Przesłanie od Matematyki – szczególnie aktualne! Nie jestem autorem poniższej grafiki – dlatego podziękowania dla unearthedcomics.com – świetny dodatek do serii „Matematyka w obrazkach”.
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
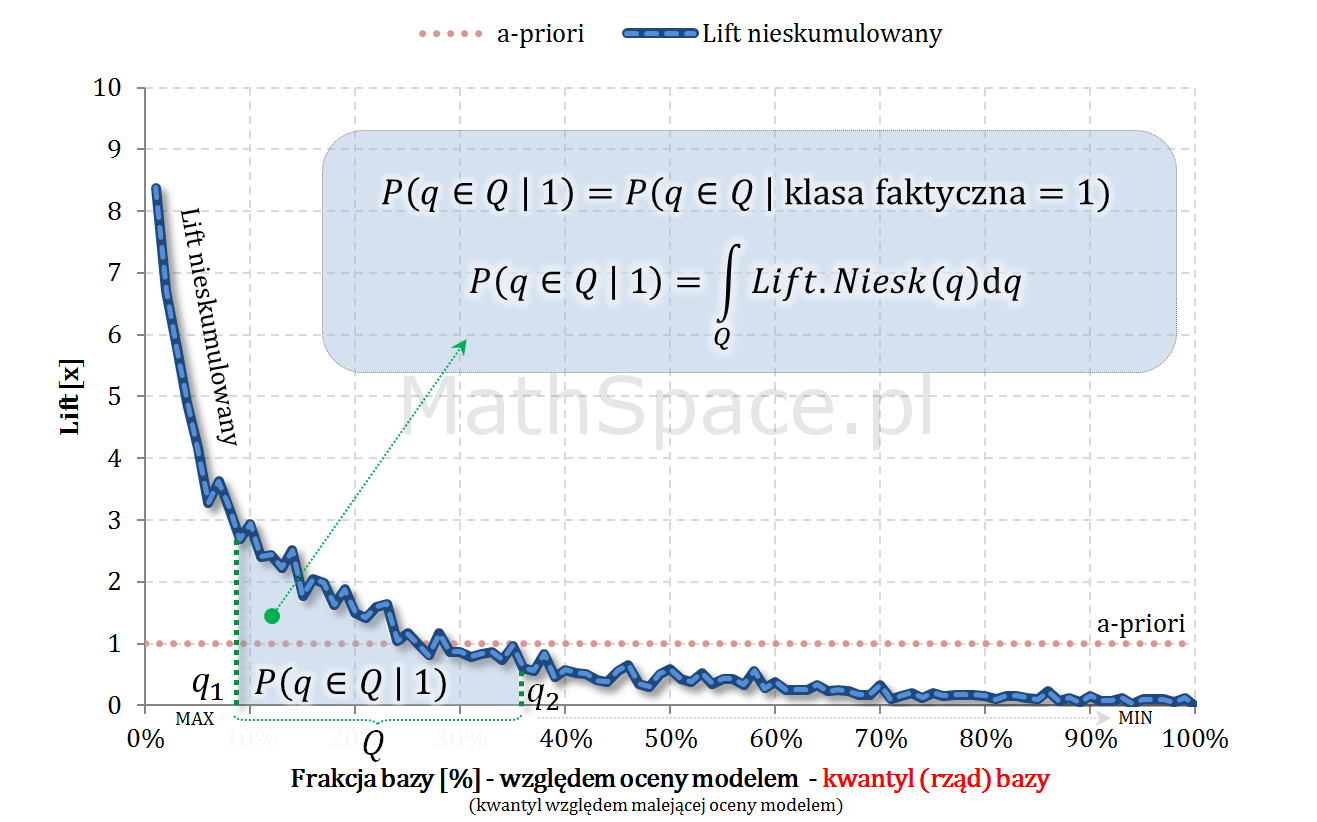
W 13 części cyklu „Ocena jakości klasyfikacji” przedstawię dodatkowe interpretacje dla krzywej liftu nieskumulowanego i krzywej Captured Response. Obiecuję, że będzie ciekawie 🙂 przecież robimy „deep dive into predictive model assessment curves”. W dzisiejszym odcinku zapomnimy o punktach odcięcia, klasyfikatorach binarnych, rozważając rozkłady populacji jako całość. Chwilkę się do tego przygotowywałem – było warto – seria „Tips & Tricks na krzywych” nabiera rumieńców!
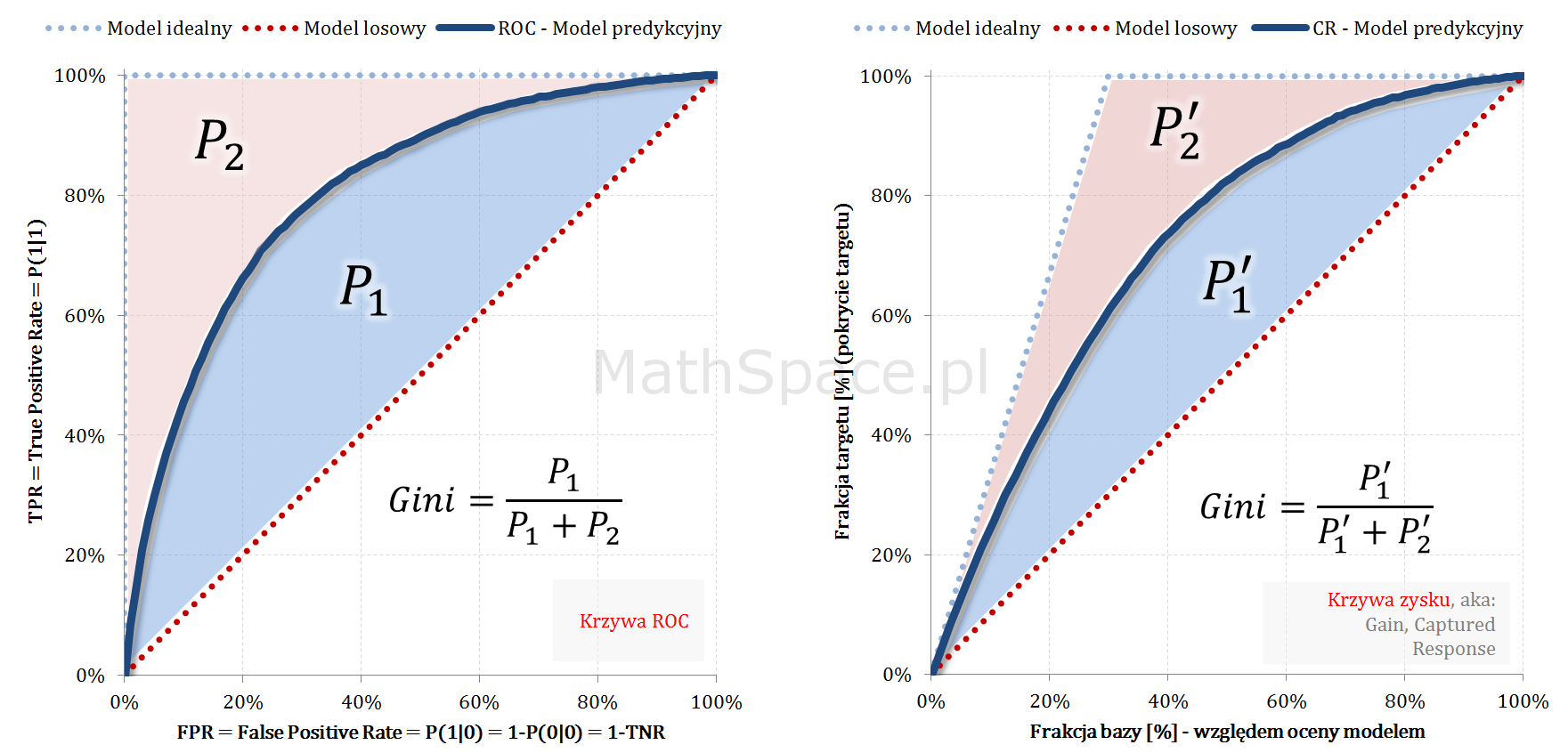
Pole powierzchni pod krzywą liftu nieskumulowanego
Lift nieskumulowany dla modelu losowego to funkcja stała o wartości 1. Pole pod taką krzywą równe jest polu kwadratu o boku 1 i wynosi oczywiście 1. Model losowy „rozrzuca” obserwacje z „klasy 1” równomiernie, tzn. taka sama część otrzymuje wysoki, średni i niski score. Głównym zadaniem modelu predykcyjnego, w pewnym sensie, jest „przepchnąć” obserwacje należące do „klasy 1” z segmentu niskiego score do segmentu wysokiego score – dzięki temu pojawia się separacja klas. Powyższe dobrze obrazuję animacją, gdzie siła modelu utożsamiana jest z „siłą podmuchu wiatru” 🙂
Takie „przepchnięcie” nie ma wpływu na ilość „jedynek”, zatem należy podejrzewać, że pole pod krzywą liftu nieskumulowanego zawsze wynosi 1. No to całkujemy:
$$\displaystyle\int_0^1 Lift.Niesk(q)dq$$
Oznaczenia + zależności:
$N=N_1+N_0$ – liczba obserwacji: łączna, z „klasy 1”, z „klasy 0”;
$k$ – liczba przedziałów, na które dzielimy odcinek $[0;1]$;
$p=\frac{1}{k}$ – szerokość pojedynczego przedziału (zakres zmienności rzędu kwantyli);
$p\cdot N$ – liczba obserwacji w przedziale (podział po kwantylach, zatem po równo);
$i=\{1,2,3,\ldots,k\}$ – numer przedziału;
$n_1^i+n_0^i=pN$ – liczba obserwacji w przedziale, osobno „z klasy 1” i „z klasy 0”;
$\Delta q^i$ – przedział, na którym wyznaczona jest wartość liftu nieskumulowanego;
$\displaystyle\sum_{i=1}^k n_1^i=N_1$
$\displaystyle\sum_{i=1}^k n_0^i=N_0$
$\displaystyle\sum_{i=1}^k n_1^i+n_0^i=N_1+N_0=N$
Lift nieskumulowany jest funkcją przedziałami stałą:
Lift nieskumulowany jako funkcja gęstości rozkładu prawdopodobieństwa
Funkcja liftu nieskumulowanego jest nieujemna i spełnia warunek „unormowania” (w przeciwieństwie do funkcji nieskumulowanego prawdopodobieństwa) w kontekście gęstości rozkładu prawdopodobieństwa – tzn. pole powierzchni pod krzywą wynosi 1. Taka gęstość opisuje rozkład rzędu kwantyli (kwantyle wyznaczane dla całej populacji „klasa 0 + klasa 1” względem malejącej oceny modelem) w klasie faktycznie pozytywnej – tzn. w „klasie 1”.
Captured Response jako dystrybuanta rozkładu prawdopodobieństwa
Captured Response jest funkcją niemalejącą, jednostronnie ciągłą (powiedzmy, że prawostronnie), o wartościach z przedziału $[0;1]$, wartości 0 dla $q\leq 0$ oraz wartości 1 dla $q\geq 1$. Tym samym spełnione są warunki bycia dystrybuantą pewnego rozkładu prawdopodobieństwa. W części „#11 – Captured Response vs Lift” wykazałem, że pochodna z Captured Response to lift nieskumulowany. Wniosek: Captured Response i lift nieskumulowany to dystrybuanta i gęstość tego samego rozkładu prawdopodobieństwa.
