 100 tys. klientów, w której 5 tys. zainteresowanych jest produktem, do kampanii wybrano 10 tys. Po realizacji komunikacji okazało się, że spośród 10 tys. zakupu dokonało 3 tys. klientów. I dochodzimy łatwo do definicji zasięgu jako pokrycia 3 tys. z 5 tys, czyli dotarcie do targetu na poziomie 3/5 = 60%.
Ideę zasięgu bardzo dobrze obrazuje wykres krzywej zysku:
Oś pozioma – tak jak dla liftu – frakcja bazy względem oceny modelem.
Oś pionowa – zasięg
Analizując powyższy przykład – zasięg na 10% to około 45%, na 20% to już około 65% – czyli „chyba warto się pochylić” 🙂 … cdn …
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
W części 4 cyklu „Ocena jakości klasyfikacji” przedstawiłem podstawowe statystyki prawdopodobieństwaoraz liftu(w wersji nieskumulowanej) służące do inspekcji modelu predykcyjnego w zakresie siły separacji klas. W części 3 skupiłem się na koncepcji punktu odcięcia (cut-off point), który model predykcyjny (z ciągłą zmienną odpowiedzi) transformuje w klasyfikator. Dziś przybliżę strategie doboru punktu odcięcia, celowo pomijając aspekty techniczne związane z analityką predykcyjną – tym zajmiemy się w kolejnym odcinku (opisując skumulowane prawdopodobieństwo, skumulowany lift, krzywą zysku aka Gain Curve lub Captured Response oraz krzywą ROC).
Dobór punktu odcięcia – strategie (z którymi miałem do czynienia w pracy zawodowej)
Całkowicie biznesowa – metoda najprostsza, nadal popularna, jednak coraz rzadziej stosowana.
Wyłącznie analityczna– rzadko stosowane w biznesie, częściej widoczna pracach / badaniach naukowych.
Hybryda powyższych – wariant dziś preferowany przez różne jednostki CRM.
Dobór całkowicie biznesowy
Nadal częsta praktyka, która przy wnikliwej analizie okazuje się nie być najbardziej optymalną. W strategii „całkowicie biznesowej” dobór punktu odcięcia jest pochodną zasobów (np. dostępność/ pojemność kanałów komunikacji). Przykładowo – współpracujemy z call center, które miesięcznie może zadzwonić do 100 tys. Klientów. W takiej sytuacji dosyć naturalnie powstaje potrzeba wybrania „100 tys. najlepszych Klientów” (najlepszych do danej akcji). Model predykcyjny posłuży więc do „posortowania” Klientów, a punkt odcięcia będzie zależny od wskazanej oczekiwanej liczby 100 tys. Problem ze strategią całkowicie biznesową polega na tym, że „najlepszy” mylony jest z „dobry”. Dodatkowo zdarza się, że siła modelu jest błędnie interpretowana jako zdolność do znalezienie większej liczby „dobrych” klientów – w rzeczywistości jest na odwrót – im lepszy model, tym mniejsze optymalne bazy. Równie istotna kwestia to skąd się właściwie wzięła liczba 100 tys?
Dobór wyłącznie analityczny
Dobór wyłącznie analityczny polega na optymalizacji błędów klasyfikacji – w nieco bardziej zgeneralizowanym podejściu optymalizuje się funkcję kosztu błędów(najczęściej jeśli koszty są mocno asymetryczne). Podejście analityczne jest zupełnie poprawna i uzasadnione, jednak w biznesie prawie nieobecne ze względu na brak uwzględnionego aspektu celu biznesowego, priorytetów, zasobów, itp.