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
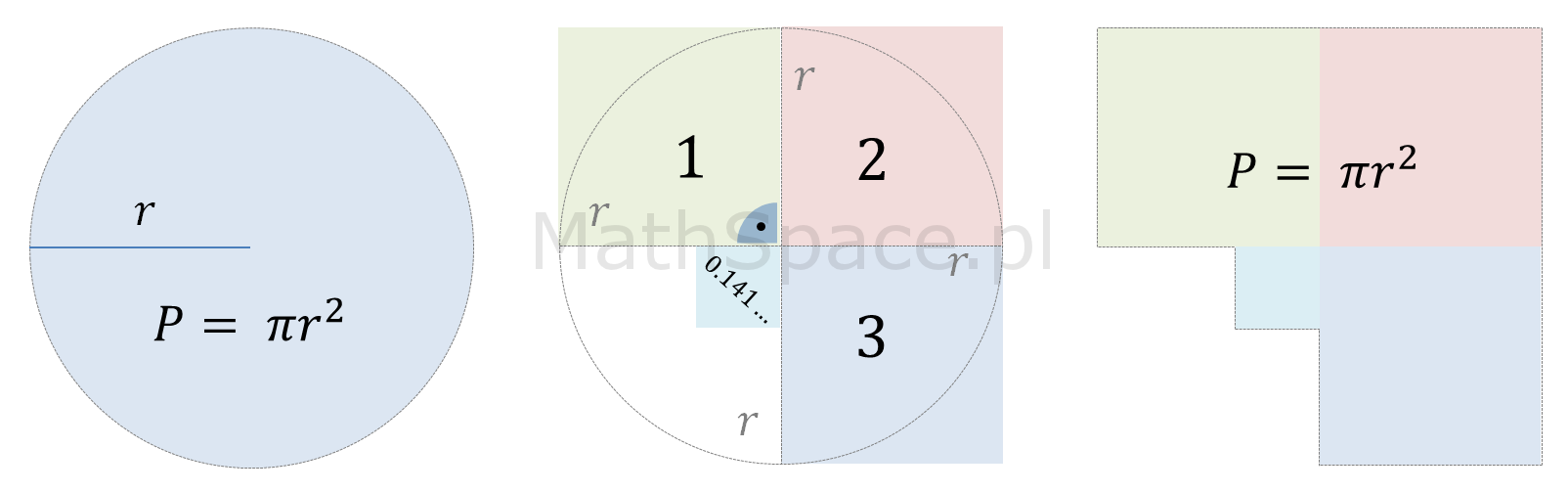
$P=\pi r^2$ to chyba najbardziej znany wzór, będący zarazem rzadko rozumianym 🙂 Choć wzór na pole powierzchni koła, bo o nim tu mowa, znany był już w Starożytnej Grecji, to jego uzasadnienie wcale nie jest łatwe. Jest to zatem świetny temat do wzbogacenia cyklu „Dlaczego?” 🙂 Do dzieła! 🙂
Pole powierzchni koła – wzór
$$P=\pi r^2$$
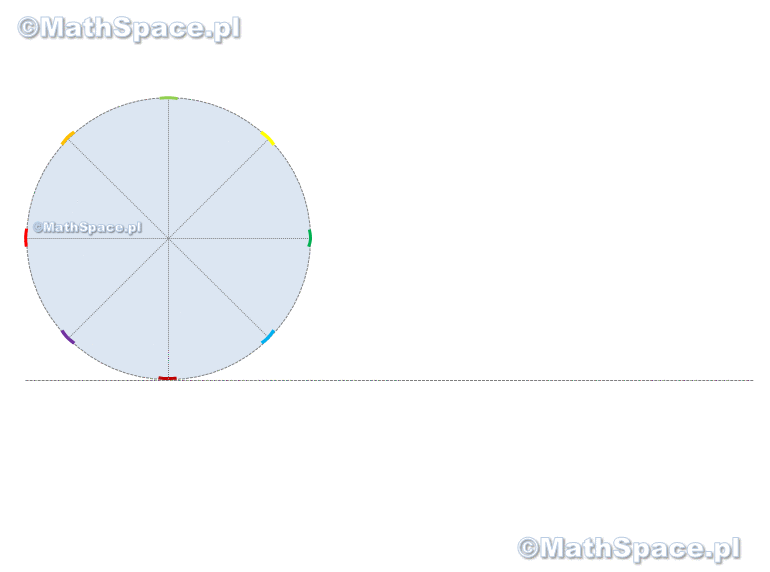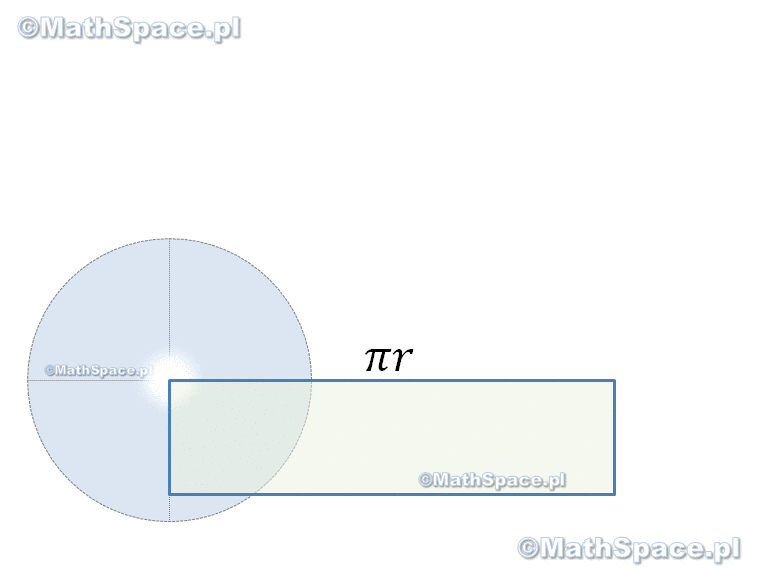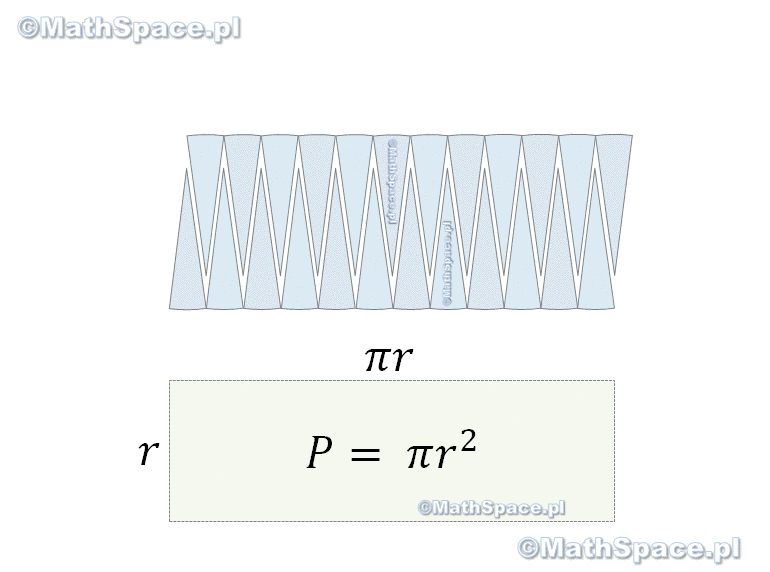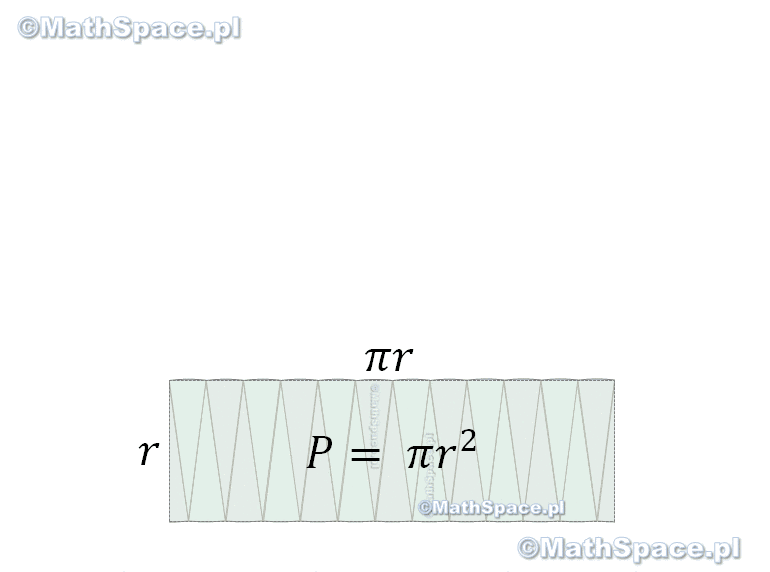
Jak widać powyżej – kwadrat i koło, o tej samej powierzchni, nie są „jakoś intuicyjnie łatwo” powiązane. Więcej – wykazano nawet, że kwadratura koła (procedura wykonywana przy użyciu cyrkla i linijki bez podziałki) jest niewykonalna! I tu pojawia się genialny pomysł z prostokątem 🙂 Nim powiem o co chodzi przyjrzyjmy się co tak naprawdę mówi wzór $$\pi r^2$$.
$\pi\times r^2$ – czyli w kole mieszczą się nieco ponad 3 kwadraty o boku r 🙂
Pole powierzchni koła – dowód przez animację 🙂
Trochę się napracowałem przy tej animacji 🙂
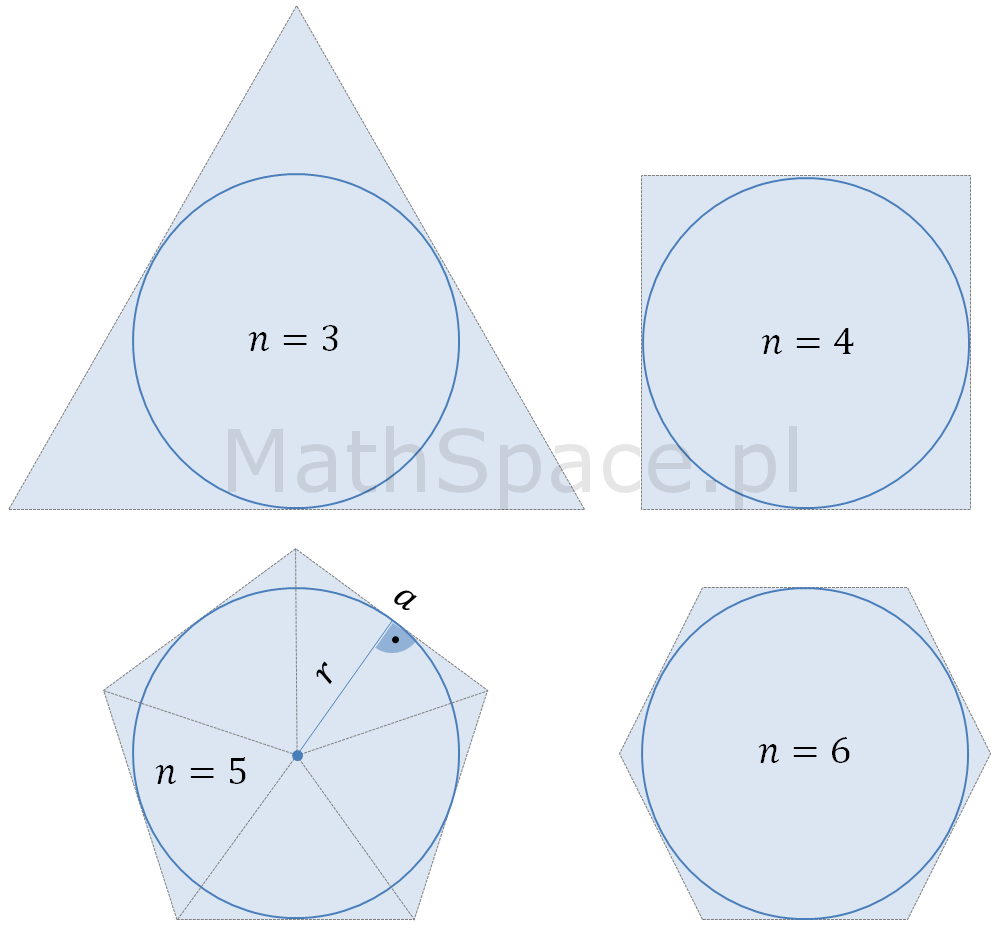
Pole powierzchni koła – wielokąty foremne
Uwaga – poniższe nie jest dowodem, a obrazuje jedynie sposób wnioskowania stosowany przez Starożytnych Greków (tak np. Archimedes wyznaczał liczbę pi).
Można zauważyć, że obwód n-kąta foremnego opisanego na kole wynosi
$$O_n=na$$
a jego pole to suma pól trójkątów o podstawie $a$ i wysokości równej promieniowi koła $r$.
Niech będą dane trzy ciągi rzeczywiste $a_n$, $b_n$ i $c_n$. Jeśli „prawie wszędzie” (tzn. pomijając co najwyżej skończenie wiele wyrazów) zachodzi zależność
Przyda się również $\lim_{x\to 0}\frac{\sin x}{x} = 1$
Pamiętam jak w szkole średniej, na lekcjach fizyki, mój nauczyciel wielokrotnie przyjmował, że dla małych $x$ funkcję $\sin x$ dobrze przybliża właśnie $x$. Wynika to z rozwinięcia $\sin x$ w szereg Taylora – wyjaśnienie pomijam. Wyznaczę jednak samą granicę – bo się przyda 🙂
$$\lim_{x\to 0}\frac{\sin x}{x}=\big(\frac{0}{0}\big)\text{ reg. de l`Hospitala}=$$
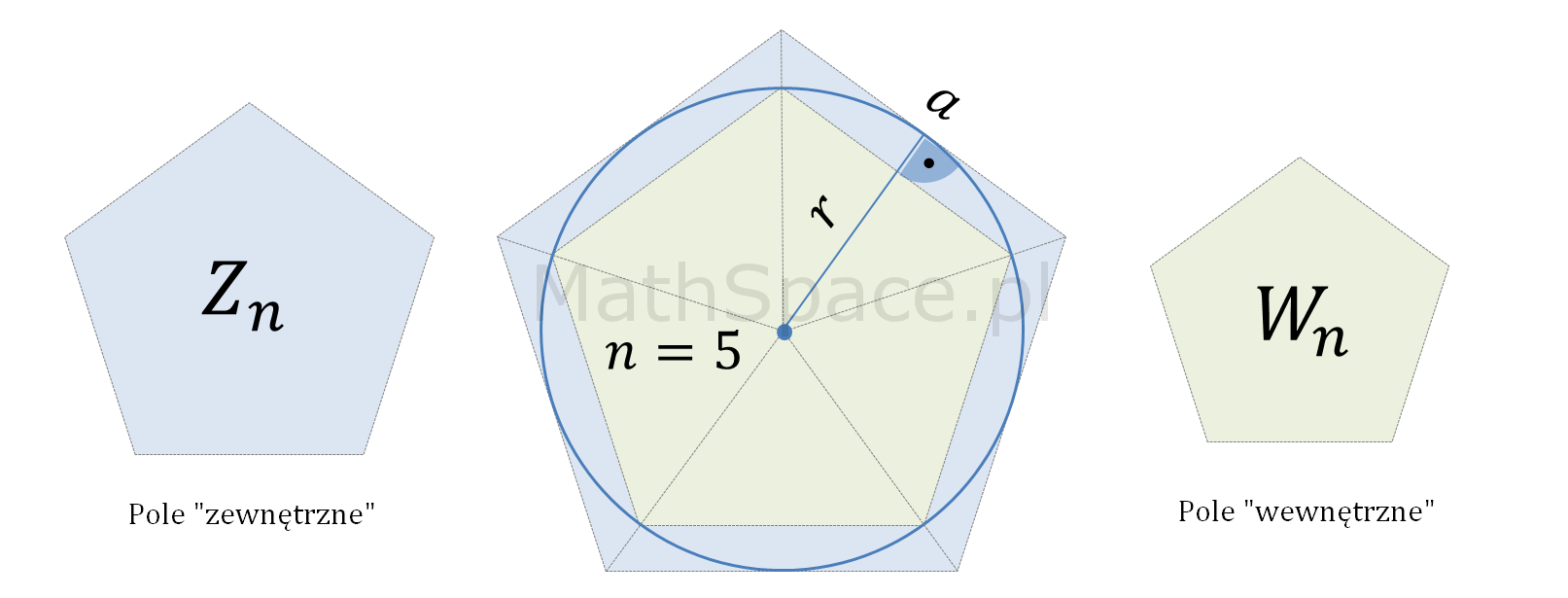
Rozważmy n-kąty foremne opisane na kole i wpisane w koło. Pole n-kąta opisanego nazwijmy „polem zewnętrznym” i oznaczmy $Z_n$. Analogicznie pole n-kąta wpisanego nazwiemy „polem wewnętrznym” oznaczając je $W_n$.
Oczywiście
$$W_n\leq P\leq Z_n$$
gdzie $P$ oznacza pole koła.
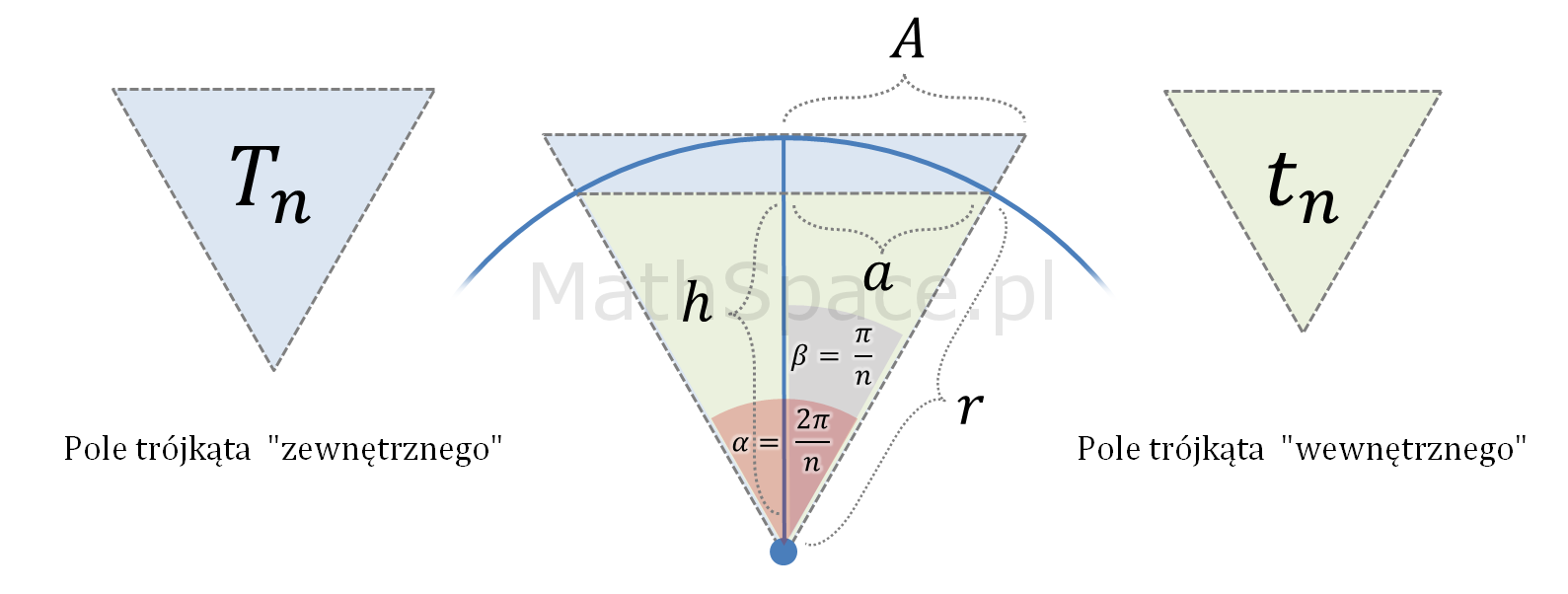
W kolejnym kroku dzielimy n-kąty na n-trójkątów. Zauważmy, że w ten sposób kąt pełny został również podzielony na n równych części. Pole „trójkąta zewnętrznego” oznaczymy przez $T_n$, a trójkąta wewnętrznego $t_n$.
Z twierdzenia o trzech ciągach wnioskujemy, że pole koła to
$$P=\lim W_n=\lim Z_n=\pi r^2$$
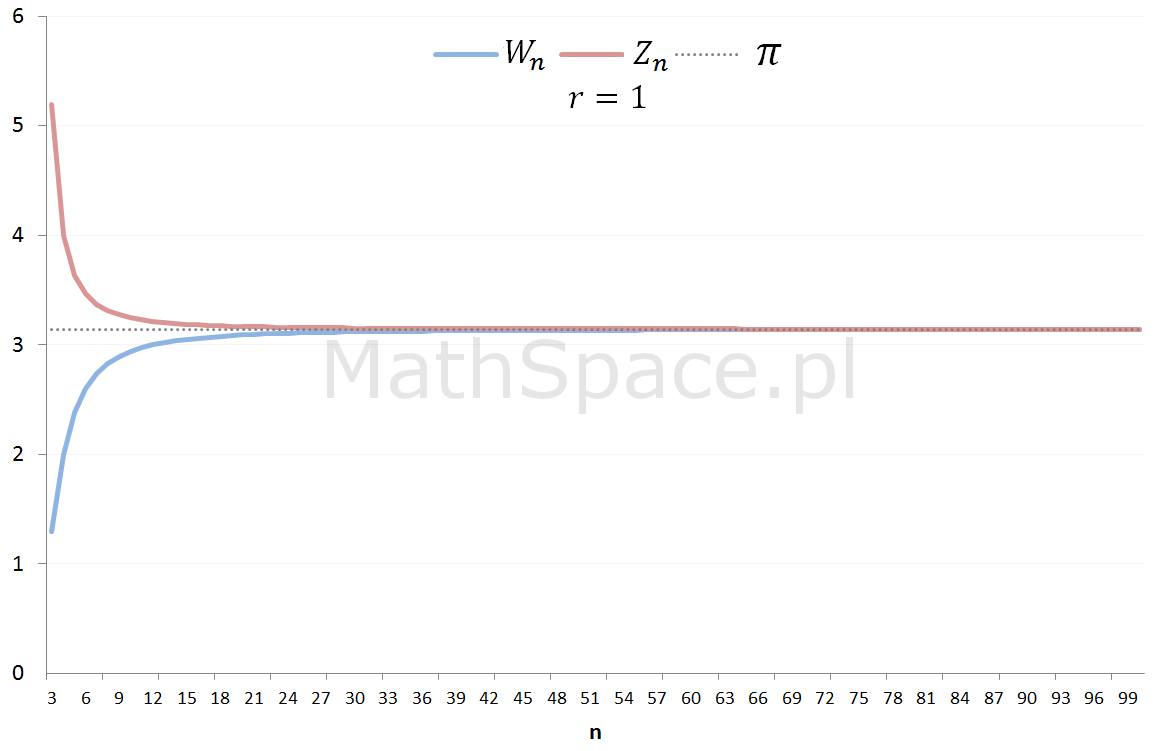
Tempo zbieżności ciągów $W_n$ oraz $Z_n$
🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Twierdzenie o trzech ciągach! Ola– dzięki za cenny pomysł! Znacząco wzbogacił cykl „Matematyka w obrazkach” 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
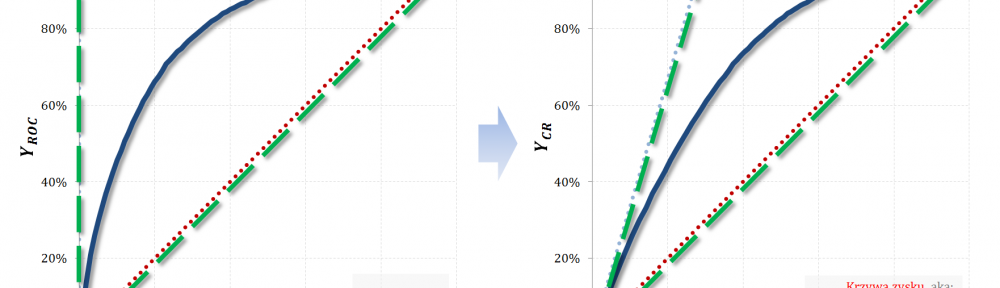
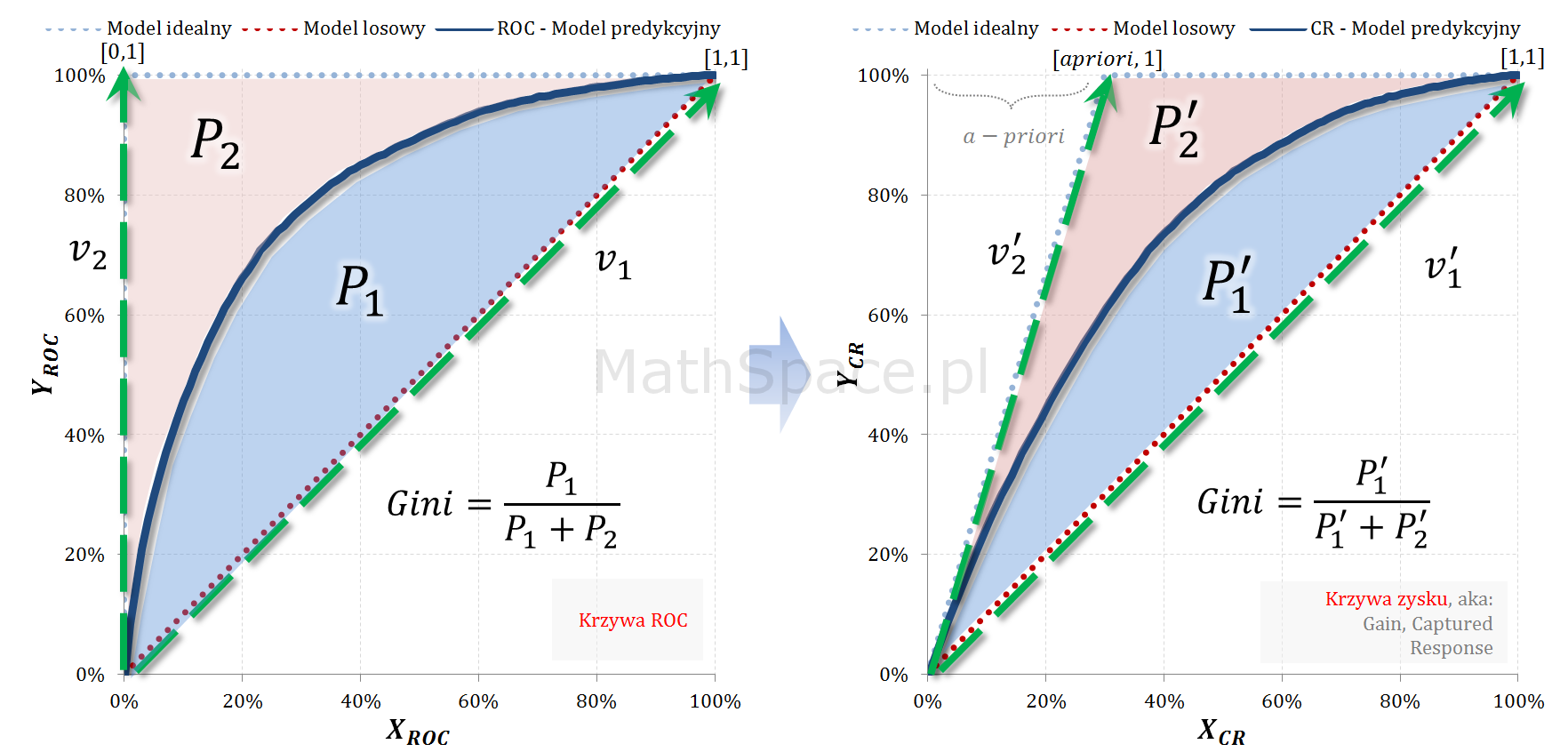
Wskaźnik Giniego, który opisałem w części #7 poświęconej krzywej ROC, jest jednym z najważniejszych narzędzi wykorzystywanych w procesie oceny jakości klasyfikacji. Choć krzywa ROC jest ważna i bardzo przydatna, to z mojego doświadczenia wynika, że większość analityków woli wykreślać krzywą Captured Response. Sądzę, że wszyscy intuicyjnie czujemy, że „Gini z ROC” i „Gini z Captured Response” to to samo 🙂 Ale dlaczego tak jest? 🙂 Dziś odpowiem na to pytanie, jednocześnie wzbogacając serię „Tips & Tricks na krzywych”!