Dobór analityczno-biznesowy
Dobór analityczno-biznesowy (jako połączenie powyższych strategii) najlepiej sprawdza się w sytuacji analizy szerszego portfela produktów (tzn. bazy i cut-off’y dobierane do różnych działań stanowią element realizacji szerszej polityki CRM). Zaczynamy od celów biznesowych, priorytetów, analizy zasobów, pojemności kanałów. Następnie weryfikujemy Klientów, ich potrzeby w kontekście możliwie wielu produktów. Ostatecznie – w wyniku kilku iteracji – dążymy do „zmapowania” segmentów Klientów na cele i zasoby, zawsze koniecznie modyfikując obie strony równania. Jest to trudne i wielowymiarowe zadanie, zadanie zawsze „niedokończone”, coraz bardziej opierające się na różnego rodzaju eksperymentach … ale o tym w kolejnych częściach cyklu …
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Ze statystyk odwiedzin wynika, że cykl „Ocena jakości klasyfikacji” cieszy się Waszym zainteresowaniem – zatem wracam do tej tematyki. Dziś przedstawię wstęp do analizy jakości modeli predykcyjnych, skupiając się na jednym tylko aspekcie jakości – tzn. na sile modelu w kontekście separacji klas. Zapraszam 🙂
Jakość modelu predykcyjnego
Matematyka dostarcza wielu różnych miar służących ocenie siły modelu predykcyjnego. Różne miary są często ze sobą mocno powiązane, i choć przedstawiają bardzo podobne informacje, umożliwiają spojrzenie na zagadnienie z innych perspektyw. Przez jakość modelu predykcyjnego rozumiemy typowo ocenę jakości w trzech obszarach:
Analiza siły separacji klas – czyli jak dalece wskazania modelu są w stanie „rozdzielić” faktycznie różne klasy pozytywny i negatywne;
Analiza jakość estymacji prawdopodobieństwa – bardzo ważne w sytuacjach wymagających oceny wartości oczekiwanych, tzn. poszukujemy wszelkiego rodzaju obciążeń (inaczej – błędów systematycznych);
Analiza stabilności w czasie – kluczowy aspekt rzutujący na możliwość wykorzystywania modelu w faktycznych przyszłych działaniach.
Wszystkie wymienione obszary są ze sobą powiązane terminem prawdopodobieństwa, za pomocą którego można wyrazić zarówno siłę separacji, jak też stabilność w czasie.
Założenia
Podobnie do poprzednich część cyklu załóżmy, że rozważamy przypadek klasyfikacji binarnej (dwie klasy: „Pozytywna – 1” oraz „Negatywna – 0”). Załóżmy ponadto, że dysponujemy modelem predykcyjnym $p$ zwracającym prawdopodobieństwo $p(1|x)$ przynależności obserwacji $x$ do klasy „Pozytywnej -1” (inaczej „P od 1 pod warunkiem, że x”). I jeszcze ostatnie założenie, wyłącznie dla uproszczenia wizualizacji i obliczeń – dotyczy rozmiaru klasy pozytywnej – ustalmy, że jej rozmiar to 20%, inaczej, że prawdopodobieństwo a-priori P(1)=0.2.
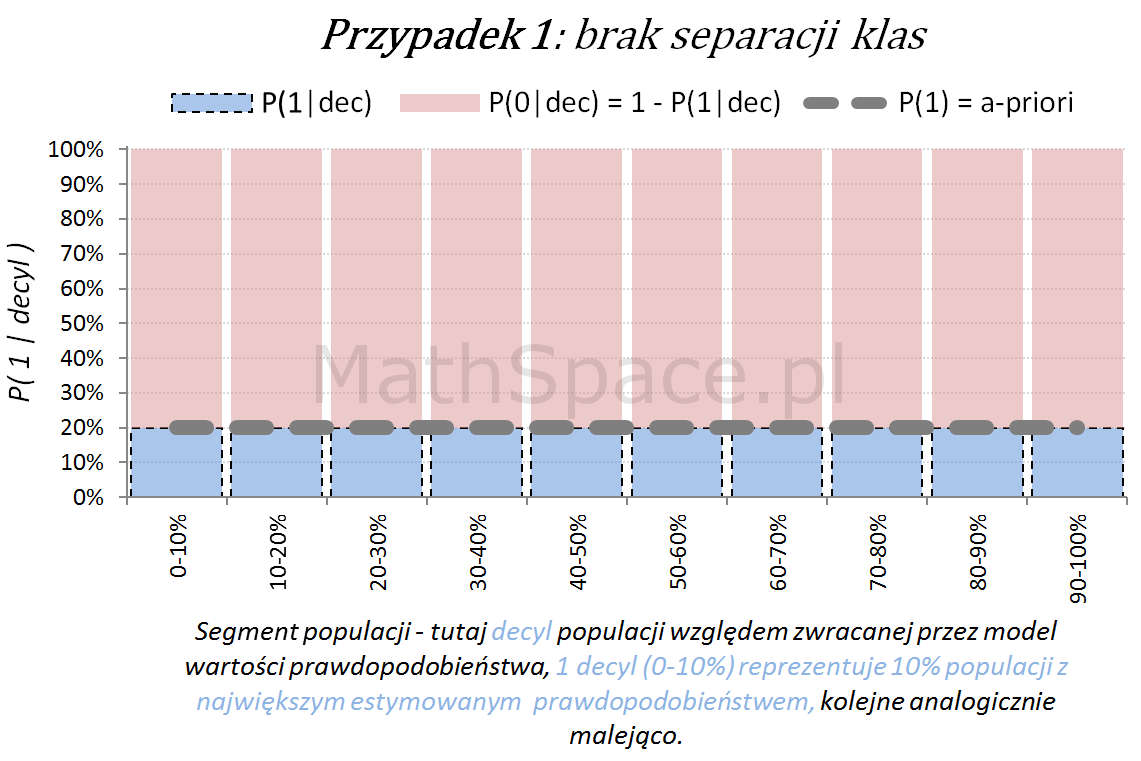
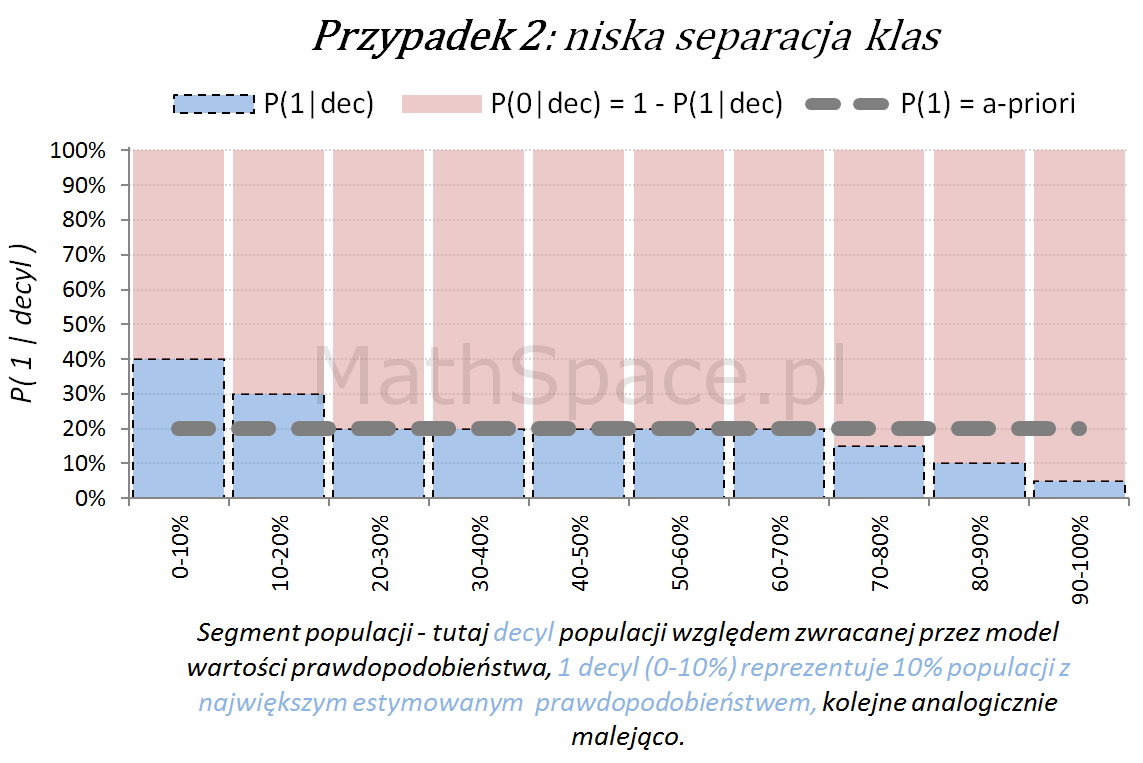
Model predykcyjny a siła separacji klas – nieskumulowane prawdopodobieństwo
Poniżej przedstawiamy różne przypadki wizualnej oceny siły modelu. Interpretacja zamieszczonych wykresów jest następująca:
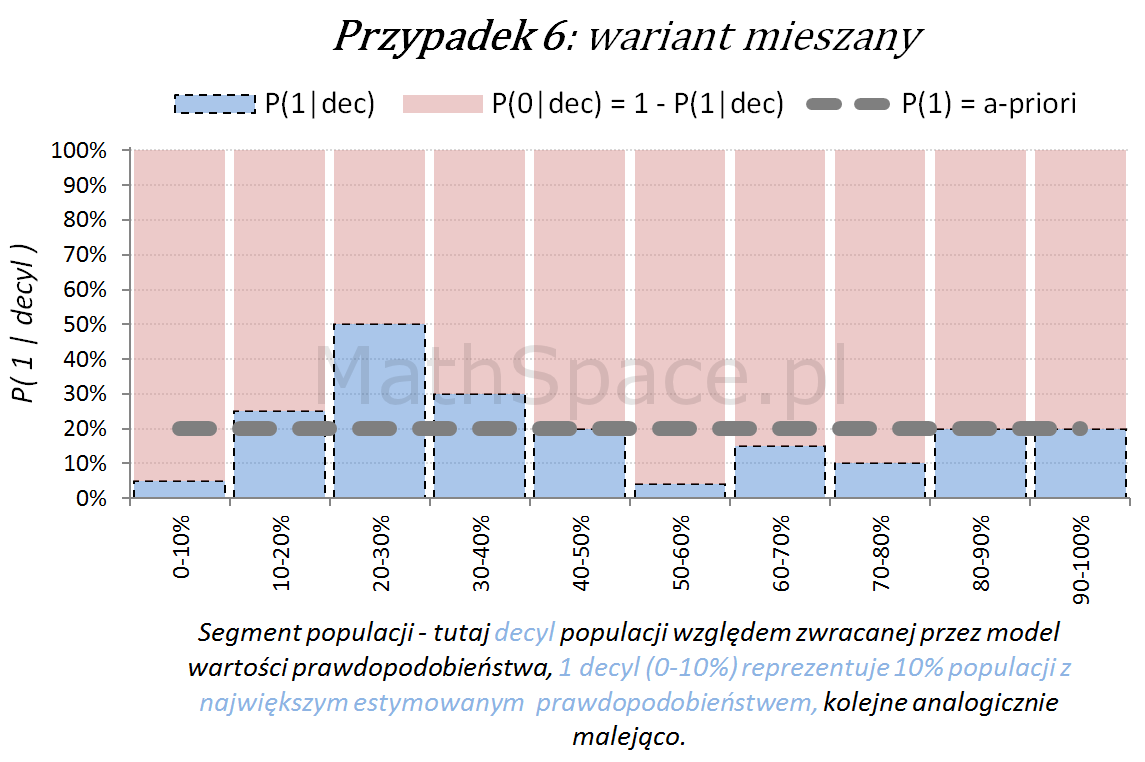
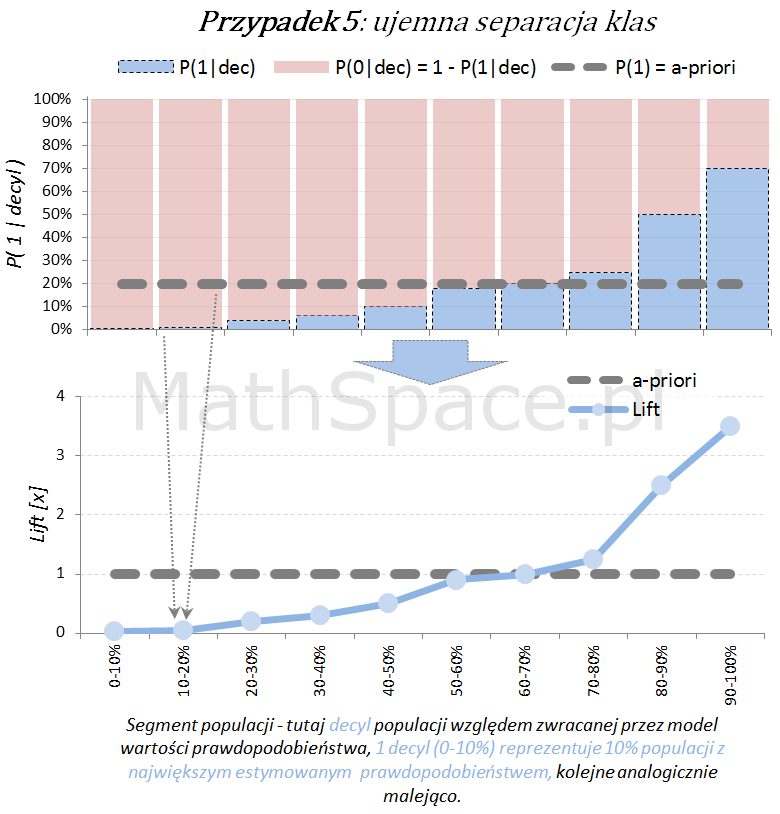
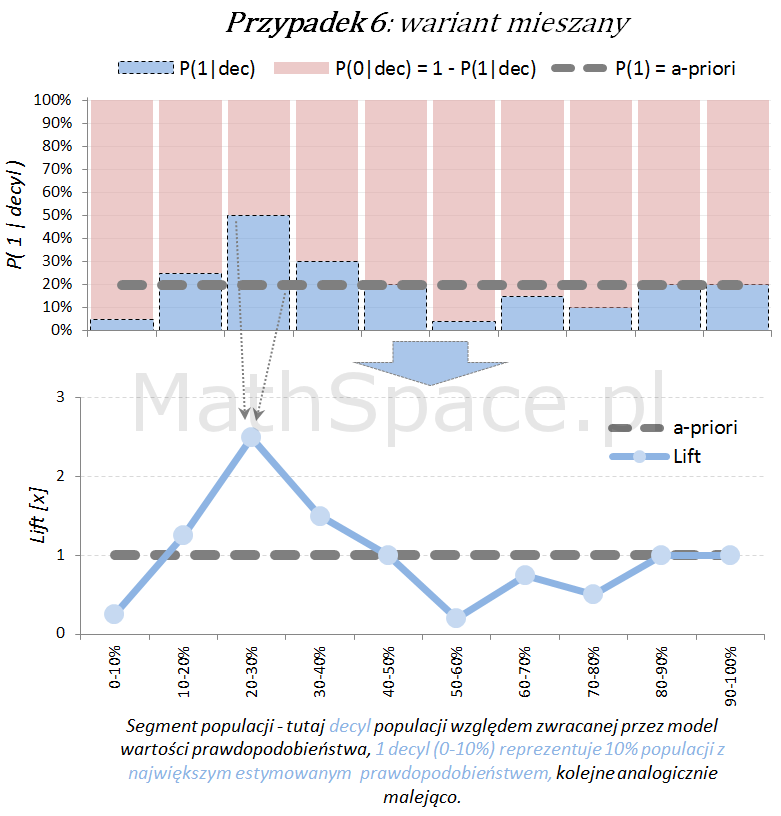
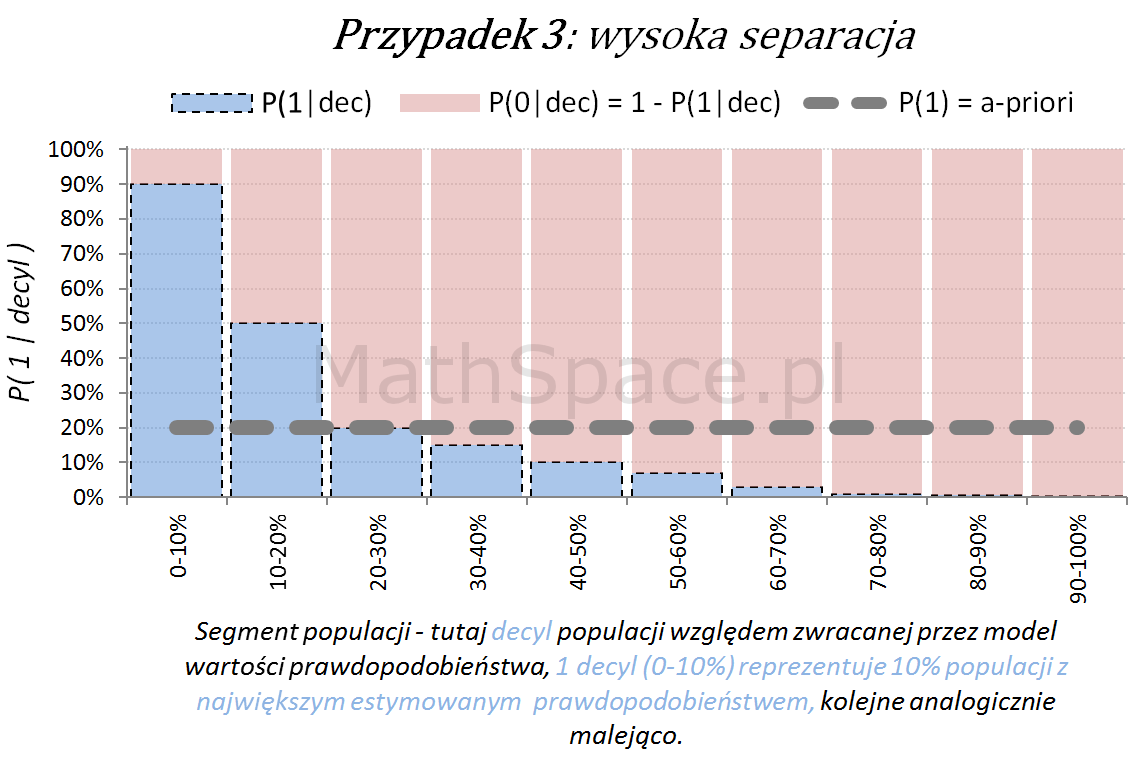
Oś pozioma reprezentuje kolejne segmenty populacji, tu zostały użyte decyle bazy względem zwracanej wartości prawdopodobieństwa przez model. Zatem 1 decyl agreguje 10% populacji z największym estymowanym prawdopodobieństwem, kolejne decyle – analogicznie.
Oś pionowa przedstawia prawdopodobieństwo warunkowe, że obserwacja z danego segmentu populacji (tutaj decyl bazy) faktycznie pochodzi z klasy „Pozytywnej – 1”.