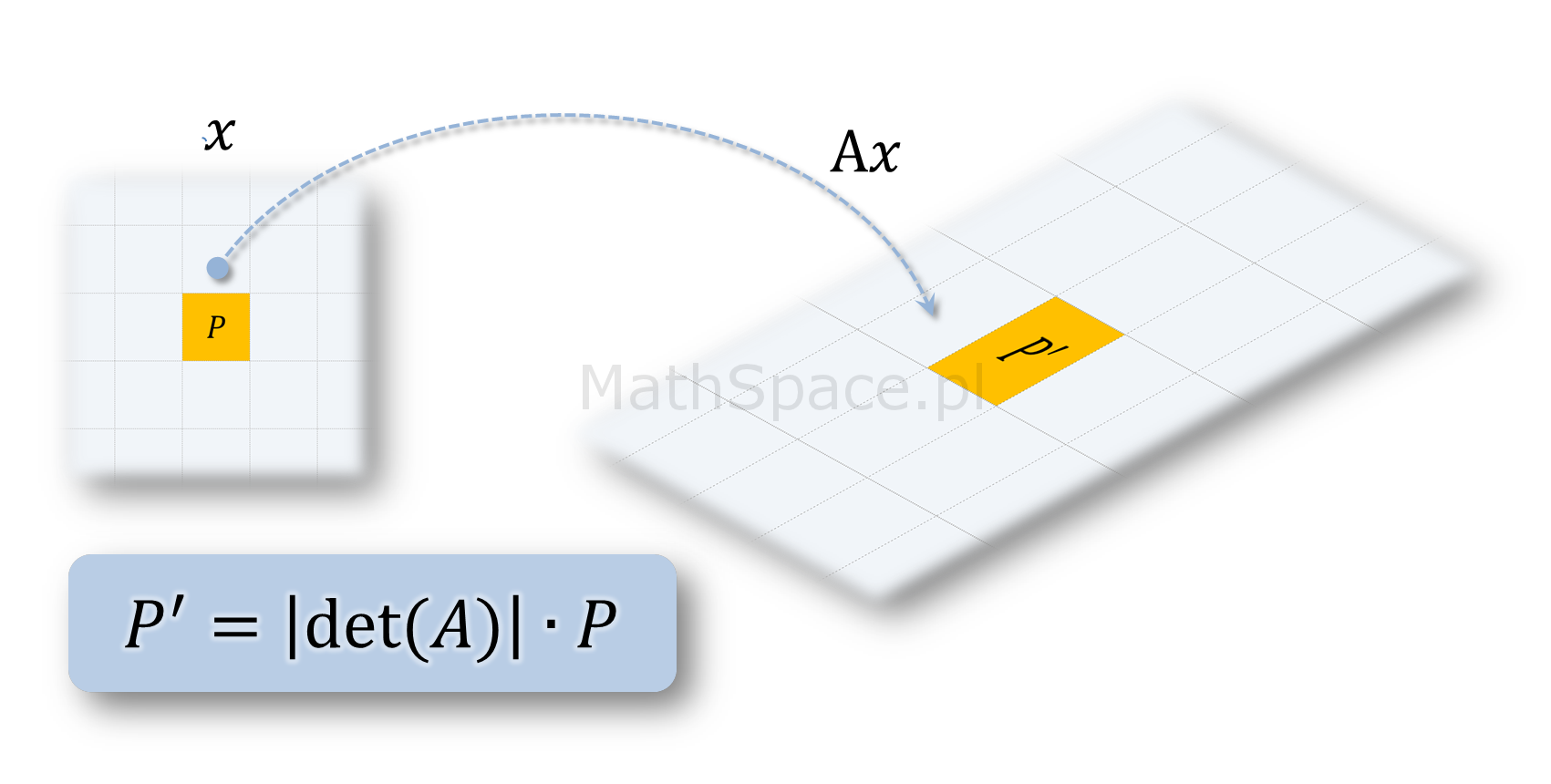
Wyznacznik macierzy przekształcenia liniowego i współczynnik zmiany pola powierzchni
Jeśli analizujemy przekształcenie liniowe
$$Ax$$
gdzie $A$ jest macierzą przekształcenia liniowego, a $x$ wektorem, to wyznacznik
$$\text{det}(A)$$
jest współczynnikiem o jaki zmienia się pole powierzchni / objętość / miara figury / obiektu transformowanego poprzez przekształcenie liniowe $Ax$. Polecam poniższy film.
Wyznacznik macierzy przekształcenia liniowego krzywej ROC w krzywą Captured Response
Z powyższego wynika, że pole powierzchni pomiędzy przestrzenią, w której „osadzona” jest krzywa ROC, a przestrzenią „zawierającą” krzywą Captured Response, powinno się skalować poprzez współczynniki $1-apriori$. Sprawdźmy 🙂
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
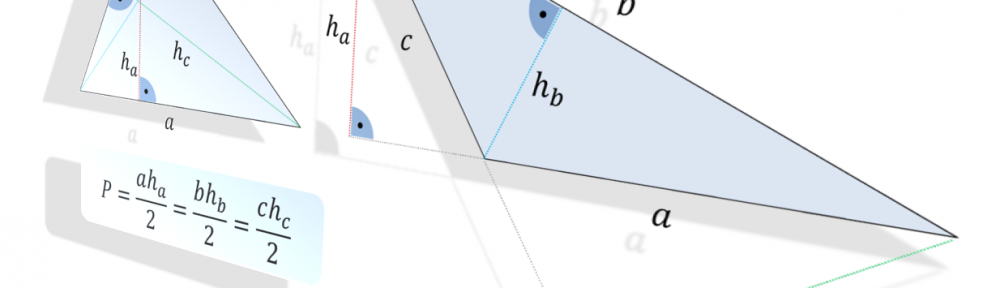
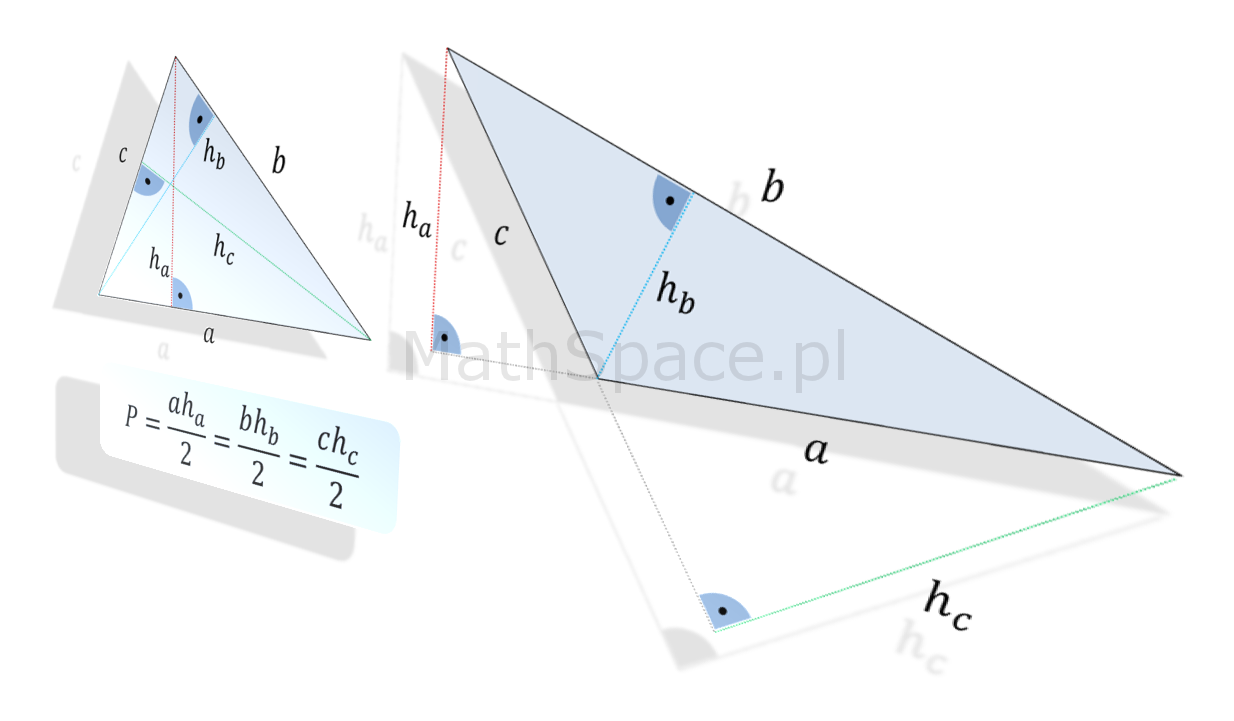
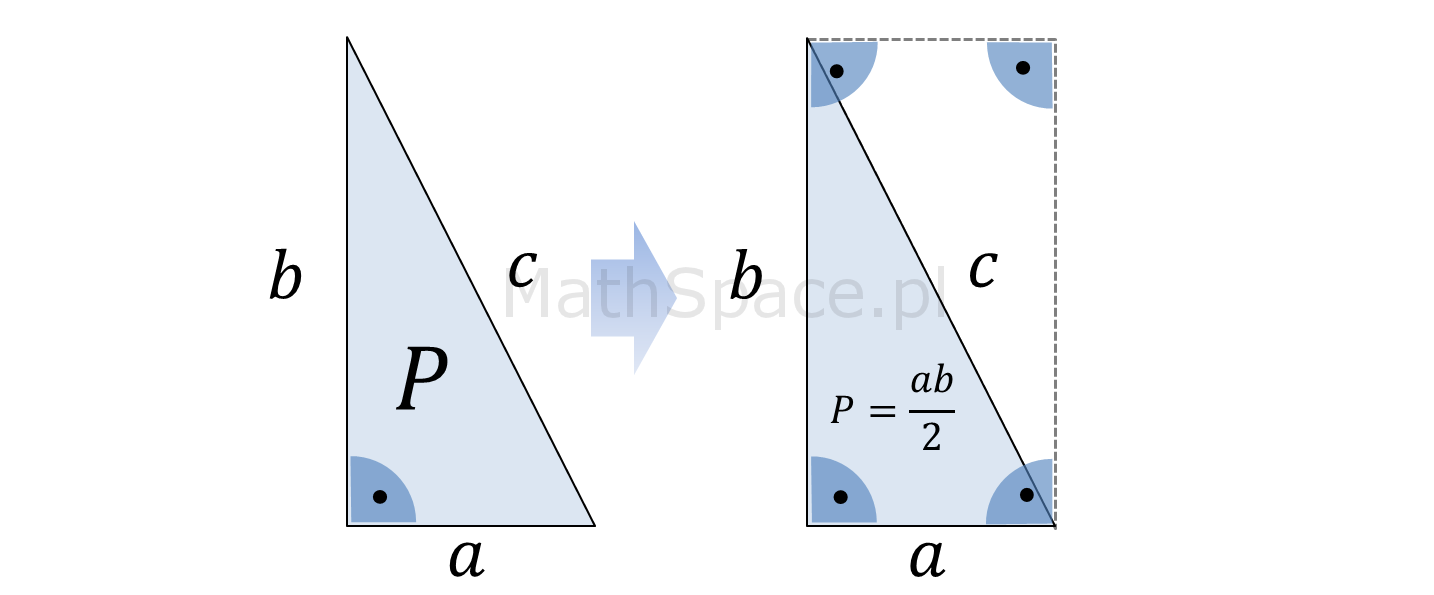
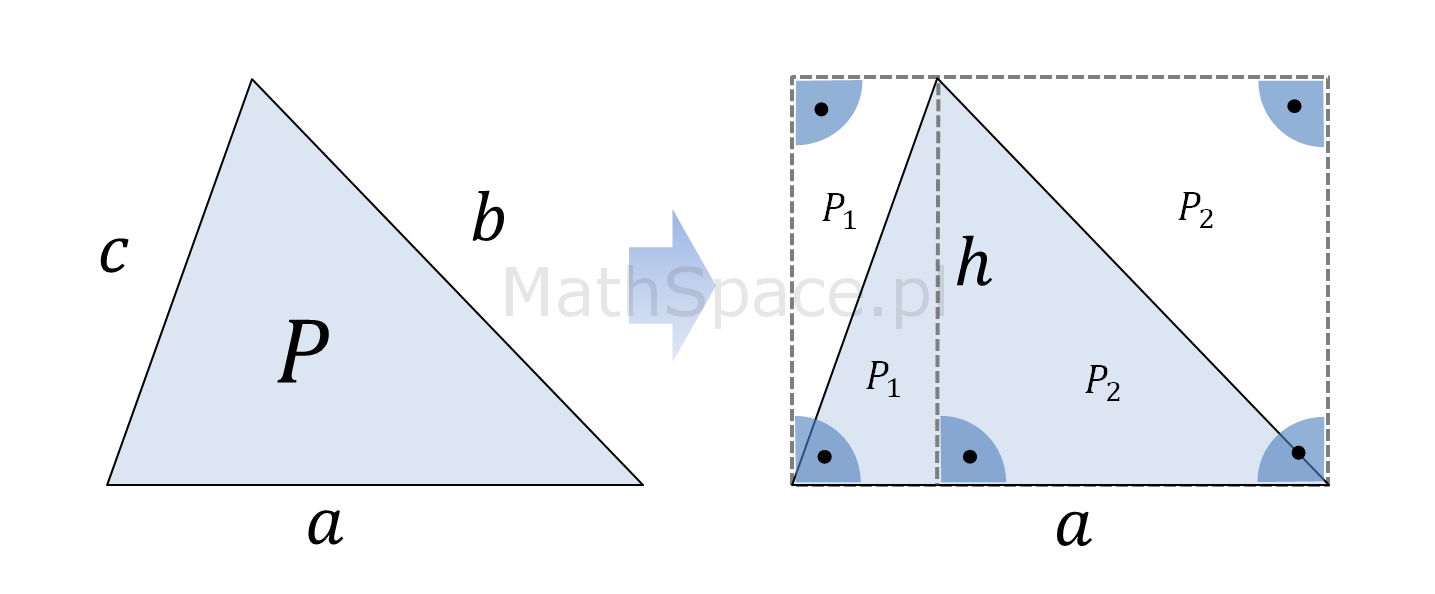
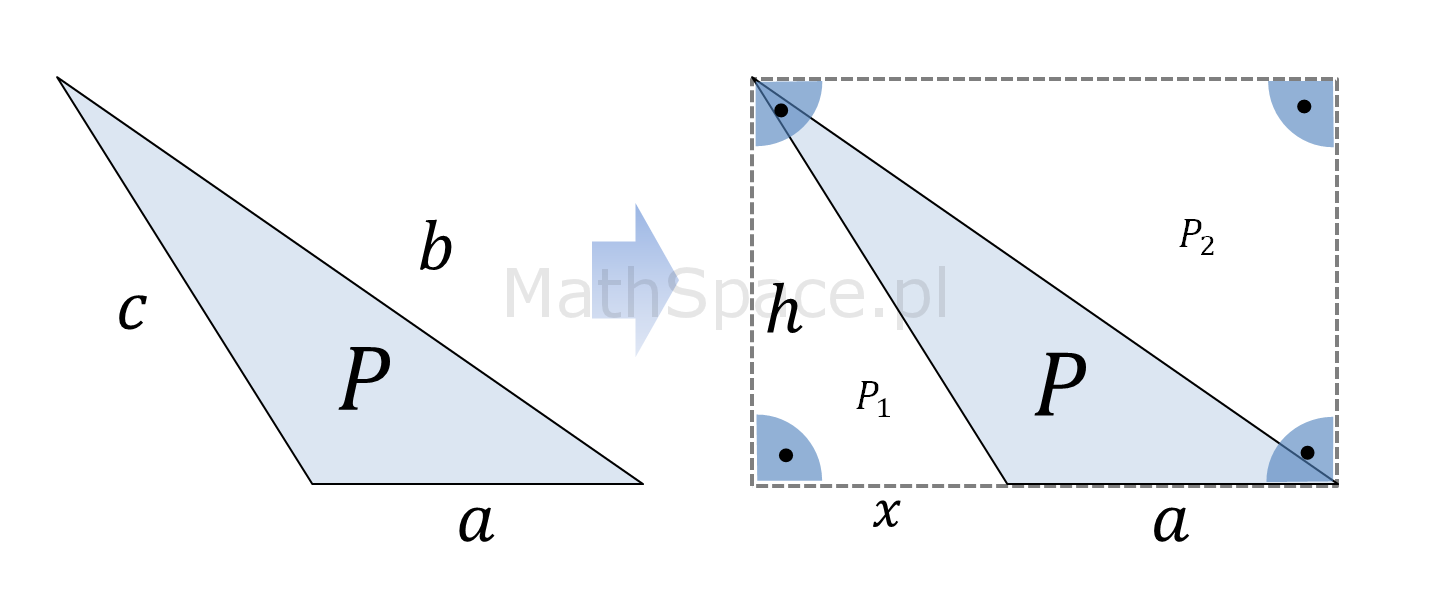