Naturalnym jest, że model predykcyjny posiadający dodatnią siłę separacji klas, wykorzystany do podziału populacji na segmenty względem wartości malejącej (tutaj 10 decyli), powinien wpłynąć na faktyczną częstość obserwacji klasy „Pozytywnej – 1”. Tzn. w pierwszych decylach powinniśmy widzieć więcej klasy „1” – kolejne przykłady właśnie to obrazują.
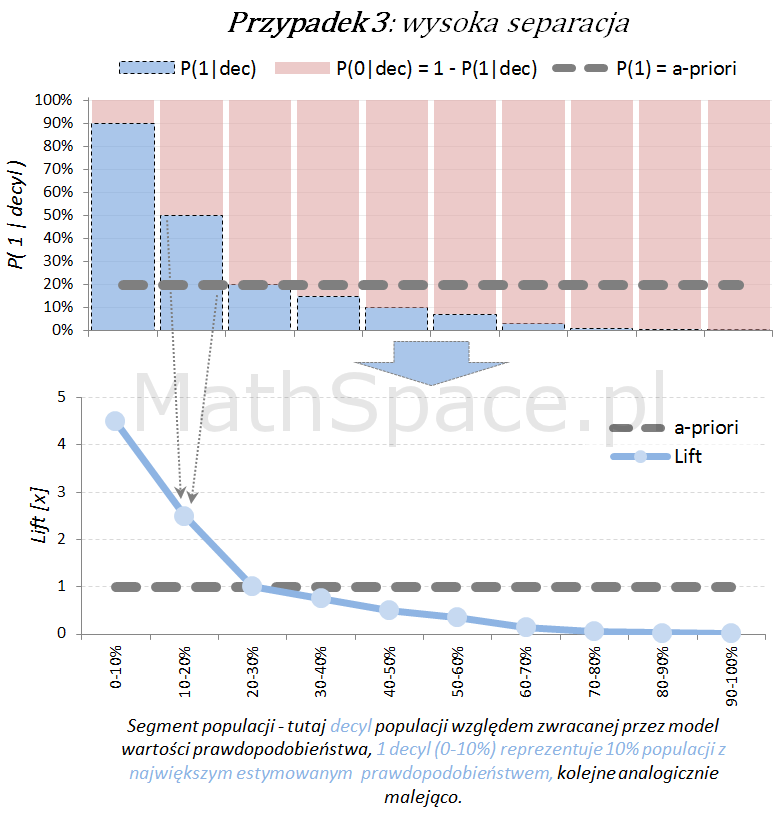
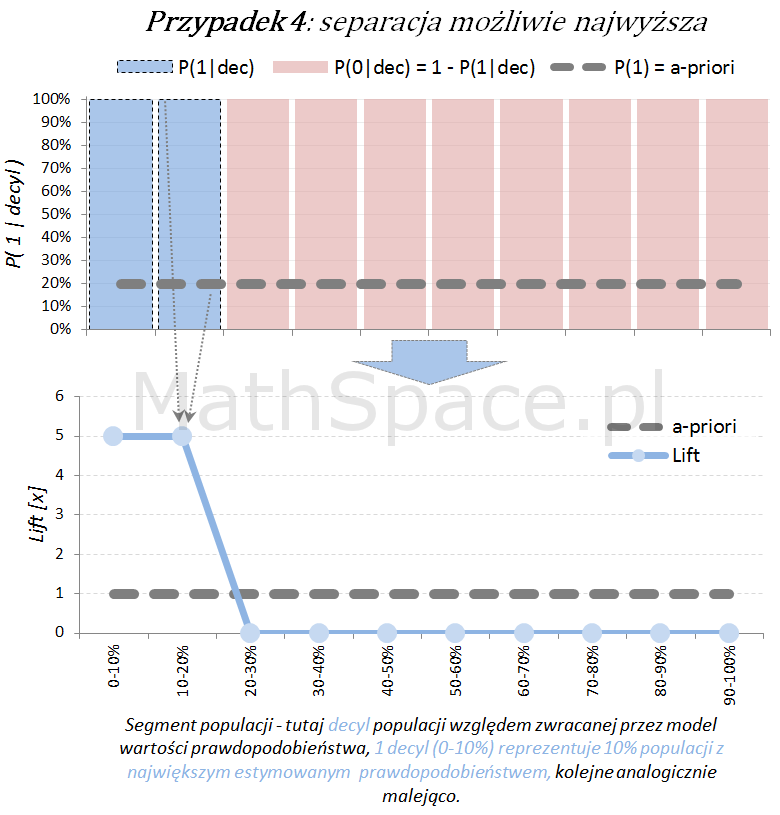
Dla każdego przypadku klasyfikacji istnieje również teoretyczny model idealny, z możliwie najwyższą siłą separacji klas. Tak model się „nie myli”, co obrazuje poniższy schemat.