Jestem pewien, że wzór na pole powierzchnitrójkąta, tj. $P=\frac{1}{2}ah$, jest znany niemal wszystkim 🙂 Dzieci, będąc we wczesnym wieku szkolnym, poznają podstawy geometrii, w tym długości obwodów i pola powierzchni figur płaskich. Jeśli interesuje cię dlaczego pole powierzchni trójkąta zależy od długości jego podstawy i wysokości na nią opadającej, to jest to wpis dla Ciebie 🙂 Jednocześnie wzbogacam cykl „Dlaczego?”. Zaczynamy!
Pole powierzchni trójkąta – wzór
Wzór na pole powierzchni trójkąta, choć prosty, to na pierwszy rzut oka nie jest zbyt intuicyjny (no może poza przypadkiem trójkąta prostokątnego). Oto, w jakiś magiczny sposób, dla każdej podstawy, iloczyny ich długości i długości wysokości na nie opadających, są sobie równe – i więcej – określą pole powierzchni ograniczonej trójkątem 🙂
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
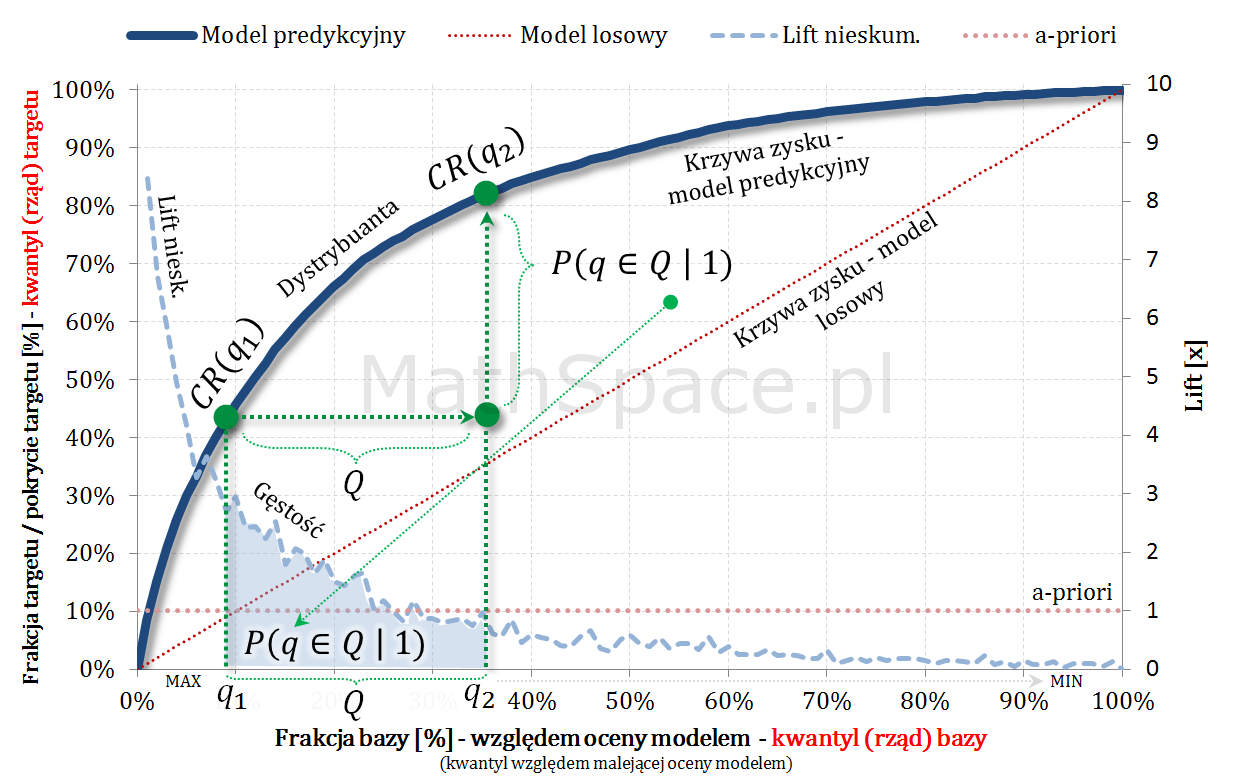
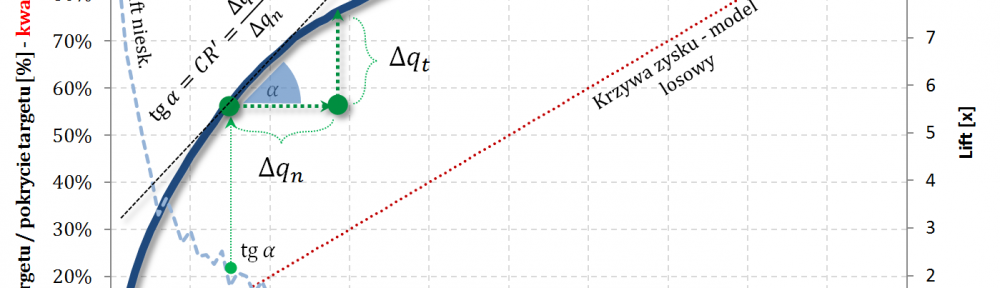
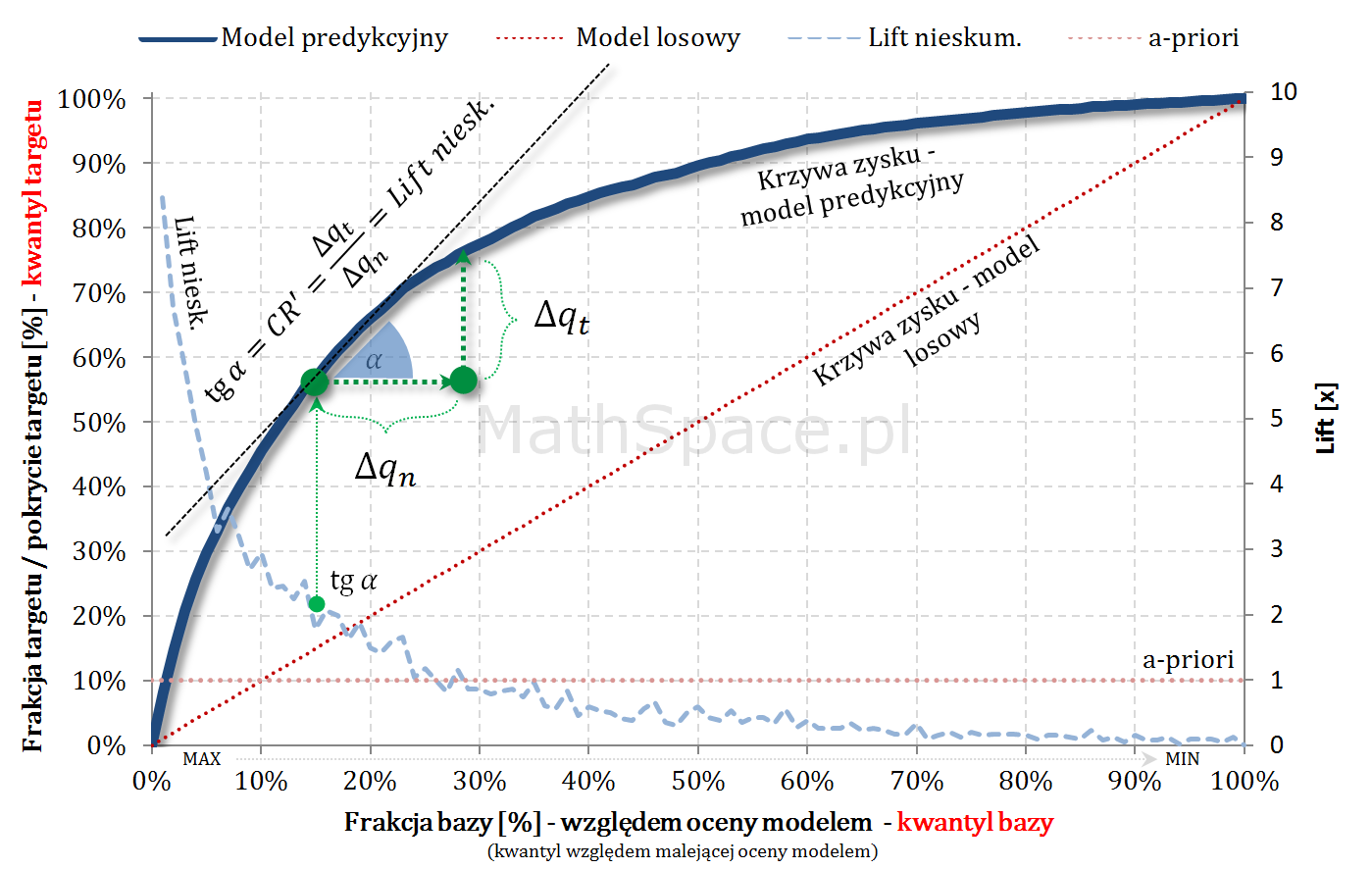
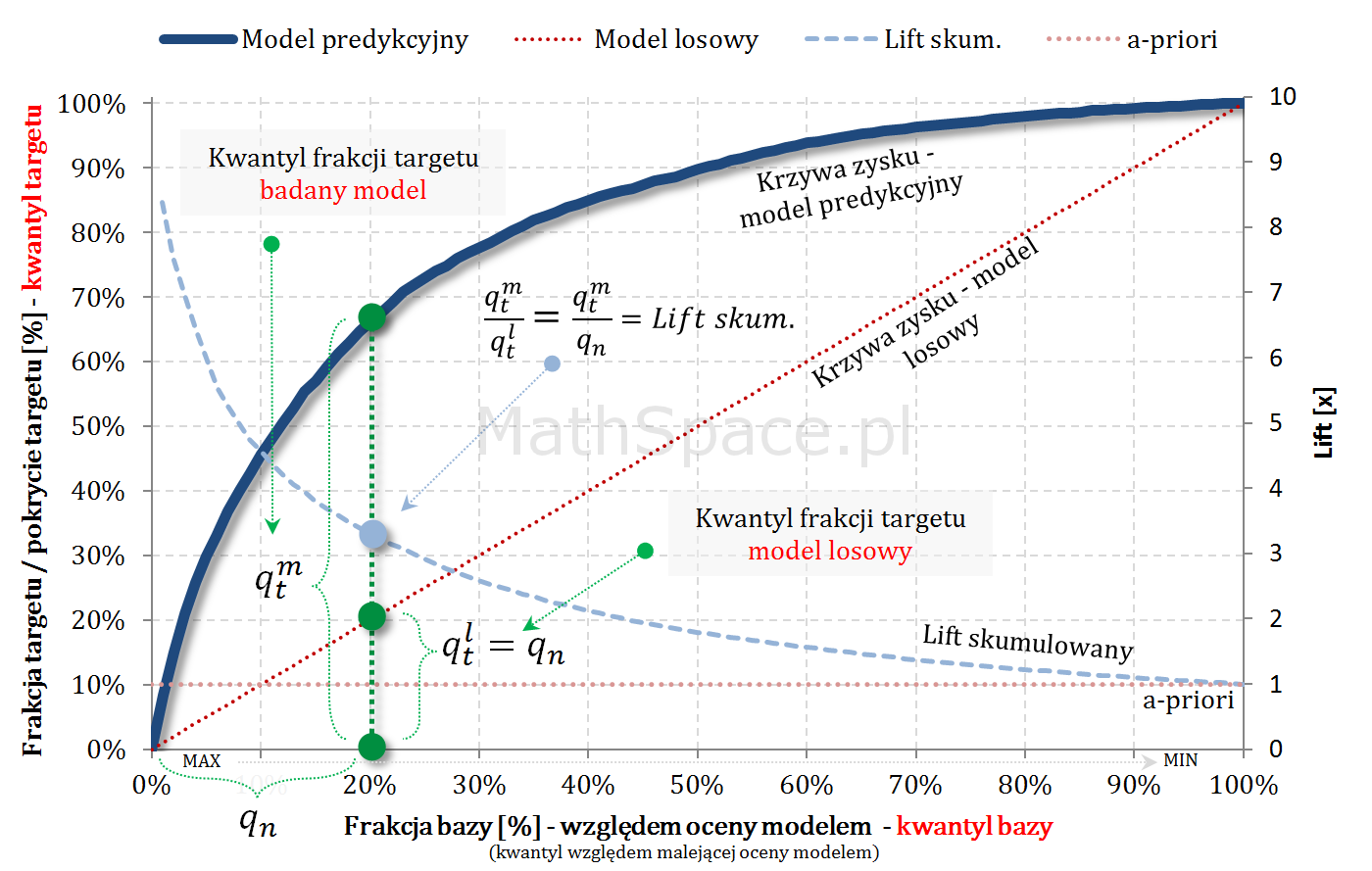
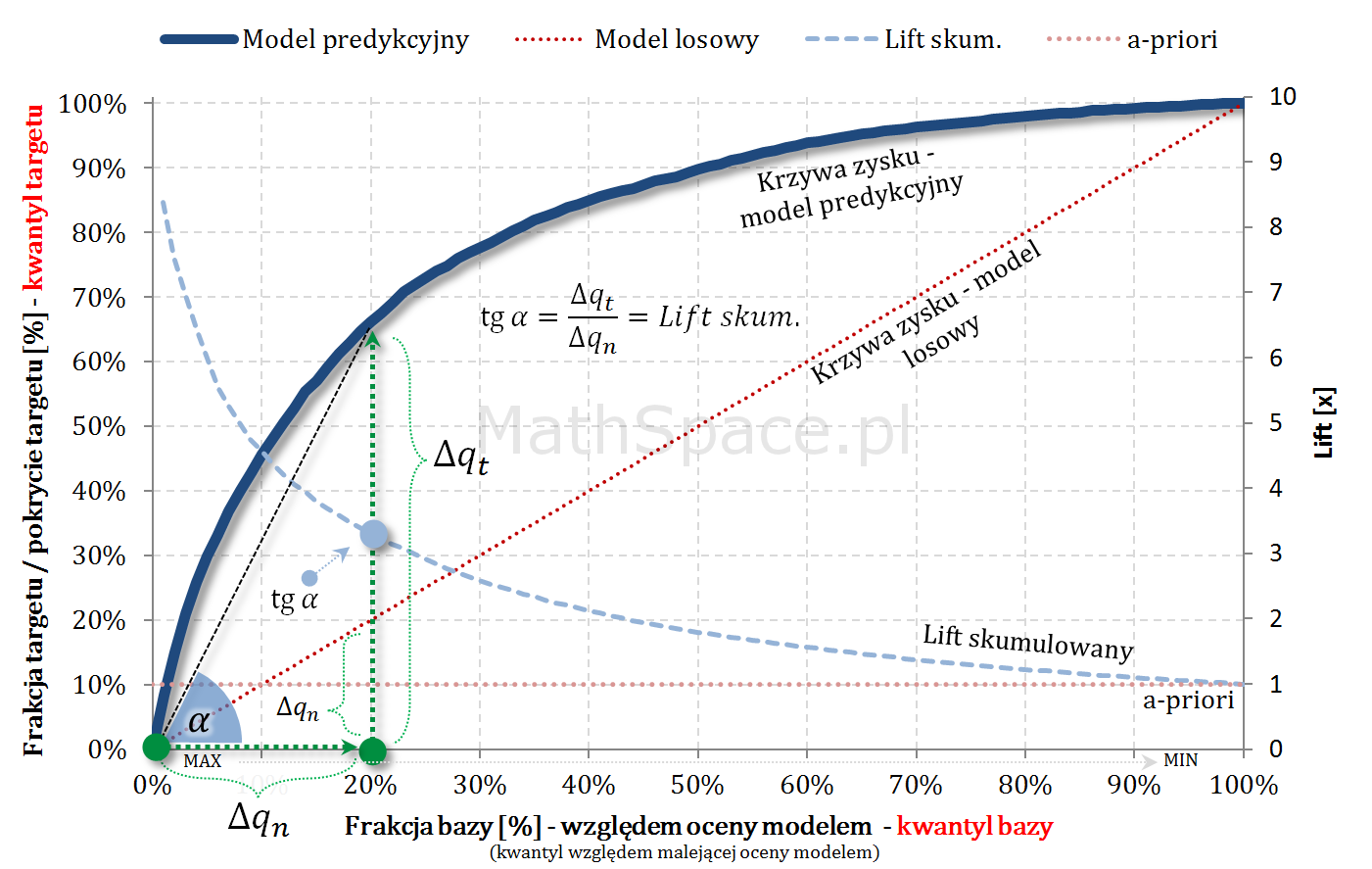
Fajne 🙂 prawda? Lift nieskumulowany można jednoznacznie wyprowadzić z krzywej Captured Response poprzez analizę „lokalnych” przyrostów frakcji bazy $\Delta q_n$ i frakcji targetu $\Delta q_t$.
Captured Response – stosunek wartości dla badanego modelu oraz wartości dla modelu losowego to Lift skumulowany
Oznaczamy:
$N=N_1+N_0$ – liczba obiektów (np. klientów): total, z klasy „1”, z klasy”0″;
$q_n$ – kwantyl bazy, czyli argument na osi poziomej;
$n=n_1+n_0$ – liczba obiektów składających się na kwantyl $q_n$: total, z klasy „1”, z klasy”0″;
$q_t^m$ – kwantyl targetu, czyli wartość Captured Response dla badanego modelu;
$q_t^l$ – kwantyl targetu, czyli wartość Captured Response dla modelu losowego;
Kolejny fajny wniosek 🙂 , który można również łatwo uzasadnić na bazie wyżej opisanej zależności pomiędzy Captured Response i Liftem nieskumulowanym. Mianowicie wystarczy „delty liczyć” od punktu $(0,0)$ i zauważyć, że dla modelu losowego $q_t = q_n$. Pokazałem to na rysunku poniżej.
Lift skumulowany można jednoznacznie wyprowadzić z krzywej Captured Response poprzez analizę „globalnych” przyrostów frakcji bazy $\Delta q_n$ i frakcji targetu $\Delta q_t$.
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
!!! Uwaga: dla uproszczenia – wszędzie tam, gdzie piszę kwantyl, mam na myśli jego rząd !!!