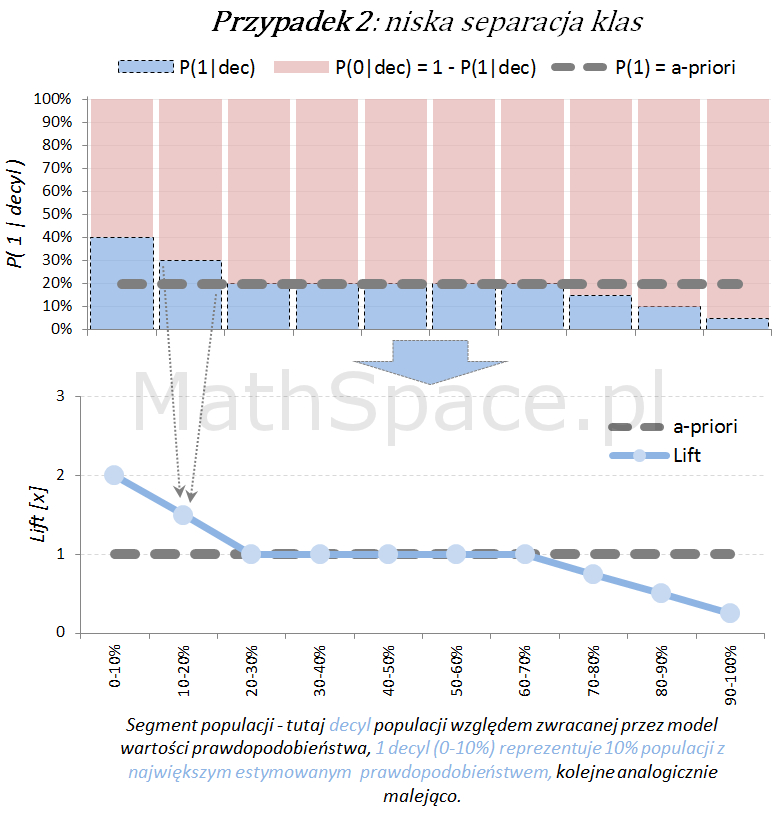
Inne „nietypowe” przypadki (jednak czasami spotykane w praktyce) to modele z ujemną korelacją w stosunku do targetu.
Ostatecznie możliwy jest również wariant „mieszany”, obserwowany często po długim czasie wykorzystywania modelu, bez jego aktualizacji, w wyniku zmian w danych, błędów w danych, zmian definicji klas (tzw, targetu), itp.
Model predykcyjny a siła separacji klas – nieskumulowany lift
Lift jest normalizacją oceny prawdopodobieństwa do rozmiaru klasy pozytywnej, czyli do rozmiaru reprezentowanego przez prawdopodobieństwo a-priori $P(1)$. Lift powstaje przez podzielenie wartości prawdopodobieństwa właściwej dla segmentu przez prawdopodobieństwo a-priori. W ten sposób powstaje naturalna interpretacja liftu, jako krotności w stosunku do modelu losowego (czyli modeli bez separacji klas):
lift < 1 – mniejsza częstość „klasy 1” niż średnio w populacji
lift = 1 – częstość „klasy 1” na średnim poziomie dla populacji
lift > 1 – większa częstość „klasy 1” niż średnio w populacji
Poniżej prezentacja graficzna
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Książka: Customer First, Value Next
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Zarządzaj zgodą
Aby zapewnić jak najlepsze wrażenia, korzystamy z technologii, takich jak pliki cookie, do przechowywania i/lub uzyskiwania dostępu do informacji o urządzeniu. Zgoda na te technologie pozwoli nam przetwarzać dane, takie jak zachowanie podczas przeglądania lub unikalne identyfikatory na tej stronie. Brak wyrażenia zgody lub wycofanie zgody może niekorzystnie wpłynąć na niektóre cechy i funkcje.
Funkcjonalne
Zawsze aktywne
Przechowywanie lub dostęp do danych technicznych jest ściśle konieczny do uzasadnionego celu umożliwienia korzystania z konkretnej usługi wyraźnie żądanej przez subskrybenta lub użytkownika, lub wyłącznie w celu przeprowadzenia transmisji komunikatu przez sieć łączności elektronicznej.
Preferencje
Przechowywanie lub dostęp techniczny jest niezbędny do uzasadnionego celu przechowywania preferencji, o które nie prosi subskrybent lub użytkownik.