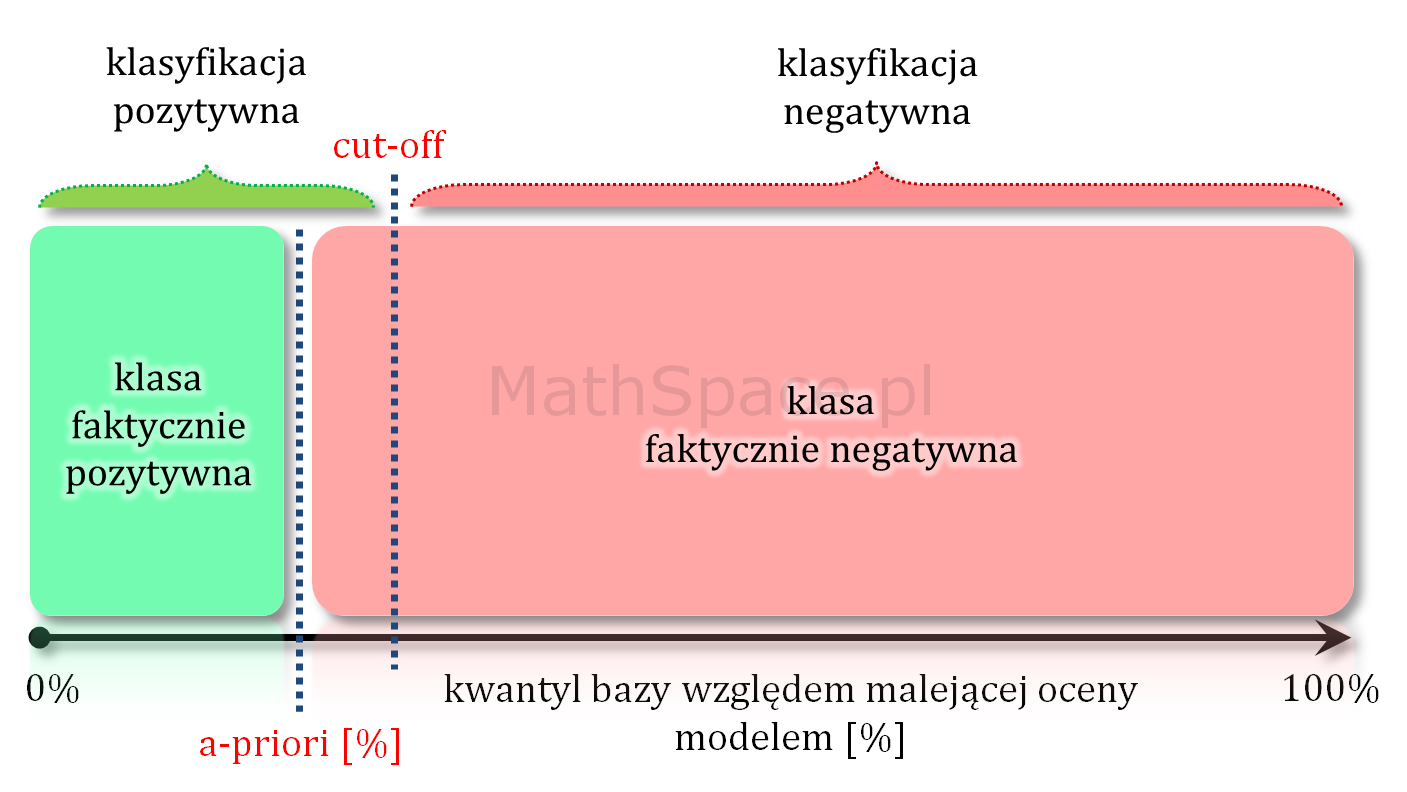
Model teoretycznie idealny a prawdopodobieństwo a-priori
Model teoretycznie idealny to taki model, który daje najlepsze możliwe uporządkowanie – inaczej mówiąc najlepszą możliwą separację klas. Taki model nie myli się przy założeniu, że punkt odcięcia odpowiada prawdopodobieństwu a-priori. Wtedy faktycznie cała klasa pozytywna jest po jednej stronie, a cała klasa negatywna po drugiej stronie punktu cut-off.
Przy każdym innym cut-off model teoretycznie idealny popełnia mniejszy lub większy błąd.
Ile istnieje różnych modeli teoretycznie idealnych?
Liczba różnych modeli teoretycznie idealnych to funkcja liczności klasy faktycznie pozytywnej i liczności klasy faktycznie negatywnej. Liczba ta będzie iloczynem możliwych permutacji w klasie pozytywnej i możliwych permutacji w klasie negatywnej. Takie modele, z punktu widzenia klasycznej oceny jakości klasyfikacji, są nierozróżnialne (dlatego na wykresach oznaczamy tylko jeden). Sytuacja może się zmienić, jeśli, w celu lepszego uporządkowania, rozważymy dodatkowe cechy (oprócz samej przynależności do badanej klasy), takie jak: wartość klienta, oczekiwany life-time, etc…
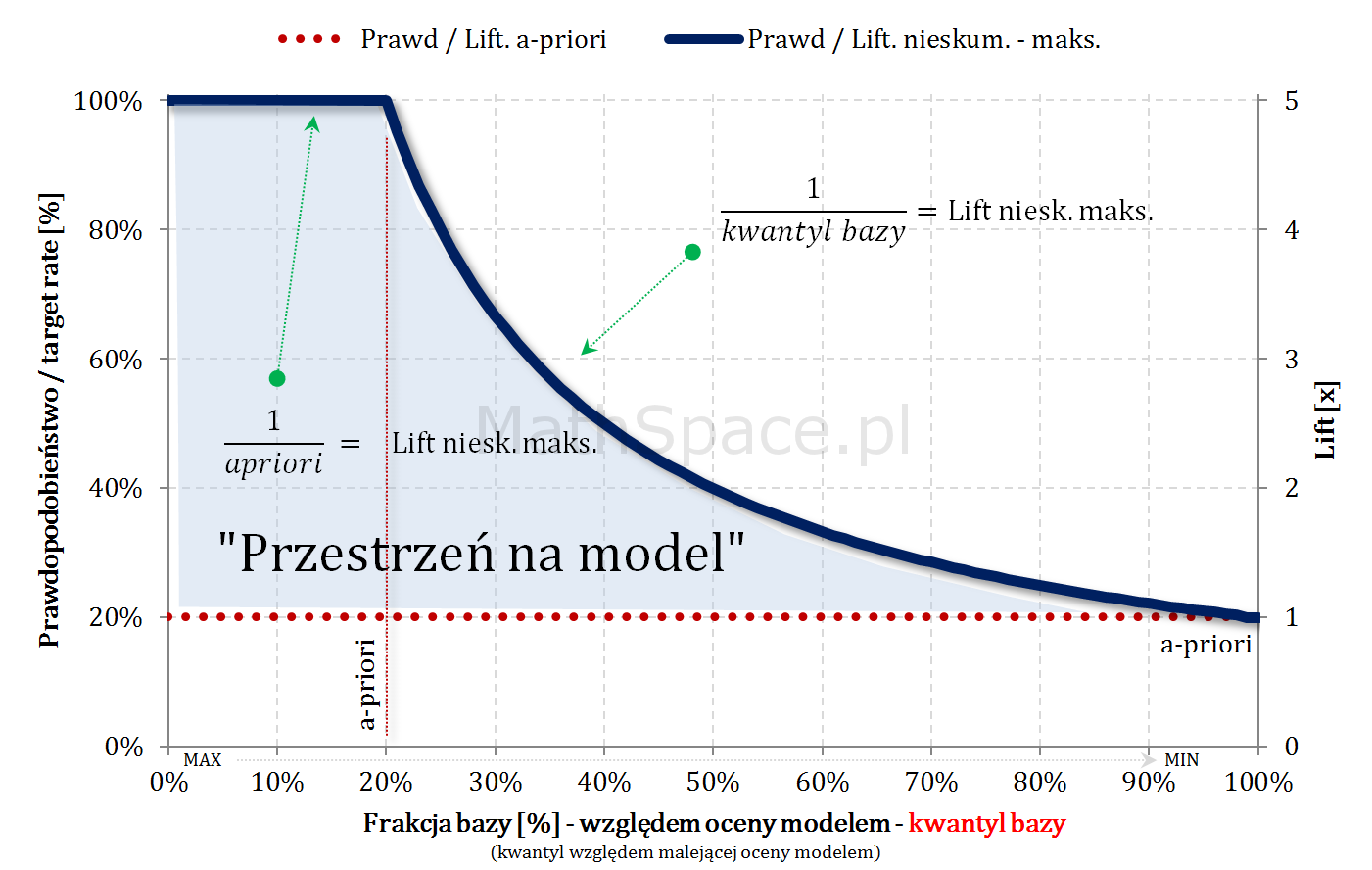
Model teoretycznie idealny i maksymalny Lift nieskumulowany
Lift nieskumulowany to stosunek prawdopodobieństwa w przedziale bazy $\Delta q_n$ i prawdopodobieństwa a-priori (w całej bazie).
$$Lift.Nieskum=\frac{p(1|\Delta n)}{p(1)}$$
Jeśli baza jest uszeregowana malejąco względem oceny modelem, maksymalny możliwy lift nieskumulowany będzie funkcją dwuwartościową.
$q$ – kwantyl bazy (malejąco względem oceny modelem)
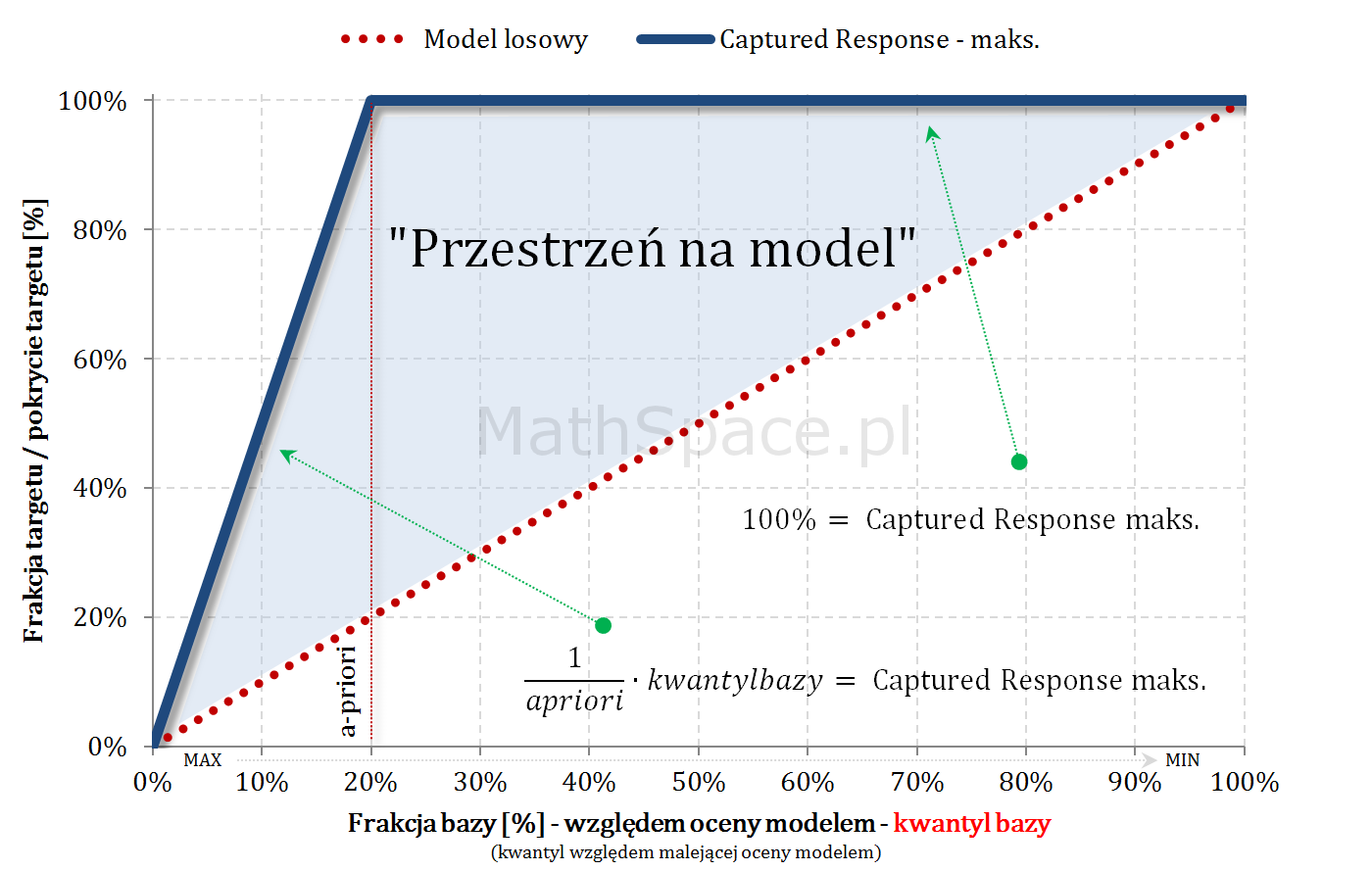
Model teoretycznie idealny i maksymalny Lift skumulowany
Również w przypadku skumulowanym, będąc „na lewo od a-priori”, maksymalny możliwy lift skumulowany wynosi $\frac{1}{apriori}$ (cały czas mamy do dyspozycji „1-dynki”). Jeśli „cut-off przekroczy kwantyl a-priori”, klasyfikacja pozytywna zaczyna być „zaśmiecana” frakcją False-Positive, gdyż nie ma już „1-dynek” – co wynika z najlepszego możliwego porządku (model teoretycznie idealny) – tzn. wszystkie obiekty z klasy faktycznie pozytywnej znajdują się w kwantylach z przedziału $[0,apriori$$.
Model teoretycznie idealny i maksymalny Captured Response
Dysponując najlepszym możliwym uporządkowaniem krzywa Captured Response liniowo rośnie dla argumentów „na lewo” od apriori – każdy dodany obiekt, to klasa faktycznie pozytywna. W punkcie „apriori” całość targetu jest już pokryta – zatem wartość krzywej to 100%.