Statystyka
Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do celów statystycznych.Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do anonimowych celów statystycznych. Bez wezwania do sądu, dobrowolnego podporządkowania się dostawcy usług internetowych lub dodatkowych zapisów od strony trzeciej, informacje przechowywane lub pobierane wyłącznie w tym celu zwykle nie mogą być wykorzystywane do identyfikacji użytkownika.
Marketing
Przechowywanie lub dostęp techniczny jest wymagany do tworzenia profili użytkowników w celu wysyłania reklam lub śledzenia użytkownika na stronie internetowej lub na kilku stronach internetowych w podobnych celach marketingowych.
Cześć, z tej strony Mariusz Gromada, autor bloga MathSpace.pl.
Znacie mnie z tekstów o nauce i matematyce. Równolegle – od ponad 20 lat – zajmuję się projektowaniem, wdrażaniem oraz wykorzystywaniem wielkoskalowych systemów personalizacji w organizacjach B2C. Tę podwójną perspektywę – analityczno-inżynierską i biznesową – zebrałem w mojej najnowszej książce:
„Customer First, Value Next: The Executive Playbook for AI-Driven Omnichannel Personalization and Customer-Centric Growth.”
Jeśli jesteś liderem biznesowym, liderem technologicznym, inżynierem, analitykiem lub po prostu fascynuje Cię budowa skalowalnych systemów AI, które potrafią zrozumieć klienta – odchodząc od tradycyjnego modelu produktowego – to ta pozycja jest dla Ciebie.
„Technologia to nie tylko narzędzie do automatyzacji. To megafon dla empatii.”







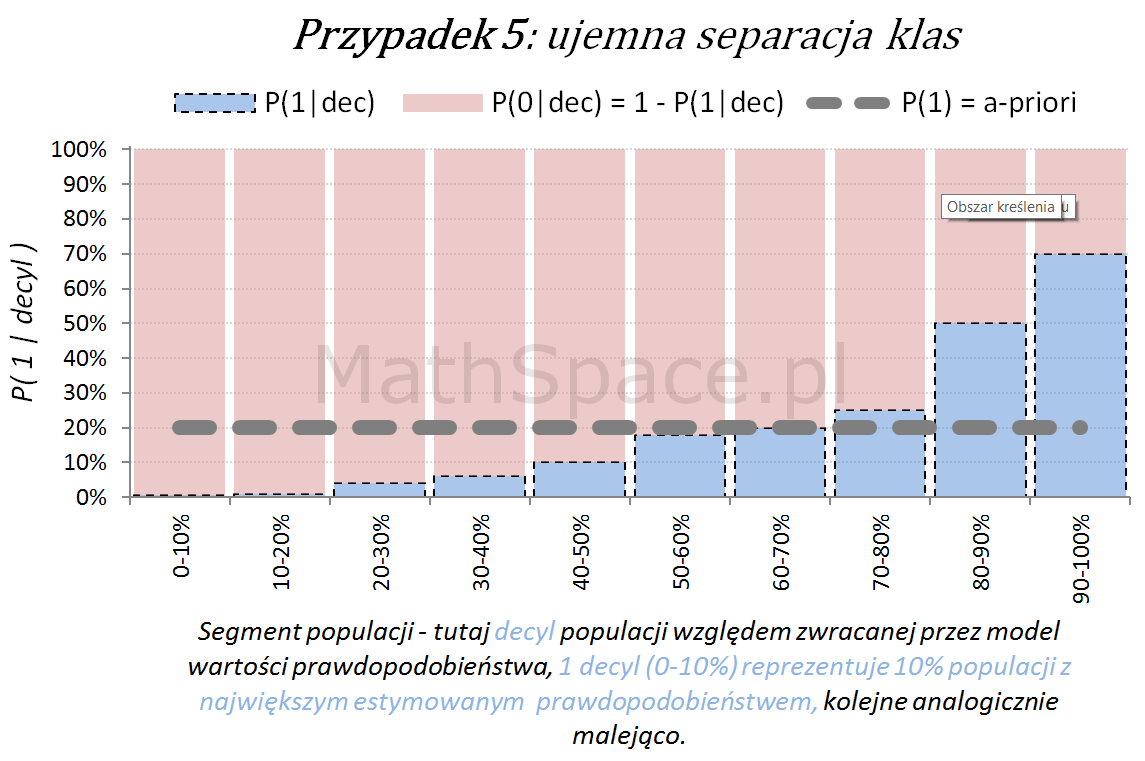 Ostatecznie możliwy jest również
Ostatecznie możliwy jest również