$q$ – kwantyl bazy (malejąco względem oceny modelem)
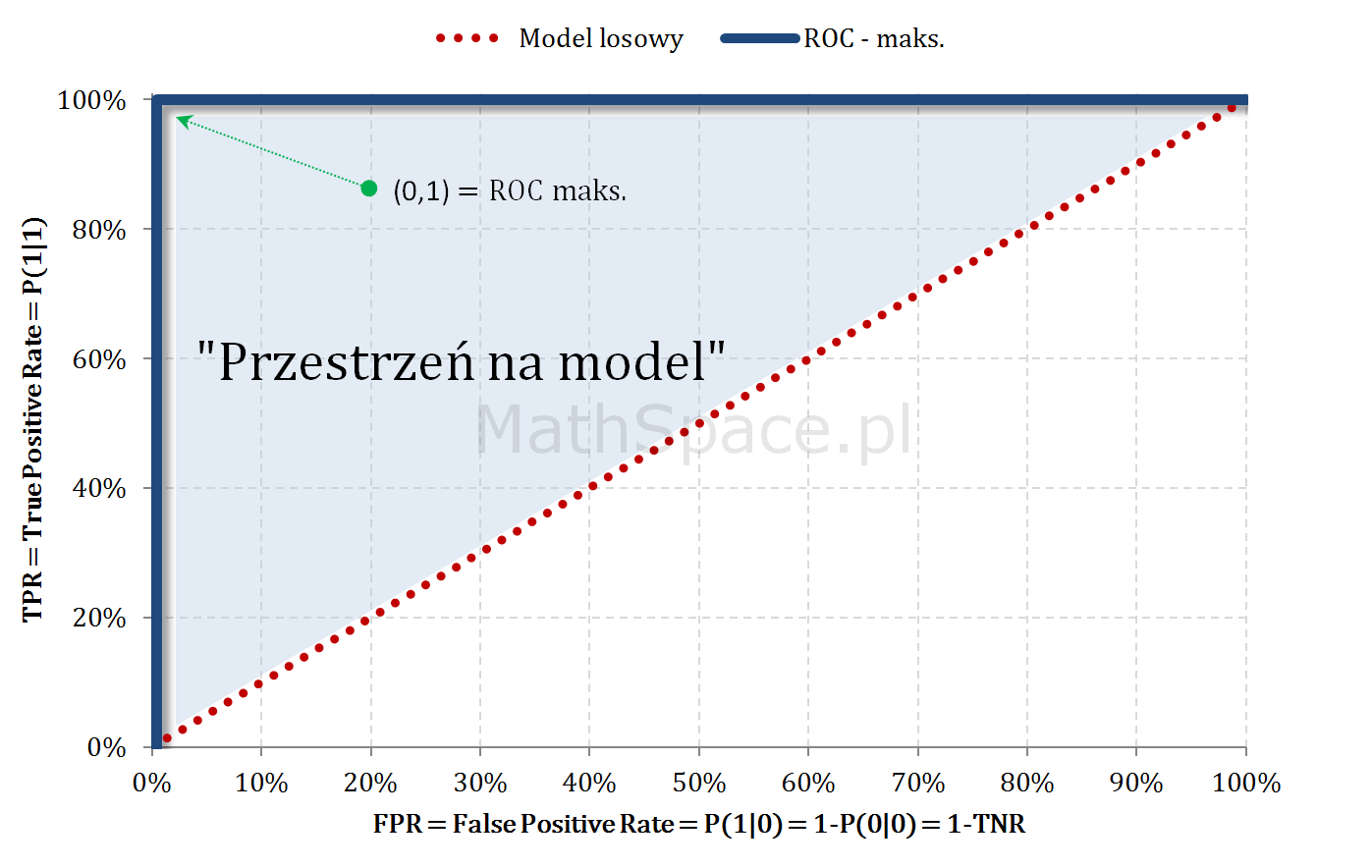
Model teoretycznie idealny i ROC
Jeśli cut-off jest „na lewo” od a-priori: pokrywamy wyłącznie elementy klasy faktycznie pozytywnej, zatem rośnie wyłącznie TPR, przy zerowym FPR.
Dla cut-off odpowiadającego a-priori: pokryto 100% klasy faktycznie pozytywnej (TPR = 100%), jednocześnie nie popełniając żadnego błędu (FPR = 0%).
Dla cut-off większego od a-priori: TPR już wcześniej osiągnęło 100%, teraz klasyfikując pozytywnie popełniamy coraz większy błąd – tzn. FPR zaczyna rosnąć.
Dla cut-off = 1: pokryliśmy całość klasy faktycznie pozytywnej (TPR=100%), jednak w tym samym kroku wszelkie obiekty faktycznie negatywne zaliczyliśmy do klasy pozytywnej (FPR=100%).
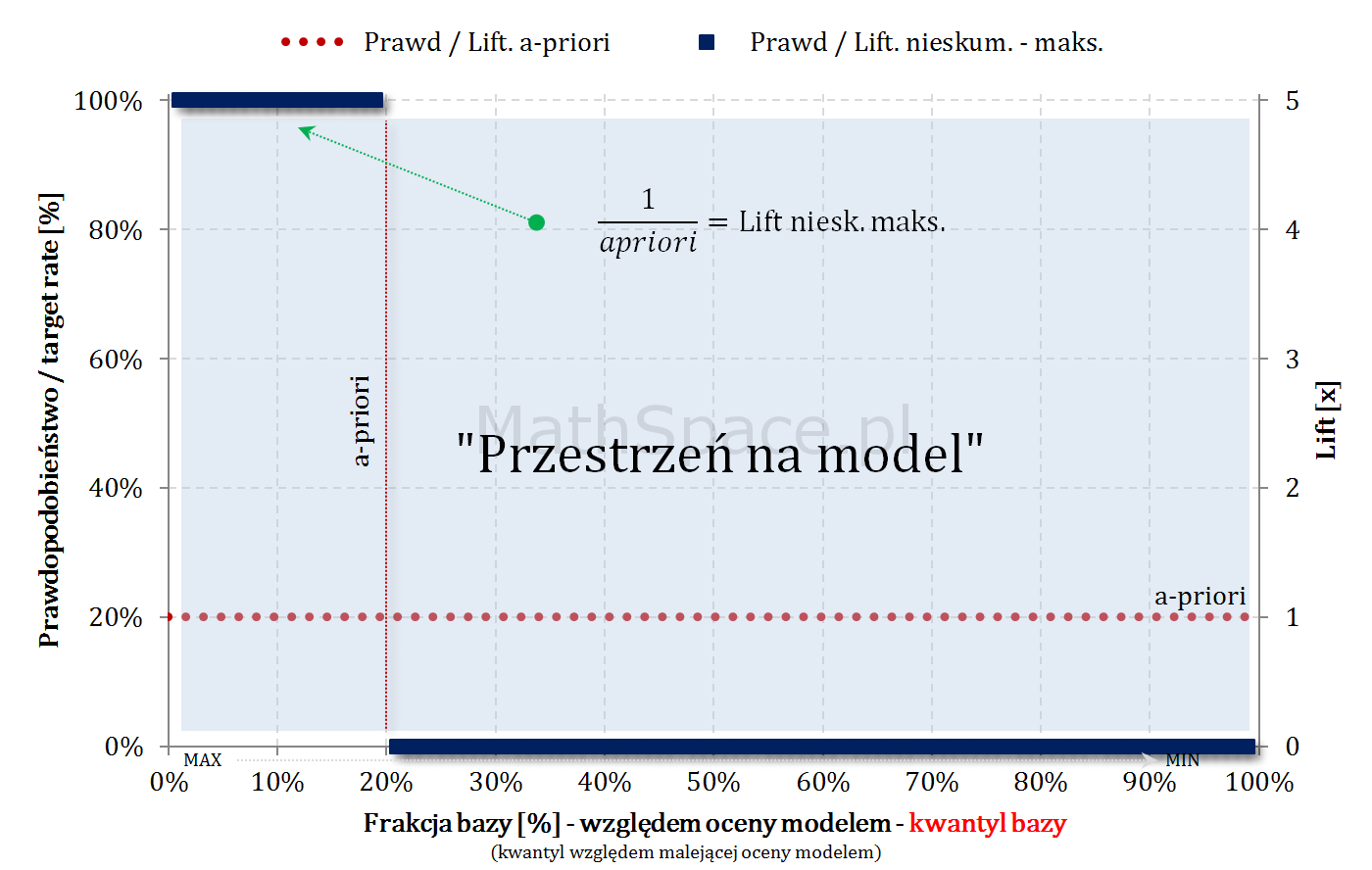
„Przestrzeń na model” – czyli sens budowy modelu
Dla dużych a-priori (np. 50-60%) przestrzeń na model (tzn. możliwy do osiągnięcia lift) jest bardzo mała. W takich sytuacjach należy najpierw zadać sobie pytanie co chcemy osiągnąć, czym jest target, czy nie istnieją proste reguły biznesowe odpowiadające naszym potrzebom? Duże a-priori nie jest przypadkiem abstrakcyjnym – szereg pytań dotyczy cech / zdarzeń bardzo częstych w bazach / populacjach, np: czy rodzina ma dziecko?, czy ktoś posiada samochód?, etc..
Małe a-priori (np. kilka promili) daje bardzo dużą przestrzeń na model (typowo duży osiągany lift), ale należy pamiętać, że 5 razy 0 daje 0!! Przykładowa kalkulacja:
a-priori = 0.5%
lift (na którymś niskim centylu) = 10
wtedy prawdopodobieństwo targetu na bazie klasyfikowanej pozytywnie = 0.5% * 10 = 5%
wtedy w 95% przypadkach mylimy się – owszem możemy pokryć sporą część targetu, ale sami sobie odpowiedzcie czy nieprawidłowy komunikat do 95% grupy ma sens?
Pośrednie a-priori (kilka – kilkanaście procent) – sytuacja optymalna 🙂
Pozdrowienia,
Mariusz Gromada
Poza Liczbami: Inne Twórcze Przestrzenie
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury
Matematyka i muzyka są ściśle powiązane przez rytm, harmonię i struktury, które wykorzystują matematyczne wzory i proporcje do tworzenia estetycznych i emocjonalnych doznań. Z nieśmiałą ekscytacją przedstawiam moją pierwszą poważniejszą kompozycję, w której starałem się uchwycić te połączenia.
Scalar – zaawansowana aplikacja mobilna z silnikiem matematycznym mojego autorstwa
Zarządzaj zgodą
Aby zapewnić jak najlepsze wrażenia, korzystamy z technologii, takich jak pliki cookie, do przechowywania i/lub uzyskiwania dostępu do informacji o urządzeniu. Zgoda na te technologie pozwoli nam przetwarzać dane, takie jak zachowanie podczas przeglądania lub unikalne identyfikatory na tej stronie. Brak wyrażenia zgody lub wycofanie zgody może niekorzystnie wpłynąć na niektóre cechy i funkcje.
Funkcjonalne
Zawsze aktywne
Przechowywanie lub dostęp do danych technicznych jest ściśle konieczny do uzasadnionego celu umożliwienia korzystania z konkretnej usługi wyraźnie żądanej przez subskrybenta lub użytkownika, lub wyłącznie w celu przeprowadzenia transmisji komunikatu przez sieć łączności elektronicznej.
Preferencje
Przechowywanie lub dostęp techniczny jest niezbędny do uzasadnionego celu przechowywania preferencji, o które nie prosi subskrybent lub użytkownik.
Statystyka
Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do celów statystycznych.Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do anonimowych celów statystycznych. Bez wezwania do sądu, dobrowolnego podporządkowania się dostawcy usług internetowych lub dodatkowych zapisów od strony trzeciej, informacje przechowywane lub pobierane wyłącznie w tym celu zwykle nie mogą być wykorzystywane do identyfikacji użytkownika.
Marketing
Przechowywanie lub dostęp techniczny jest wymagany do tworzenia profili użytkowników w celu wysyłania reklam lub śledzenia użytkownika na stronie internetowej lub na kilku stronach internetowych w podobnych celach marketingowych.
Cześć, z tej strony Mariusz Gromada, autor bloga MathSpace.pl.
Znacie mnie z tekstów o nauce i matematyce. Równolegle – od ponad 20 lat – zajmuję się projektowaniem, wdrażaniem oraz wykorzystywaniem wielkoskalowych systemów personalizacji w organizacjach B2C. Tę podwójną perspektywę – analityczno-inżynierską i biznesową – zebrałem w mojej najnowszej książce:
„Customer First, Value Next: The Executive Playbook for AI-Driven Omnichannel Personalization and Customer-Centric Growth.”
Jeśli jesteś liderem biznesowym, liderem technologicznym, inżynierem, analitykiem lub po prostu fascynuje Cię budowa skalowalnych systemów AI, które potrafią zrozumieć klienta – odchodząc od tradycyjnego modelu produktowego – to ta pozycja jest dla Ciebie.
„Technologia to nie tylko narzędzie do automatyzacji. To megafon dla empatii.”